


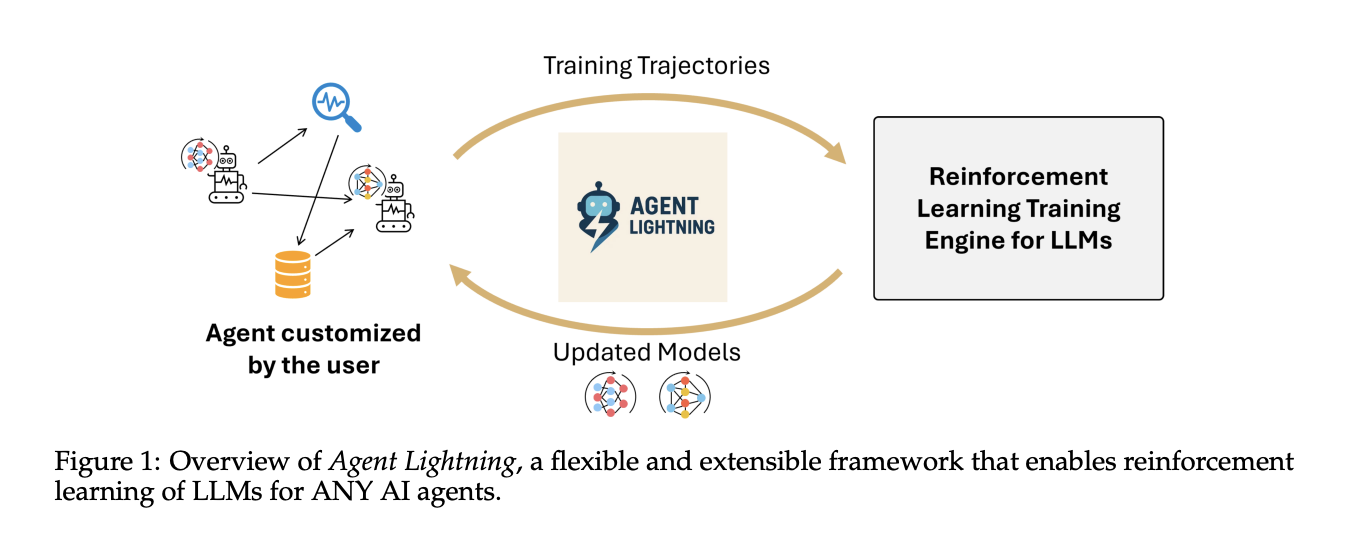
How can I enhance my coverage LLM by changing actual agent traces into reinforcement studying RL transitions with out altering my current agent stack? Microsoft AI Workforce Launch agent lightning Helps optimize multi-agent methods. Agent Lightning is an open supply framework that brings reinforcement studying to work for any AI agent with none rewrites. We introduce LightningRL, a hierarchical technique that separates coaching from execution, defines a unified hint format, and transforms advanced agent executions into transitions that may be optimized by commonplace single-turn RL trainers.
What Agent Lightning does?
