


Researchers at Cornell and Google will introduce an built-in regression language mannequin (RLM) that predicts numerical outcomes straight from code strings. This covers GPU kernel latency, program reminiscence utilization, and even neural community accuracy and latency. 300m Parameter Encoder Initialized from T5-GEMMA – The decoder makes use of a single text-to-number decoder that emits numbers in constrained decoding to realize robust rank correlation between non-uniform duties and languages.
What precisely is it?
- Metric regression from unified code: One RLM predicts accuracy and hardware-specific latency by (i) studying peak reminiscence from high-level code (e.g. Python/C/C++), (ii) latency of the Triton GPU kernel, and (iii) studying uncooked textual content representations and decoding numeric output. No practical engineering, graph encoder, or zero price proxy is required.
- Particular outcomes: Contains reported correlations Spearman ρ≈0.93 Within the app’s leetcode reminiscence, ρ≈0.52 For Triton kernel latency, ρ> 0.5 common 17 Code Internet Languageand Kendall τ≈0.46 Past 5 basic NAS areas, it’s appropriate with graph-based predictors, and typically exceeds.
- Multipurpose decoding: As a result of the decoder is autorecovery, the mannequin situations are conditioned on metrics from earlier metrics (e.g. accuracy → per-device latency) and seize reasonable trade-offs alongside the Pareto entrance.
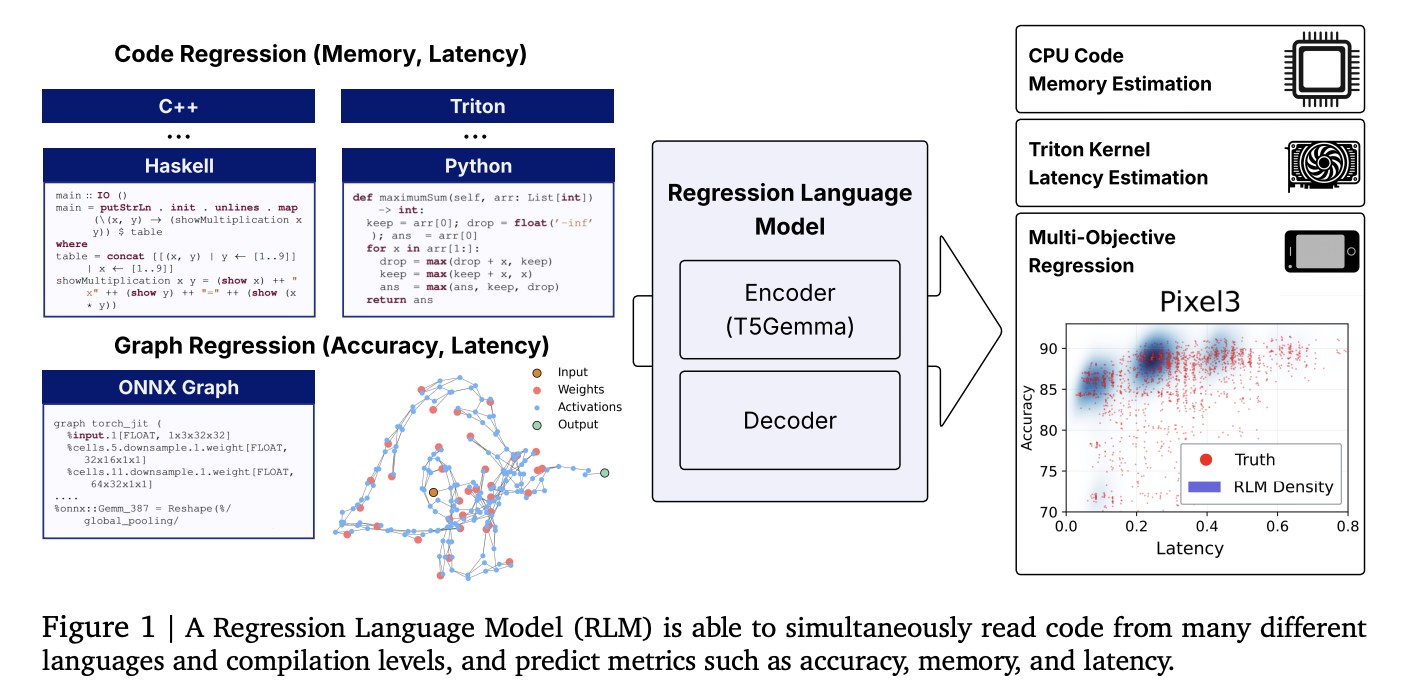
Why is that this essential?
