


Alibaba’s QWen group has launched an FP8 quantification checkpoint for the brand new QWEN3-NEXT-80B-A3B mannequin with two post-training variants.Instructions and thought– Assumed with high-throughput inference with ultra-long context and MOE effectivity. The FP8 repository mirrors the discharge of BF16, however packages the “fine-grained FP8” weight (block dimension 128) and deployment notes for SGLANG and VLLM nighttime builds. The benchmark for the cardboard stays the benchmark of the unique BF16 mannequin. FP8 is offered “for comfort and efficiency” moderately than as an unbiased analysis run.
What do A3B stacks have?
The QWEN3-NEXT-80B-A3B is a hybrid structure that mixes gate deltanet (linear/typical consideration surrogate) and gate consideration, interleaving with ultrasparse mixtures (MOEs). The entire parameter price range of 80B prompts ~3B parameters per token by means of 512 consultants (10 routing + 1 share). The format is designated as 48 layers positioned in 12 blocks. 3×(Gated DeltaNet → MoE) adopted by 1×(Gated Consideration → MoE). The native context is 262,144 tokens, validated as much as 1,010,000 tokens utilizing rope scaling (YARN). The hidden dimension is 2048. Observe: Use a 16 Q head and a couple of kV head with a Head Dim 256. Deltanet makes use of 32V and 16 QK linear heads on the Head Dim 128.
The QWEN group stories that the 80B-A3B-based mannequin outperforms QWEN3-32B in downstream duties at about 10% of the coaching price, driving a low activation of MOE and multi-token prediction (MTP). Educational variants are irrational (no <suppose> tag). Then again, the considering variant performs inference tracing by default, and is optimized for advanced issues.

FP8 launch: What has truly modified
The FP8 mannequin card states that quantization is a “high quality particle FP8” with a block dimension of 128. The event is barely completely different from BF16. Each SGLANG and VLLM require the present important/nightly construct, and examples of instructions are offered in 256K context and elective MTP. Considering fp8 playing cards additionally advocate inference parser flags (e.g. --reasoning-parser deepseek-r1 With sglang, deepseek_r1 (in vllm). These releases are licensed below the Apache-2.0.
Benchmark (Reporting on BF16 weights)
The instruction FP8 card reproduces QWEN’s BF16 comparability desk and makes the QWEN3-NEXT-80B-A3B-INSTRUCT equal to QWEN3-235B-A22B-Instruct-2507. Considering FP8 playing cards listing Aime’25, HMMT’25, MMLU-Professional/Redux, and LiveCodebench V6. Right here we’re considering of the QWEN3-NEXT-80B-A3B.
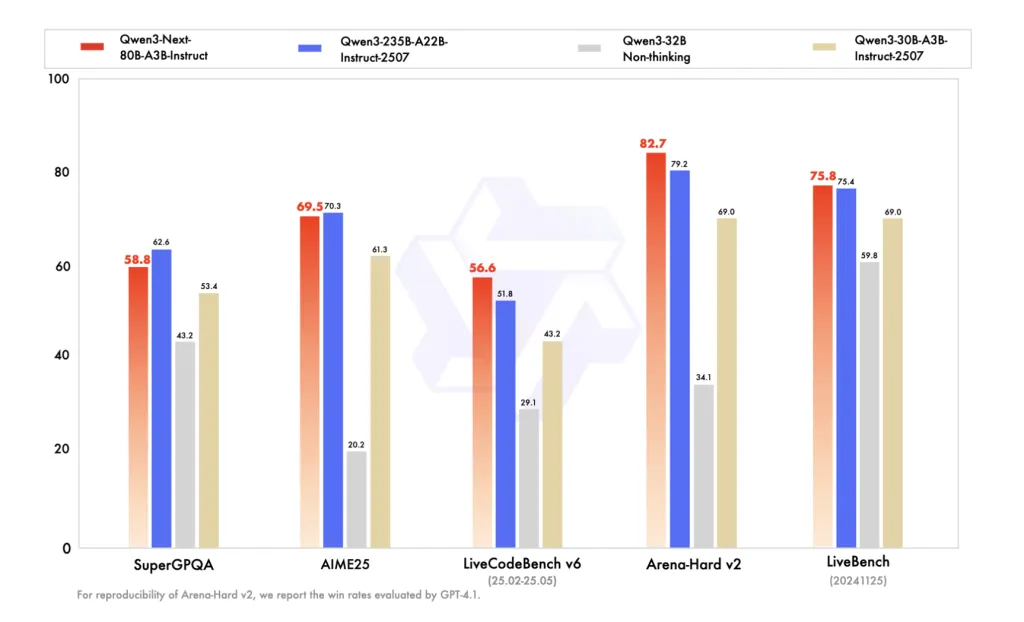
Coaching and post-training indicators
This sequence is educated with ~15T tokens after coaching. Qwen makes use of GSPO in post-training RL to focus on the addition of stability (comparable to zero facilities, norms of weight-deleted layers) and to deal with the Hybrid Attones + Excessive-Sparsity MoE mixture. MTP is used to hurry up inference and improves pre-deletion indicators.
Why is FP8 vital?
In fashionable accelerators, the activation/weight of the FP8 reduces reminiscence bandwidth stress and resident footprint and BF16, permitting for bigger batch sizes or longer sequences with related latency. A3B routes solely ~3B parameters per token, so the FP8 + MOE sparse mixture will purchase a rise in throughput on an extended context regime, particularly when paired with speculative decoding by way of MTP uncovered to the serving flag. That being mentioned, quantization interacts with routing and attentional variants. The true-world acceptance fee of speculative decoding and end-task accuracy might range relying on engine and kernel implementation. Subsequently, Qwen’s steering makes use of present Sglang/VLLM to regulate speculative settings.
abstract
QWEN’s FP8 launch will allow the 80B/3B energetic A3B stack to work virtually and virtually within the 256K context of mainstream engines, sustaining hybrid mo design and excessive throughput MTP paths. Because the mannequin card maintains the benchmark from BF16, groups have to confirm the accuracy and latency of FP8 on their very own stack, notably utilizing inference parser and speculative settings. Internet Outcomes: Low reminiscence bandwidth, improved concurrency with out constructing regression, and positioned for lengthy context manufacturing workloads.
Please verify QWEN3-NEXT-80B-A3B Mannequin Two Submit-Coaching Variant Fashions –Instructions and thought. Please be happy to verify GitHub pages for tutorials, code and notebooks. Additionally, please be happy to comply with us Twitter And do not forget to affix us 100k+ ml subreddit And subscribe Our Newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, ASIF is dedicated to leveraging the probabilities of synthetic intelligence for social advantages. His newest efforts are the launch of MarkTechPost, a synthetic intelligence media platform. That is distinguished by its detailed protection of machine studying and deep studying information, and is straightforward to know by a technically sound and vast viewers. The platform has over 2 million views every month, indicating its recognition amongst viewers.
🔥[Recommended Read] Nvidia AI Open-Sources Vipe (Video Pause Engine): A strong and versatile 3D video annotation device for spatial AI

{kind=link}