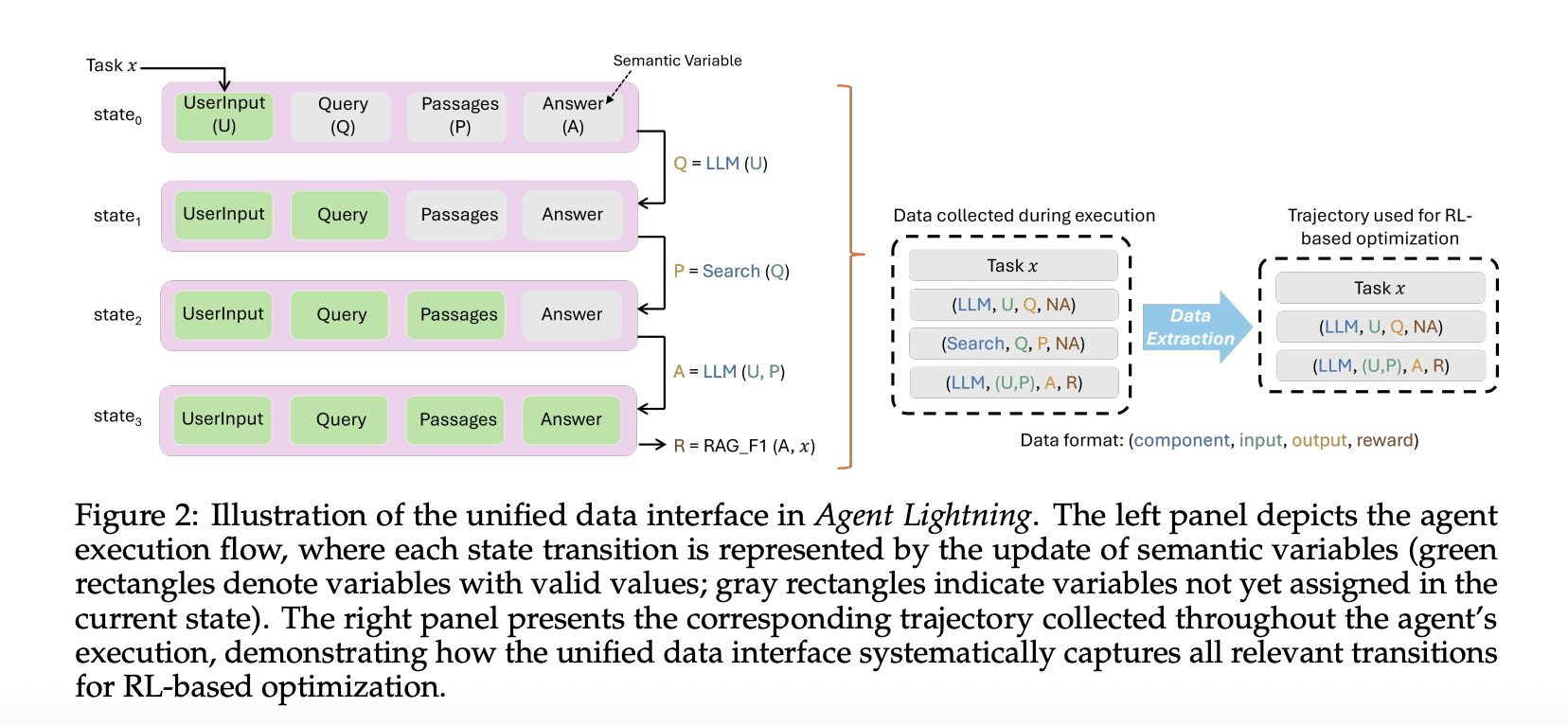
This framework fashions the agent as a decision-making course of. This formalizes the agent as {a partially} observable Markov choice course of. Right here, the statement is the present enter to the coverage LLM, the motion is the mannequin name, and the reward could also be remaining or intermediate. From every run, solely the calls made by the coverage mannequin are extracted, together with inputs, outputs, and rewards. This removes noise from different frameworks and provides you clear transitions for coaching.
