


Right now, we’re excited to announce that Amazon SageMaker HyperPod now helps managed node computerized scaling with Karpenter, so you may effectively scale your SageMaker HyperPod clusters to fulfill your inference and coaching calls for. Actual-time inference workloads require computerized scaling to deal with unpredictable visitors patterns and preserve service stage agreements (SLAs). As demand spikes, organizations should quickly adapt their GPU compute with out compromising response occasions or cost-efficiency. In contrast to self-managed Karpenter deployments, this service-managed resolution alleviates the operational overhead of putting in, configuring, and sustaining Karpenter controllers, whereas offering tighter integration with the resilience capabilities of SageMaker HyperPod. This managed strategy helps scale to zero, decreasing the necessity for devoted compute sources to run the Karpenter controller itself, enhancing cost-efficiency.
SageMaker HyperPod provides a resilient, high-performance infrastructure, observability, and tooling optimized for large-scale mannequin coaching and deployment. Corporations like Perplexity, HippocraticAI, H.AI, and Articul8 are already utilizing SageMaker HyperPod for coaching and deploying fashions. As extra clients transition from coaching basis fashions (FMs) to operating inference at scale, they require the flexibility to routinely scale their GPU nodes to deal with actual manufacturing visitors by scaling up throughout excessive demand and cutting down in periods of decrease utilization. This functionality necessitates a strong cluster auto scaler. Karpenter, an open supply Kubernetes node lifecycle supervisor created by AWS, is a well-liked alternative amongst Kubernetes customers for cluster auto scaling on account of its highly effective capabilities that optimize scaling occasions and cut back prices.
This launch gives a managed Karpenter-based resolution for computerized scaling that’s put in and maintained by SageMaker HyperPod, eradicating the undifferentiated heavy lifting of setup and administration from clients. The characteristic is offered for SageMaker HyperPod EKS clusters, and you may allow auto scaling to remodel your SageMaker HyperPod cluster from static capability to a dynamic, cost-optimized infrastructure that scales with demand. This combines Karpenter’s confirmed node lifecycle administration with the purpose-built and resilient infrastructure of SageMaker HyperPod, designed for large-scale machine studying (ML) workloads. On this put up, we dive into the advantages of Karpenter, and supply particulars on enabling and configuring Karpenter in your SageMaker HyperPod EKS clusters.
New options and advantages
Karpenter-based auto scaling in your SageMaker HyperPod clusters gives the next capabilities:
- Service managed lifecycle – SageMaker HyperPod handles Karpenter set up, updates, and upkeep, assuaging operational overhead
- Simply-in-time provisioning – Karpenter observes your pending pods and provisions the required compute on your workloads from an on-demand pool
- Scale to zero – You’ll be able to scale all the way down to zero nodes with out sustaining devoted controller infrastructure
- Workload-aware node choice – Karpenter chooses optimum occasion varieties primarily based on pod necessities, Availability Zones, and pricing to reduce prices
- Computerized node consolidation – Karpenter usually evaluates clusters for optimization alternatives, shifting workloads to keep away from underutilized nodes
- Built-in resilience – Karpenter makes use of the built-in fault tolerance and node restoration mechanisms of SageMaker HyperPod
These capabilities are constructed on prime of not too long ago launched steady provisioning capabilities, which permits SageMaker HyperPod to routinely provision remaining capability within the background whereas workloads begin instantly on obtainable cases. When node provisioning encounters failures on account of capability constraints or different points, SageMaker HyperPod routinely retries within the background till clusters attain their desired scale, so your auto scaling operations stay resilient and non-blocking.
Answer overview
The next diagram illustrates the answer structure.
Karpenter works as a controller within the cluster and operates within the following steps:
- Watching – Karpenter watches for un-schedulable pods within the cluster via the Kubernetes API server. These may very well be pods that go into pending state when deployed or routinely scaled to extend the duplicate rely.
- Evaluating – When Karpenter finds such pods, it computes the form and dimension of a NodeClaim to suit the set of pods necessities (GPU, CPU, reminiscence) and topology constraints, and checks if it could pair them with an present NodePool. For every NodePool, it queries the SageMaker HyperPod APIs to get the occasion varieties supported by the NodePool. It makes use of the details about occasion kind metadata ({hardware} necessities, zone, capability kind) to discover a matching NodePool.