Compilers, GPU kernel selections, and NAS efficiency prediction pipelines are normally weak to new OPS/languages, counting on bespoke options, syntax bushes, or GNN encoders. Regression remedy Predicting the subsequent quantity Standardize the stack: tokenize the enter as plain textual content (supply code, Triton IR, ONNX), then decodes a numeric string calibrated for every digit quantity with constrained sampling. This reduces upkeep prices and improves fine-tuning transfers to new duties.
Knowledge and benchmarks
- Code Restoration Knowledge Set (HF): Curated with help Metrics from code Duties that span apps/LeetCode execution, Triton Kernel Latencies (Kernelbook Derived), and Codenet reminiscence footprints.
- NAS/ONNX Suite: Nasbench-101/201, FBNET, as soon as (MB/PN/RN), TwoPath, Hiaml, Inception, and NDS architectures are exported to onnx textual content Predict accuracy and device-specific delay.
How does it work?
- spine:a T5-gemma Encoder initialization (~300m parameters). Enter is a uncooked string (code or onnx). The output is the quantity emitted as Signal/Index/Mantissa Digit TokenConstrained decoding enforces legitimate numbers and helps uncertainty by way of sampling.
- Ablation: (i) Pre-language deletion accelerates convergence and improves Triton latency prediction. (ii) Numerical emissions solely from decoder Y-Normalization can be superior to the MSE regression head. (iii) Studying token brokers specialised for the ONNX operator improve efficient context. (iv) An extended context is beneficial. (v) Scaling to a bigger gemma encoder additional improves correlation with correct tuning.
- Coaching code. Regression lm The library offers text-to-text regression utilities, constrained decoding, and multitasking pre-processing/fine-tuning recipes.
Essential statistics
- App (Python) Reminiscence: Spearman ρ> 0.9.
- Codenet (17 languages) Reminiscence: common ρ> 0.5;The strongest languages embrace C/C++ (~0.74–0.75).
- Triton Kernel (A6000) Latency: ρ≈0.52.
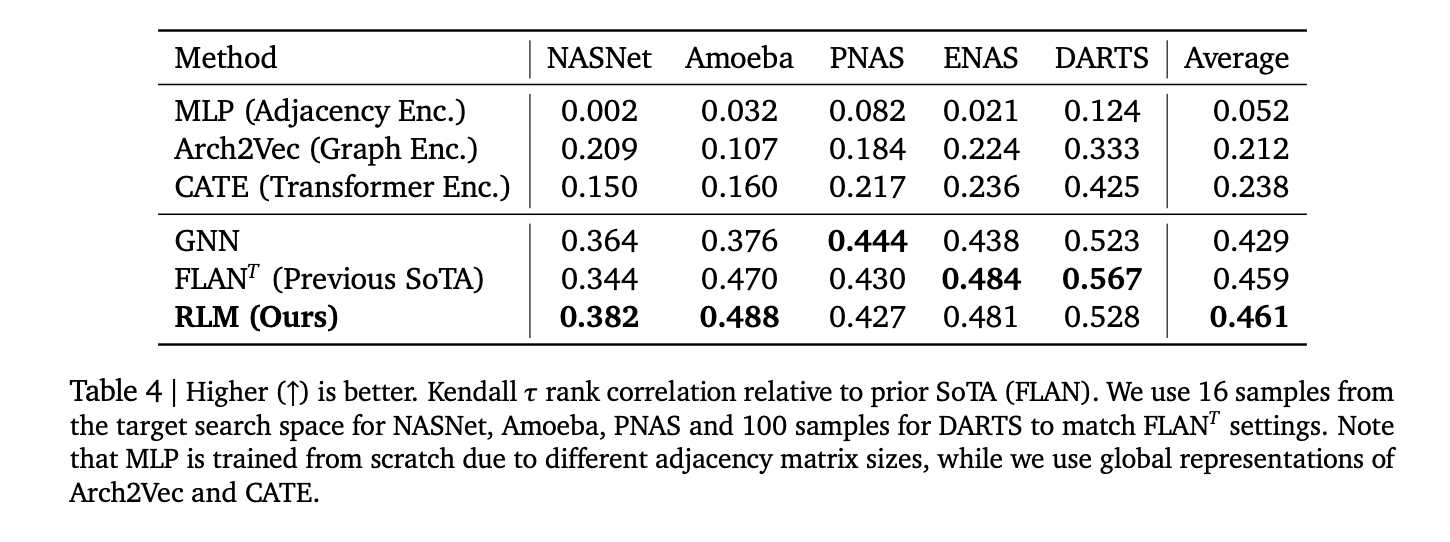
- NAS Rating: common Kendall τ≈0.46 Past Nasnet, Amoeba, PNA, Enas and Darts. Competitors with FLAN and GNN baselines.
Key takeout
- Metric regression from unified code works. A single ~300m parameter T5GEMMA Initialized mannequin (“RLM”) predicts (a) reminiscence from high-level code, (b) Triton GPU kernel latency, and (c) mannequin accuracy from ONNX + system latency straight from textual content, with out hand ejected options.