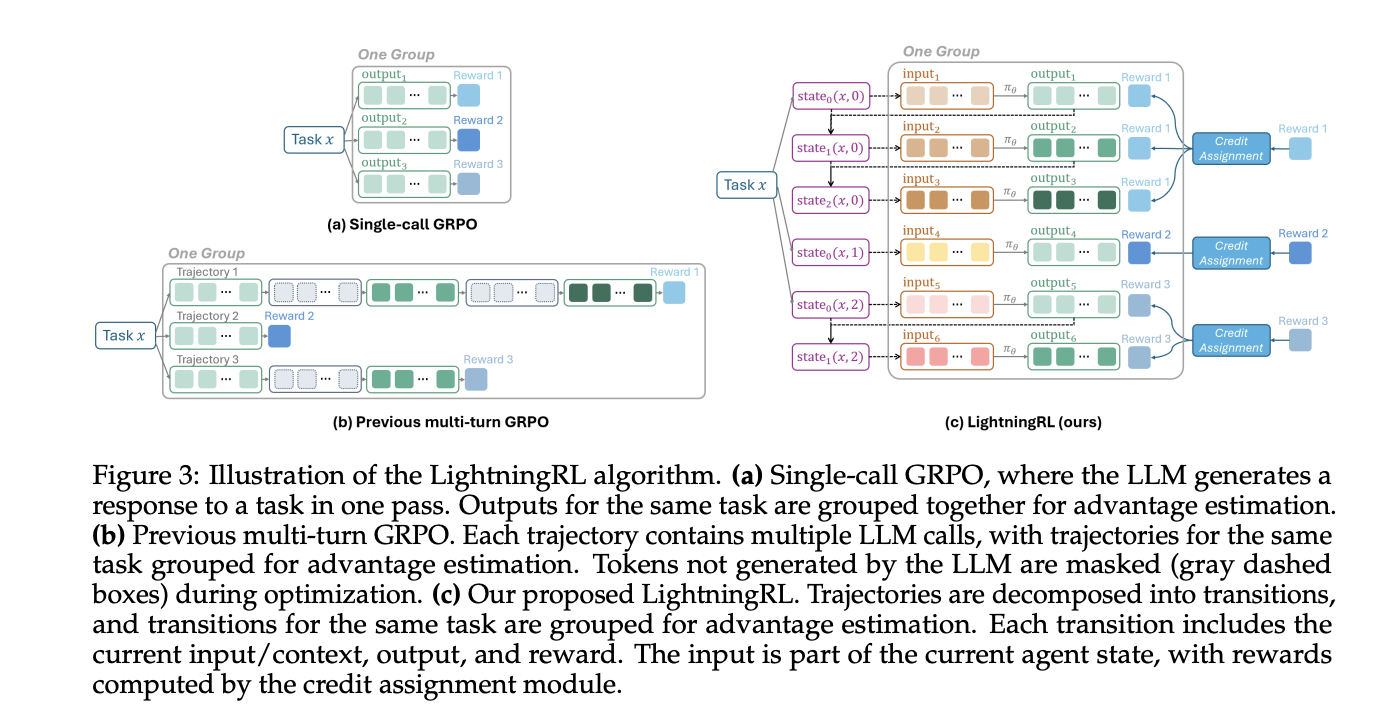
LightningRL performs credit score allocation over multi-step episodes and optimizes insurance policies with single-turn RL targets. The analysis crew describes compatibility with single-turn RL strategies. In actual fact, groups usually use trainers that implement PPO or GRPO, reminiscent of VeRL, that match this interface.