- Provisioning – If Karpenter finds an identical NodePool, it creates a NodeClaim and tries to provision a brand new occasion for use as the brand new node. Karpenter internally makes use of the
sagemaker:UpdateClusterAPI to extend the capability of the chosen occasion group. - Disrupting – Karpenter periodically checks if a brand new node is required or not. If it’s not wanted, Karpenter deletes it, which internally interprets to a delete node request to the SageMaker HyperPod cluster.
Stipulations
Confirm you might have the required quotas for the cases you’ll create within the SageMaker HyperPod cluster. To assessment your quotas, on the Service Quotas console, select AWS providers within the navigation pane, then select SageMaker. For instance, the next screenshot reveals the obtainable quota for g5.12xlarge cases (three).
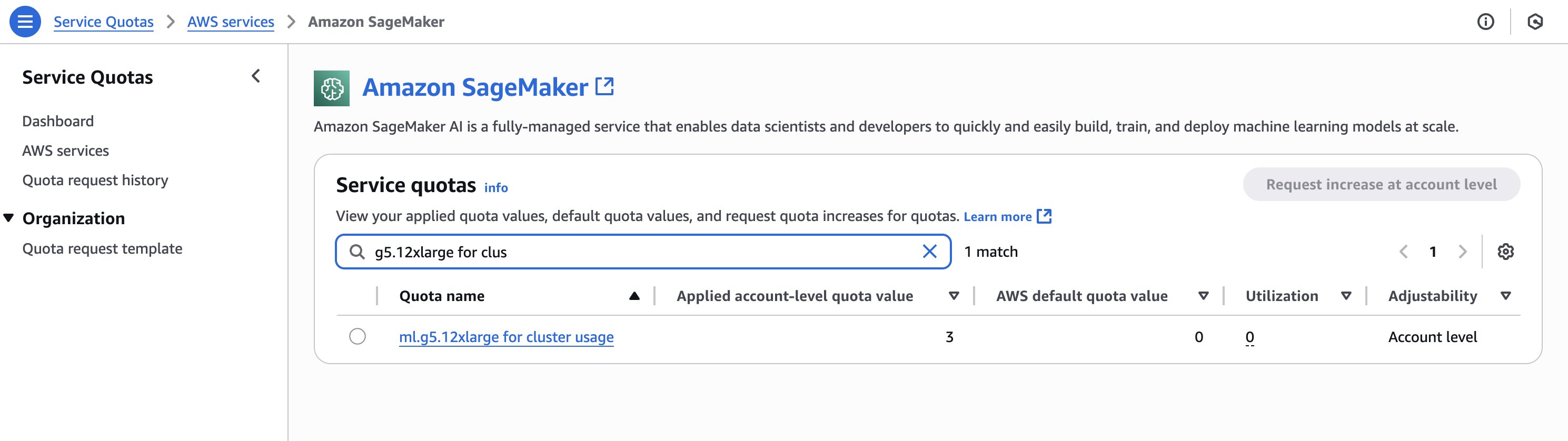
To replace the cluster, you could first create AWS Identification and Entry Administration (IAM) permissions for Karpenter. For directions, see Create an IAM position for HyperPod autoscaling with Karpenter.
Create and configure a SageMaker HyperPod cluster
To start, launch and configure your SageMaker HyperPod EKS cluster and confirm that steady provisioning mode is enabled on cluster creation. Full the next steps:
- On the SageMaker AI console, select HyperPod clusters within the navigation pane.
- Select Create HyperPod cluster and Orchestrated on Amazon EKS.
- For Setup choices, choose Customized setup.
- For Identify, enter a reputation.
- For Occasion restoration, choose Computerized.
- For Occasion provisioning mode, choose Use steady provisioning.
- Select Submit.