- This examine exhibits Spearman ρ > 0.9 in app reminiscence, ≈0.52 in Triton latency, ≈0.52 in codenet languages, 17 common > 0.5, and Kendall τ≈0.46 in 5 NAS areas.
- Numbers are decoded as constrained textual content. As an alternative of the regression head, RLM emits numeric tokens with constrained decoding, permitting for multimetric autoregressive outputs (for instance, adopted by multi-device latency) and uncertainty attributable to sampling.
- Code restoration The dataset integrates app/REIT code reminiscence, Triton kernel latency, and codenet reminiscence. Regression lm The library offers a coaching/decoding stack.
It is vitally attention-grabbing how this work reconstructs efficiency predictions as a quantity technology from textual content. The compact T5GEMMA Initialized RLM reads supply (Python/C++), Triton Kernels, or ONNX graphs and emits calibrated numbers by way of constrained decoding. Reported correlations embrace reminiscence (ρ> 0.9), triton latency (~0.52), and Nas Kendall-τ≈0.46- in RTX A6000 (~0.52), compiler heuristics, kernel pruning, and multipurpose NAS triage with out using options or GNN. Open datasets and libraries make it simpler and decrease boundaries to fine-tuning with new {hardware} and languages.
🚨 [Recommended Read] Vipe (Video Pause Engine): A strong and versatile 3D video annotation device for spatial AI
Please test paper, github page and Dataset Card. Please be happy to test GitHub pages for tutorials, code and notebooks. Additionally, please be happy to observe us Twitter And remember to affix us 100k+ ml subreddit And subscribe Our Newsletter. cling on! Are you on a telegram? You can now join Telegram.
Asif Razzaq is CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, ASIF is dedicated to leveraging the chances of synthetic intelligence for social advantages. His newest efforts are the launch of MarkTechPost, a man-made intelligence media platform. That is distinguished by its detailed protection of machine studying and deep studying information, and is straightforward to grasp by a technically sound and extensive viewers. The platform has over 2 million views every month, indicating its recognition amongst viewers.

{kind=link}