system structure
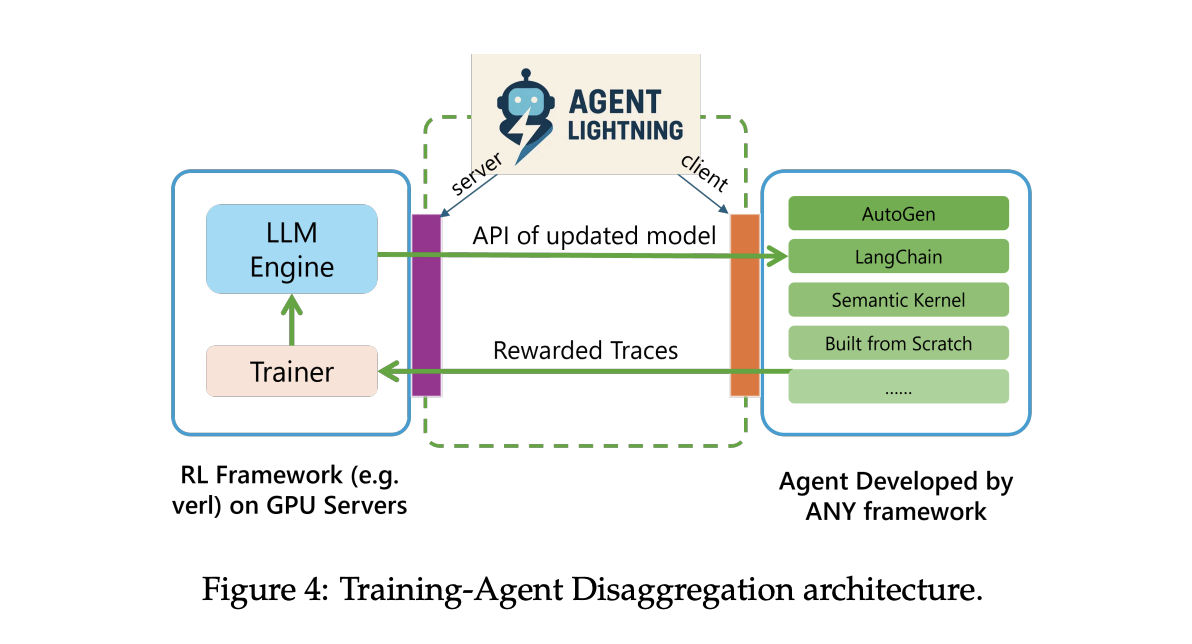
Agent Lightning makes use of coaching agent decomposition. Lightning Server runs coaching and companies and exposes APIs like OpenAI for up to date fashions. The Lightning shopper runs the agent runtime that already exists, captures traces of prompts, instrument calls, and rewards, and streams them again to the server. This retains instruments, browsers, shells, and different dependencies near manufacturing whereas GPU coaching stays on the server tier.
The runtime helps two hint paths. The default path makes use of OpenTelemetry spans, so you’ll be able to pipe agent telemetry by way of commonplace collectors. There may be additionally a light-weight built-in tracer for groups who do not need to deploy OpenTelemetry. Each paths find yourself being educated in the identical retailer.
Built-in knowledge interface
Agent Lightning data every mannequin name and every instrument name as a span that features inputs, outputs, and metadata. The algorithm layer adapts the span to 3 ordered parts: immediate, response, and reward. This selective extraction lets you optimize a single agent in a multi-agent workflow, or a number of brokers without delay, with out touching your orchestration code. The identical hint additionally lets you carry out computerized immediate optimization and supervised fine-tuning.