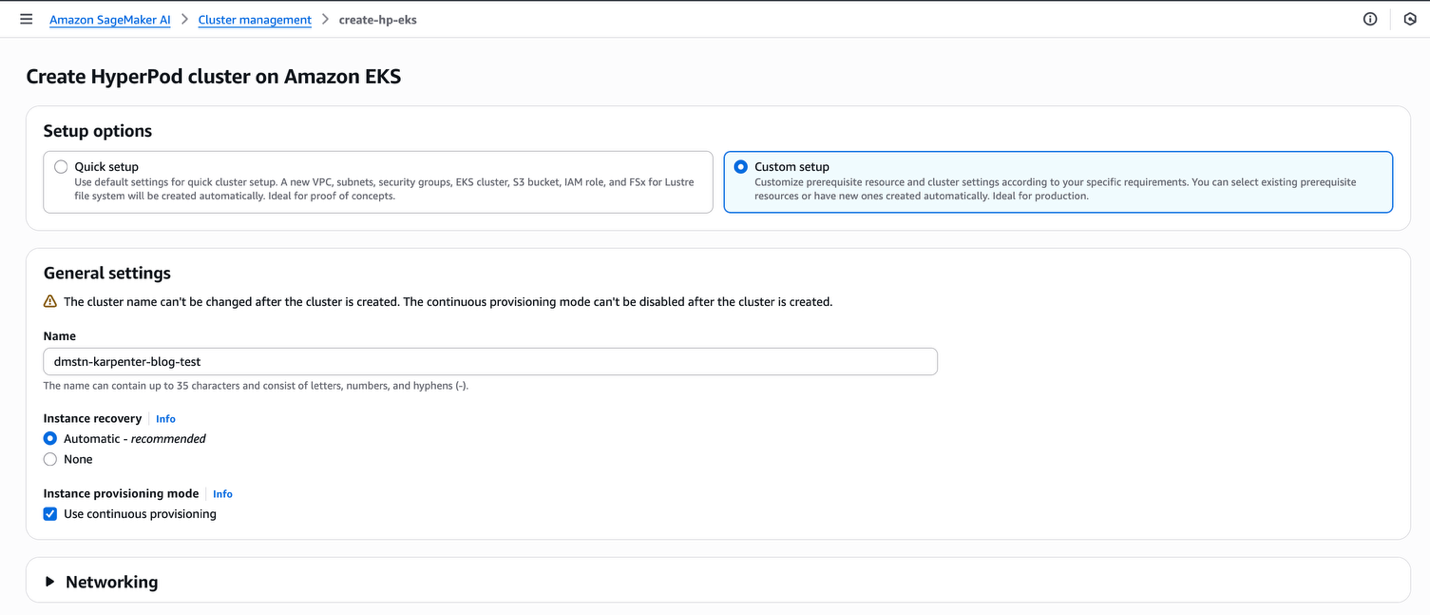
This setup creates the required configuration resembling digital personal cloud (VPC), subnets, safety teams, and EKS cluster, and installs operators within the cluster. You may also present present sources resembling an EKS cluster if you wish to use an present cluster as a substitute of making a brand new one. This setup will take round 20 minutes.
Confirm that every InstanceGroup is restricted to 1 zone by choosing the OverrideVpcConfig and deciding on just one subnet per every InstanceGroup.

After you create the cluster, you could replace it to allow Karpenter. You are able to do this utilizing Boto3 or the AWS Command Line Interface (AWS CLI) utilizing the UpdateCluster API command (after configuring the AWS CLI to hook up with your AWS account).
The next code makes use of Python Boto3:
After you run this command and replace the cluster, you may confirm that Karpenter has been enabled by operating the DescribeCluster API.
The next code makes use of Python:
The next code makes use of the AWS CLI:
The next code reveals our output:
Now you might have a working cluster. The following step is to arrange some customized sources in your cluster for Karpenter.
Create HyperpodNodeClass
HyperpodNodeClass is a customized useful resource that maps to pre-created occasion teams in SageMaker HyperPod, defining constraints round which occasion varieties and Availability Zones are supported for Karpenter’s auto scaling choices. To make use of HyperpodNodeClass, merely specify the names of the InstanceGroups of your SageMaker HyperPod cluster that you just need to use because the supply for the AWS compute sources to make use of to scale up your pods in your NodePools.
The HyperpodNodeClass identify that you just use right here is carried over to the NodePool within the subsequent part the place you reference it. This tells the NodePool which HyperpodNodeClass to attract sources from. To create a HyperpodNodeClass, full the next steps:
- Create a YAML file (for instance,
nodeclass.yaml) just like the next code. AddInstanceGroupnames that you just used on the time of the SageMaker HyperPod cluster creation. You may also add new occasion teams to an present SageMaker HyperPod EKS cluster. - Reference the
HyperPodNodeClassidentify in your NodePool configuration.
