


The clever agent is an AI analysis framework and prototype from Google and is the selection each motion Augmented Actuality (AR) brokers ought to take it Interplay modalities Conditioned to a real-time multimodal context (eg, whether or not your arms are busy, ambient noise, social settings), ship/examine it. Reasonably than treating “what to suggest” and “how you can ask” as separate points, we’ll work collectively to attenuate wild friction and social awkwardness.
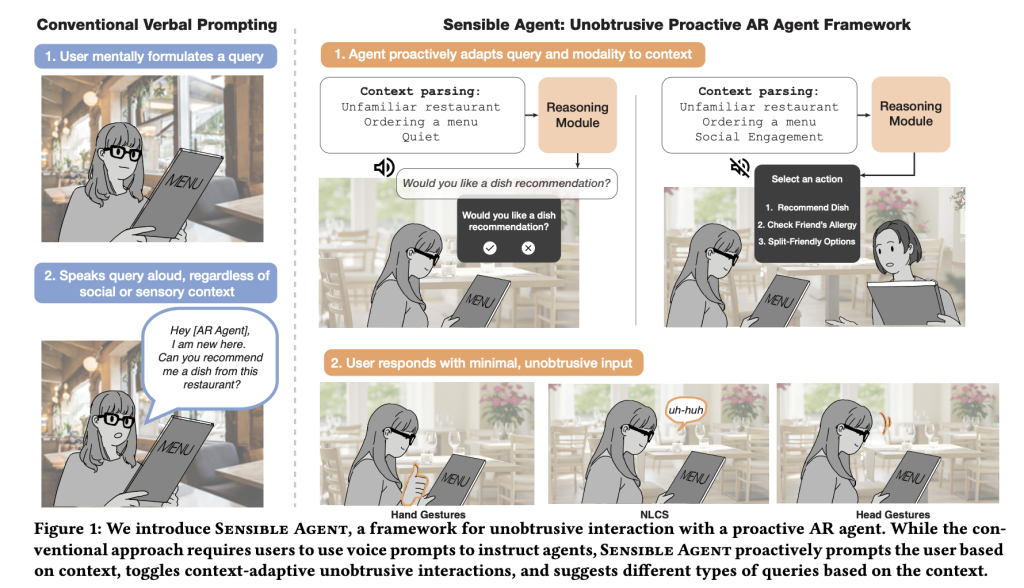
What interplay failure modes are focused?
Voice first prompts are weak. It’s gradual underneath time stress, can’t be used with busy arms/eyes, and troublesome in public locations. A sensible agent’s core wager is that prime high quality recommendations supplied over the improper channel are successfully noise. The framework explicitly mannequin Joint determination (a) what Brokers counsel (really helpful/information/reminiscence/automation) and (b) how It was offered and confirmed (imaginative and prescient, audio, or each. Head nods/shakes/tlants, gaze lodging, finger poses, short-circuit speech, or enter through non-flexible conversational sounds). By binding content material choice to modality feasibility and social acceptability, the system goals to scale back perceived efforts whereas sustaining utility.
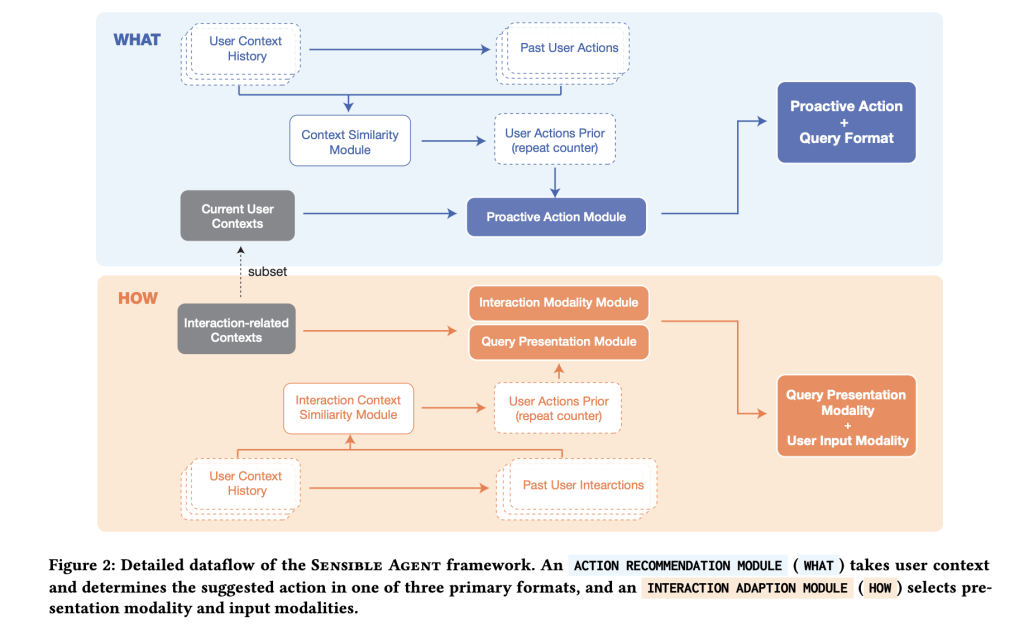
How is the system architected at runtime?
The prototype of the Android class XR headset is Three fundamental levels. starting, Context Evaluation It fuses selfish photos (imaginative and prescient language inference for scene/exercise/friendliness) with an ambient audio classifier (YAMNET) for detecting circumstances akin to noise and dialog. Secondly, a Proactive Question Generator Immediate massive multimodal fashions with a number of photographs instance motion, Question construction (binary/multiselect/icon queue), and Presentation modality. Third, Interplay Layer Solely allow enter strategies which might be appropriate with the provision of sensed I/O. For instance, if the whisper is unacceptable, or if the hand is occupied, you nod to “sure” to look at the gaze.
The place did the designer’s intuition or knowledge come from?
The group seeds coverage area in two research. Knowledgeable Workshop (n = 12) To record which microinputs are socially acceptable when energetic assist is helpful. And a Context mapping survey (n = 40; 960 entries) On a regular basis eventualities the place contributors specify the specified agent motion and select their preferences (health club, groceries, museums, commutes, cooking, and so forth.) Question Kind and Modality A context is given. These mappings floor the small variety of photographs used at runtime and shift the “what + means” choice from advert hoc heuristics to data-derived patterns (e.g., multi-selection in unfamiliar environments, binary underneath time stress, visualization in socially delicate settings).
What particular interplay methods does the prototype assist?
for binary Test, the system acknowledges Nod/Shake;for Multi-selectiona Head tilt Return to scheme map left/proper/choices 1/2/3. Finger pose The gesture helps numerical choice and offers thumbs up and down. The gaze resides Raycast pointing triggers loud visible buttons. Quick Volary Speech (e.g., “sure”, “no”, “1”, “2”, “3”) gives a minimal dictation path. and Non-measurable dialog sounds (“mm-hm”) Covers noise-only contexts and whispers solely contexts. Importantly, the pipeline solely gives modalities that may be carried out underneath present constraints (for instance, suppress audio prompts in quiet areas; keep away from gaze lodging if the consumer just isn’t wanting on the HUD).