Experiments and datasets
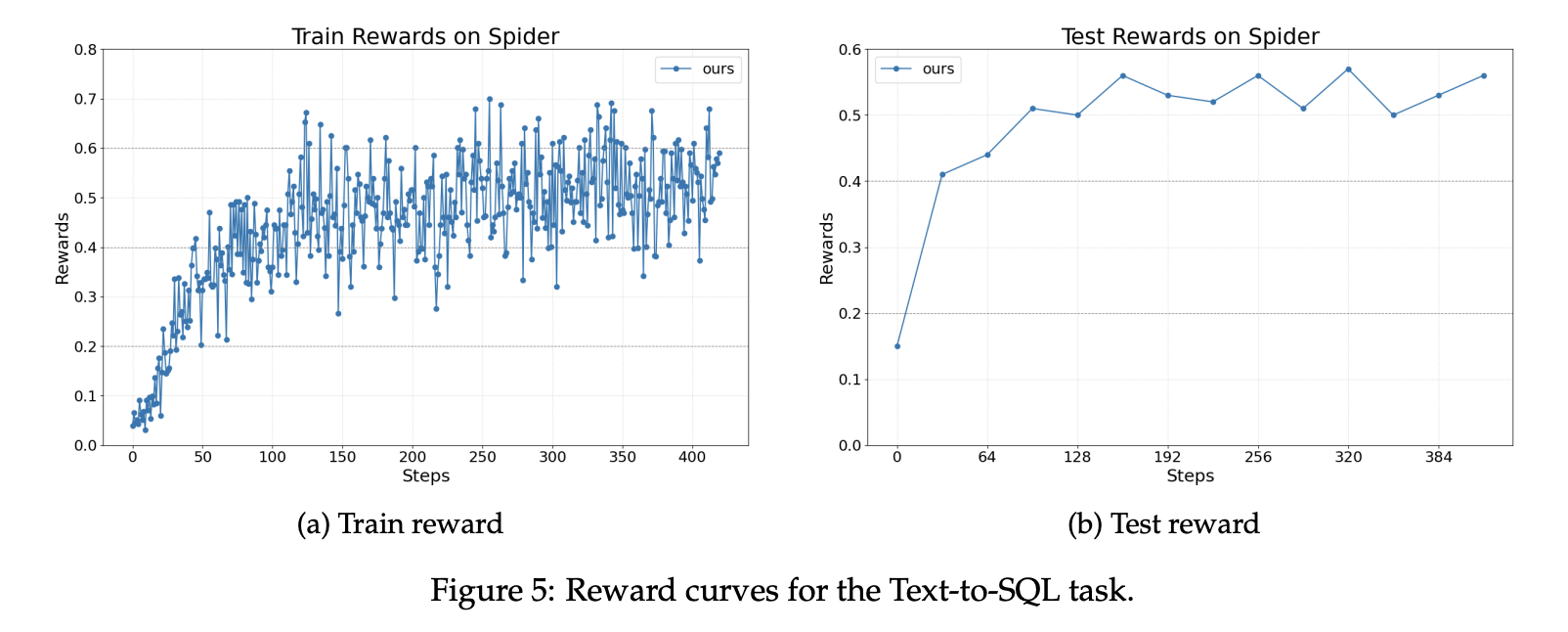
The analysis crew experiences three points. For textual content to SQL, the crew makes use of the Spider benchmark. Spider contains over 10,000 questions throughout 200 databases throughout 138 domains. The coverage mannequin is Llama 3.2 3B directions. This implementation makes use of LangChain together with a author agent, rewriter agent, and checker. Writers and rewriters are optimized and checkers stay mounted. Rewards improve steadily throughout coaching and testing.
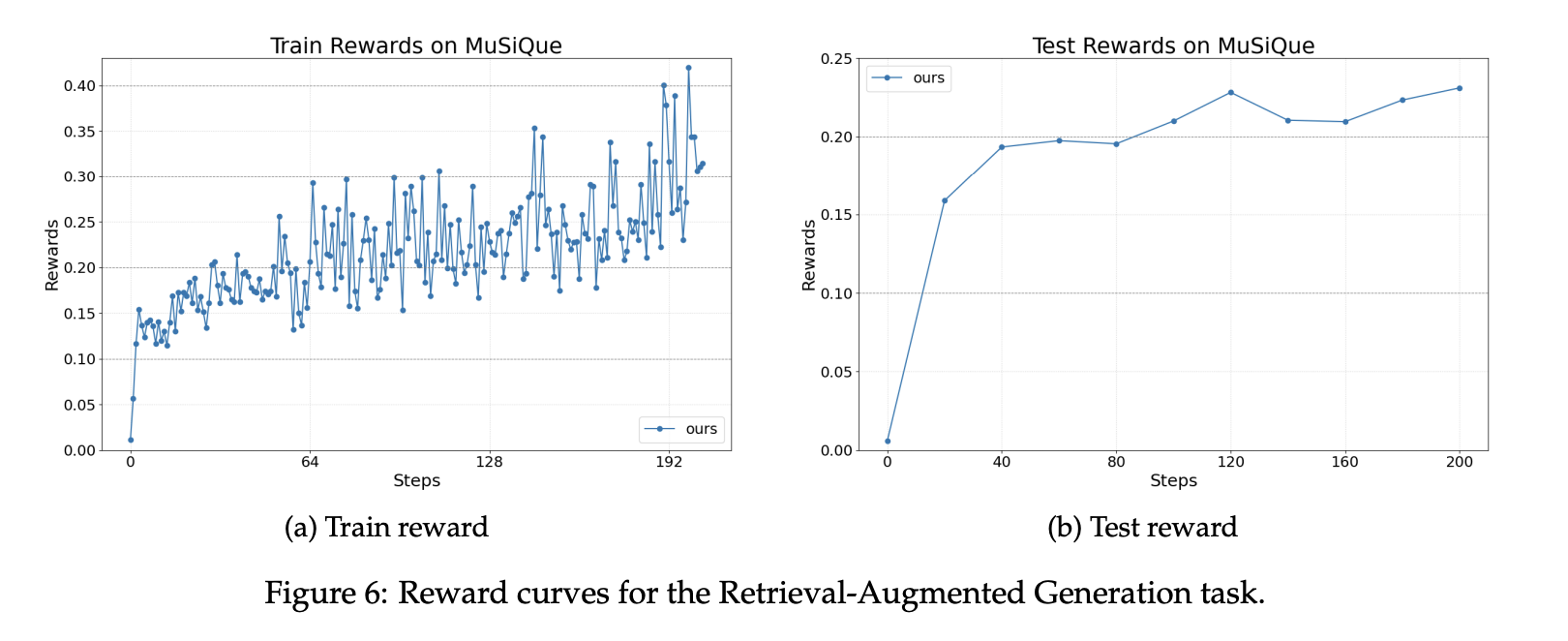
For search growth era, our setup makes use of the MuSiQue benchmark and a Wikipedia scale index containing roughly 21 million paperwork. Retriever makes use of a BGE embedding with cosine similarity. Brokers are constructed utilizing the OpenAI Brokers SDK. The reward is a weighted sum of the formatting rating and the F1 accuracy rating. The reward curve reveals secure positive aspects throughout coaching and analysis utilizing the identical base mannequin.
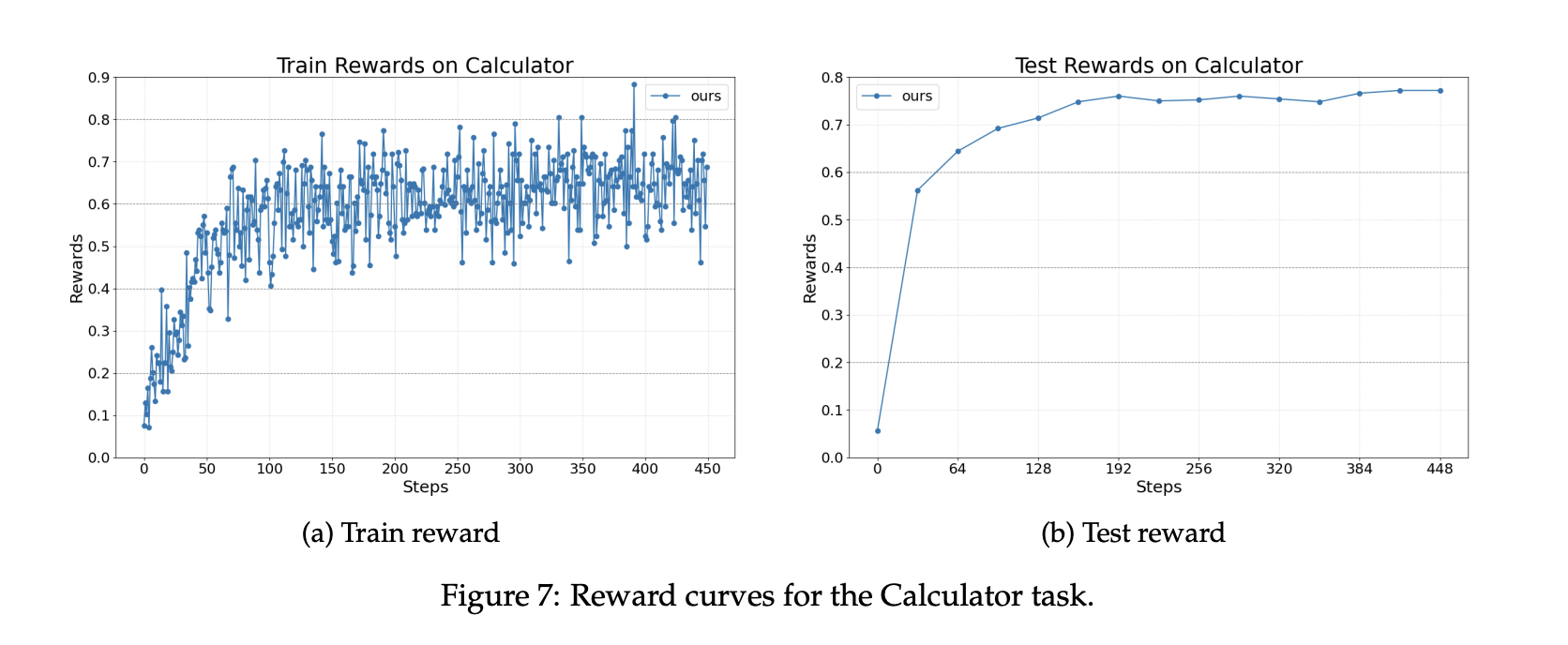
For math query answering utilizing instruments, the agent is carried out in AutoGen and calls the calculation instrument. The dataset is Calc X. The bottom mannequin continues to be Llama 3.2 3B Instruct. Coaching improves your skill to launch instruments appropriately and combine outcomes right into a remaining reply.