The next is a pattern HyperpodNodeClass that makes use of ml.g6.xlarge and ml.g6.4xlarge occasion varieties:
- Apply the configuration to your EKS cluster utilizing
kubectl:
- Monitor the
HyperpodNodeClassstanding to confirm thePreparedsituation in standing is ready toTrueto make sure it was efficiently created:
The SageMaker HyperPod cluster should have AutoScaling enabled and the AutoScaling standing should change to InService earlier than the HyperpodNodeClass may be utilized.
For extra data and key concerns, see Autoscaling on SageMaker HyperPod EKS.
Create NodePool
The NodePool units constraints on the nodes that may be created by Karpenter and the pods that may run on these nodes. The NodePool may be set to carry out numerous actions, resembling:
- Outline labels and taints to restrict the pods that may run on nodes Karpenter creates
- Restrict node creation to sure zones, occasion varieties, and pc architectures, and so forth
For extra details about NodePool, discuss with NodePools. SageMaker HyperPod managed Karpenter helps a restricted set of well-known Kubernetes and Karpenter necessities, which we clarify on this put up.
To create a NodePool, full the next steps:
- Create a YAML file named
nodepool.yamltogether with your desired NodePool configuration.
The next code is a pattern configuration to create a pattern NodePool. We specify the NodePool to incorporate our ml.g6.xlarge SageMaker occasion kind, and we moreover specify it for one zone. Seek advice from NodePools for extra customizations.
- Apply the NodePool to your cluster:
- Monitor the NodePool standing to make sure the
Preparedsituation within the standing is ready toTrue:
This instance reveals how a NodePool can be utilized to specify the {hardware} (occasion kind) and placement (Availability Zone) for pods.
Launch a easy workload
The next workload runs a Kubernetes deployment the place the pods in deployment are requesting for 1 CPU and 256 MB reminiscence per duplicate, per pod. The pods haven’t been spun up but.
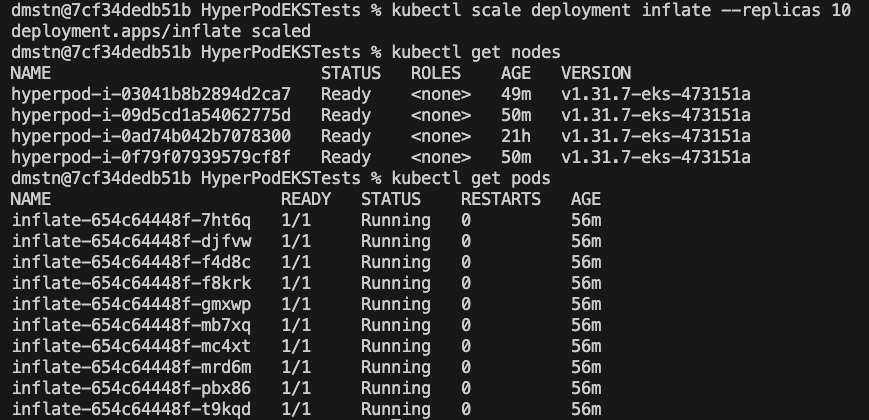
Once we apply this, we will see a deployment and a single node launch in our cluster, as proven within the following screenshot.

To scale this part, use the next command:
Inside a couple of minutes, we will see Karpenter add the requested nodes to the cluster.
Implement superior auto scaling for inference with KEDA and Karpenter
To implement an end-to-end auto scaling resolution on SageMaker HyperPod, you may arrange Kubernetes Event-driven Autoscaling (KEDA) together with Karpenter. KEDA permits pod-level auto scaling primarily based on a variety of metrics, together with Amazon CloudWatch metrics, Amazon Easy Queue Service (Amazon SQS) queue lengths, Prometheus queries, and useful resource utilization patterns. By configuring Keda ScaledObject sources to focus on your mannequin deployments, KEDA can dynamically regulate the variety of inference pods primarily based on real-time demand indicators.