Does joint choices truly scale back interplay prices?
Preliminary in-subject consumer survey (n = 10) Evaluate the framework with AR and 360°VR voice immediate baselines Low perceived interplay effort and Low invasiveness Whereas sustaining ease of use and preferences. It is a small pattern typical of early HCI verification. It’s not product grade proof however directional proof, however it’s in step with the paper that conjoining intent and modality reduces overhead.
How does the audio facet work, and why yamnet?
Yamnet is a light-weight MobileNet-V1 primarily based audio occasion classifier educated on Google’s audio set, predicting 521 lessons. On this context, detecting tough surrounding circumstances, akin to audio presence, music, and crowd noise, is a sensible selection. It is sufficient to gate audio prompts or bias visible/gesture interactions when audio is bothering or unreliable. The ever-present nature of the Tensorflow Hub and Edge Information fashions makes it straightforward to deploy on gadgets.
How do I combine it into an current AR or cellular assistant stack?
The minimal recruitment plan is as follows: (1) Light-weight context parser for producing compact states (selfish frames + VLM for ambient audio tags). (2) Construct a A couple of shot tables Context → (motion, question sort, modality) Mapping from inner pilot or consumer survey. (3) Invite to launch lmm each “What” and “how.” (4) Solely publicly obtainable Might be finished Enter every state and keep affirmation binary By default. (5) Offline log choice and outcomes Coverage studying. The clever agent artifacts point out that this may be run on WebXR/Chrome on Android-class {hardware}, so transferring to a local HMD runtime or phone-based HUD is usually an engineering train.
abstract
A clever agent operates proactive AR as a mixed coverage drawback – select motion and Interplay modalities We look at the method with a working WebXR prototype and a Small-N consumer research exhibiting low perceived interplay efforts for speech baselines with a single context-conditioned determination. The framework’s contribution just isn’t a product, however a reproducible recipe. Context dataset → (what/how) mapping, a number of shot prompts to bind at runtime, and low-effort enter primitives that respect social and I/O constraints.
Please examine paper and Technical details. Please be happy to examine GitHub pages for tutorials, code and notebooks. Additionally, please be happy to observe us Twitter And remember to affix us 100k+ ml subreddit And subscribe Our Newsletter.

Mikal Sutter is a knowledge science knowledgeable with a Grasp’s diploma in Information Science from Padova College. With its stable foundations of statistical evaluation, machine studying, and knowledge engineering, Michal excels at remodeling complicated datasets into actionable insights.
🔥[Recommended Read] Nvidia AI Open-Sources Vipe (Video Pause Engine): A strong and versatile 3D video annotation software for spatial AI

{kind=link}