Vital factors
- Agent Lightning makes use of Coaching Agent Disaggregation and a unified tracing interface, so current brokers from LangChain, OpenAI Brokers SDK, AutoGen, or CrewAI can join with subsequent to zero code adjustments.
- LightningRL converts trajectories into transitions. Apply credit score allocation to multi-step executions and optimize insurance policies utilizing single-turn RL strategies reminiscent of PPO and GRPO in commonplace trainers.
- Automated Intermediate Rewards (AIR) gives dense suggestions. AIR converts system indicators reminiscent of instrument return standing into intermediate rewards, assuaging the issue of sparse rewards in lengthy workflows.
- This research evaluates the usage of text-to-SQL conversion on Spider, RAG on MuSiQue utilizing a Wikipedia scale index with BGE embedding and cosine similarity, and mathematical instruments on Calc X. All utilizing Llama 3.2 3B Instruct as the bottom mannequin.
- The runtime data traces by way of OpenTelemetry, streams them to the coaching server, and exposes OpenAI-compatible endpoints for up to date fashions, enabling scalable rollouts with out transferring instruments.
Agent Lightning is just not a rewrite of one other framework, however a sensible bridge between agent execution and reinforcement studying. We formalize agent execution as a Markov Resolution Course of (MDP), introduce LightningRL for credit score task, and extract transitions which can be constructed right into a single-turn RL coach. The decoupled design of the coaching agent separates the shopper that runs the agent from the server that trains and serves OpenAI-compatible endpoints, so groups preserve their current stack. Automated intermediate rewards remodel runtime indicators into dense suggestions, decreasing sparse rewards in lengthy workflows. Total, Agent Lightning is a clear, minimal integration path that permits brokers to be taught from their very own traces.
Please test paper and lipo. Please be at liberty to test it out GitHub page for tutorials, code, and notebooks. Additionally, be at liberty to comply with us Twitter Do not forget to affix us 100,000+ ML subreddits and subscribe our newsletter. cling on! Are you on telegram? You can now also participate by telegram.

Michal Sutter is a knowledge science skilled with a grasp’s diploma in knowledge science from the College of Padova. With a robust basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at remodeling advanced datasets into actionable insights.

{kind=link}