When integrating KEDA and Karpenter, this mix creates a strong two-tier auto scaling structure. As KEDA scales your pods up or down primarily based on workload metrics, Karpenter routinely provisions or deletes nodes in response to altering useful resource necessities. This integration delivers optimum efficiency whereas controlling prices by ensuring your cluster has exactly the correct amount of compute sources obtainable always. For efficient implementation, think about the next key components:
- Set acceptable buffer thresholds in KEDA to accommodate Karpenter’s node provisioning time
- Configure cooldown durations fastidiously to forestall scaling oscillations
- Outline clear useful resource requests and limits to assist Karpenter make optimum node picks
- Create specialised NodePools tailor-made to particular workload traits
The next is a pattern spec of a KEDA ScaledObject file that scales the variety of pods primarily based on CloudWatch metrics of Software Load Balancer (ALB) request rely:
Clear up
To scrub up your sources to keep away from incurring extra costs, delete your SageMaker HyperPod cluster.
Conclusion
With the launch of Karpenter node auto scaling on SageMaker HyperPod, ML workloads can routinely adapt to altering workload necessities, optimize useful resource utilization, and assist management prices by scaling exactly when wanted. You may also combine it with event-driven pod auto scalers resembling KEDA to scale primarily based on customized metrics.
To expertise these advantages on your ML workloads, allow Karpenter in your SageMaker HyperPod clusters. For detailed implementation steerage and greatest practices, discuss with Autoscaling on SageMaker HyperPod EKS.
Concerning the authors
 Vivek Gangasani is a Worldwide Lead GenAI Specialist Options Architect for SageMaker Inference. He drives Go-to-Market (GTM) and Outbound Product technique for SageMaker Inference. He additionally helps enterprises and startups deploy, handle, and scale their GenAI fashions with SageMaker and GPUs. Presently, he’s targeted on growing methods and content material for optimizing inference efficiency and GPU effectivity for internet hosting Massive Language Fashions. In his free time, Vivek enjoys mountaineering, watching motion pictures, and making an attempt totally different cuisines.
Vivek Gangasani is a Worldwide Lead GenAI Specialist Options Architect for SageMaker Inference. He drives Go-to-Market (GTM) and Outbound Product technique for SageMaker Inference. He additionally helps enterprises and startups deploy, handle, and scale their GenAI fashions with SageMaker and GPUs. Presently, he’s targeted on growing methods and content material for optimizing inference efficiency and GPU effectivity for internet hosting Massive Language Fashions. In his free time, Vivek enjoys mountaineering, watching motion pictures, and making an attempt totally different cuisines.
 Adam Stanley is a Answer Architect for Software program, Web and Mannequin Supplier clients at Amazon Internet Companies (AWS). He helps clients adopting all AWS providers, however focuses totally on Machine Studying coaching and inference infrastructure. Previous to AWS, Adam went to the College of New South Wales and graduated with levels in Arithmetic and Accounting. You’ll be able to join with him on LinkedIn.
Adam Stanley is a Answer Architect for Software program, Web and Mannequin Supplier clients at Amazon Internet Companies (AWS). He helps clients adopting all AWS providers, however focuses totally on Machine Studying coaching and inference infrastructure. Previous to AWS, Adam went to the College of New South Wales and graduated with levels in Arithmetic and Accounting. You’ll be able to join with him on LinkedIn.
 Kunal Jha is a Principal Product Supervisor at AWS, the place he focuses on constructing Amazon SageMaker HyperPod to allow scalable distributed coaching and fine-tuning of basis fashions. In his spare time, Kunal enjoys snowboarding and exploring the Pacific Northwest. You’ll be able to join with him on LinkedIn.
Kunal Jha is a Principal Product Supervisor at AWS, the place he focuses on constructing Amazon SageMaker HyperPod to allow scalable distributed coaching and fine-tuning of basis fashions. In his spare time, Kunal enjoys snowboarding and exploring the Pacific Northwest. You’ll be able to join with him on LinkedIn.
 Ty Bergstrom is a Software program Engineer at Amazon Internet Companies. He works on the HyperPod Clusters platform for Amazon SageMaker.
Ty Bergstrom is a Software program Engineer at Amazon Internet Companies. He works on the HyperPod Clusters platform for Amazon SageMaker.

{kind=link}