


Nvidia has launched the Nemotron Nano 2 household and has launched a number one language mannequin (LLM) of hybrid mamba converters that not solely pushes cutting-edge inference accuracy, but in addition provides as much as six occasions greater inference throughput than equally sized fashions. Nvidia provides most coaching corpus and recipes together with group mannequin checkpoints, so this launch stands out with the unprecedented transparency of information and methodology. Critically, these fashions preserve giant 128K token context capabilities on a single midrange GPU, considerably lowering the limitations to lengthy context inference and real-world deployment.
Necessary highlights
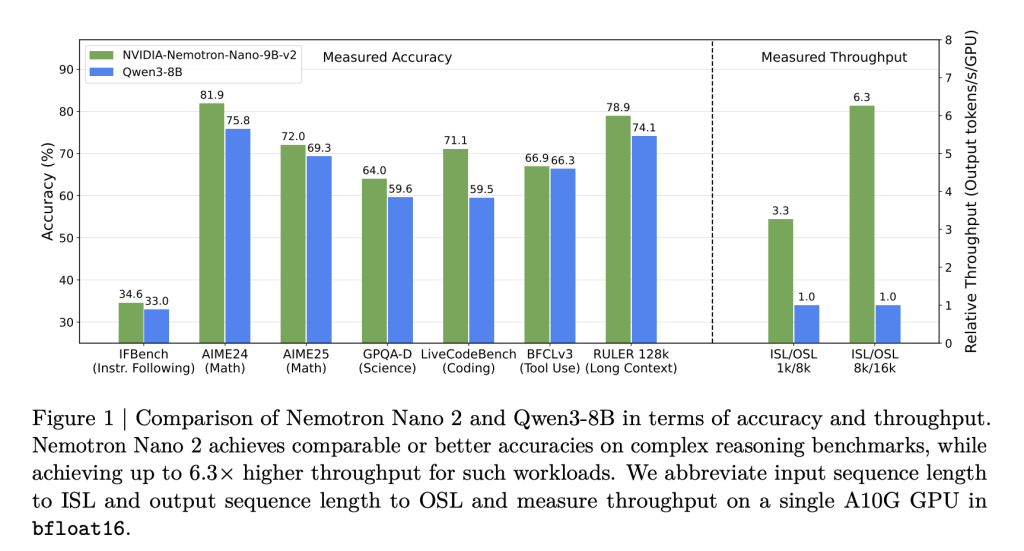
- Fashions of 6x Throughput and comparable measurement: The Nemotron Nano 2 fashions supply as much as 6.3x token technology speeds for fashions just like the QWEN3-8B in inference-rich eventualities with out sacrificing accuracy.
- Glorious accuracy for inference, coding, and multilingual duties: The benchmarks present commonplace or higher outcomes and aggressive open fashions, significantly past the friends of arithmetic, code, instruments, and lengthy contextual duties.
- Size of 128K context on a single GPU: Environment friendly pruning and hybrid structure permits for 128,000 token inferences on a single NVIDIA A10G GPU (22GIB).
- Open Information and Weights: Many of the pre-training and post-training datasets, together with code, arithmetic, multilingual, artificial SFT, and inference information, are launched with a tolerant license of embracing faces.
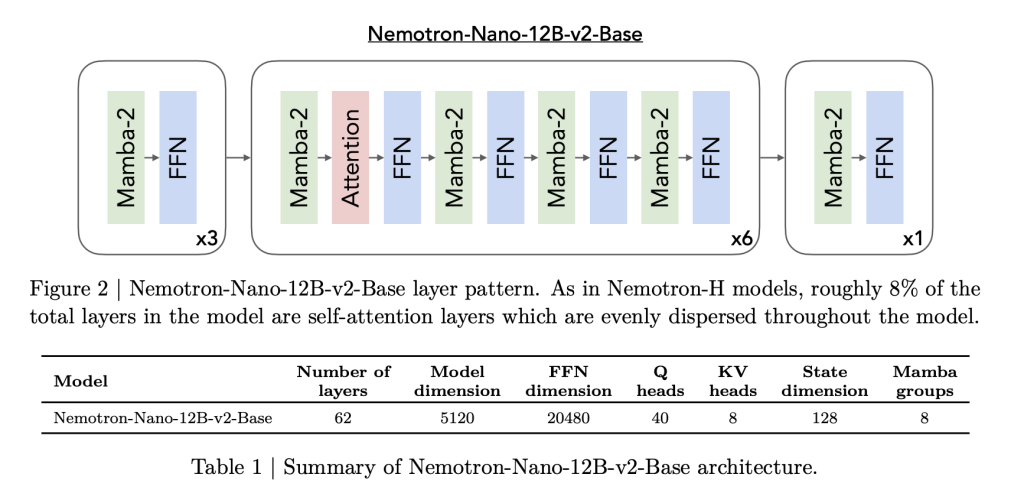
Hybrid Structure: Mamba meets transformers
The Nemotron Nano 2 is constructed on the spine of a hybrid mamba converter, impressed by the Nemotron-H structure. Most conventional autoarticular layers have been changed by environment friendly MAMBA-2 layers, with solely about 8% of the full layer utilizing autoarticulars. This structure is rigorously crafted:
- Mannequin particulars: The 9B parameter mannequin options 56 layers of hidden measurement (out of 62 pre-trained) with grouped question consideration and man-2 state house layers, facilitating each scalability and lengthy sequence retention.
- Mamba-2 Innovation: Not too long ago popularized as high-throughput sequencing fashions, these state-space layers are interleaved with sparse autojoints and enormous feedforward networks (to take care of long-range dependencies).
This construction permits for prime throughput for inference duties that require “considering tracing” based mostly on lengthy generations based mostly on lengthy in-context inputs, the place conventional transformer-based architectures usually sluggish or run out of reminiscence.
Coaching recipes: large-scale information range, open sourcing
The Nemotron Nano 2 fashions are educated and distilled from the 12B parameter trainer mannequin utilizing a variety of top quality corpus. Nvidia’s unprecedented information transparency is a spotlight.
- 20T token pre-delete: Information sources embody curated and artificial corpus for the net, arithmetic, code, multilingual, educational, and STEM domains.
- The principle datasets launched:
- nemotron-cc-v2: Multilingual internet crawling (15 languages), rephrasing artificial Q&A, deduplication.
- nemotron-cc-math: A “highest high quality” subset of over 52b, standardized tokens of mathematical content material, latex.
- Nemotron-Pretraining-Code: Github supply code filtered by curated high quality. Strict decontamination and deduplication.
- nemotron-pretraining-sft: STEM, inference, and synthesis through basic domains, instructions-following datasets.
- Submit-training information: It contains over 80B of supervised fine-tuning (SFT), RLHF, software calls, and tokens for multilingual datasets. Most of them are open sourced for direct reproducibility.
Alignment, Distillation, and Compression: Unlocking Price-Efficient Lengthy Context Inference
Nvidia’s mannequin compression course of is constructed on the “minitron” and mamba pruning framework.
- Distillation of Data From the 12B trainer, cautious pruning of layers, FFN dimensions and embedding width reduces the mannequin to 9B parameters.
- Multi-stage SFT and RL: It contains software name optimization (BFCL V3), instruction exposing (IFEVAL), DPO and GRPO enhancements, and “price range price range” administration (supporting controllable inference token budgets in inference).
- Reminiscence Goal NAS: Via structure search, the pruned mannequin is particularly designed in order that the mannequin and key worth cache stay match and efficiency with A10G GPU reminiscence with a 128K context size.
Outcomes: Inference speeds as much as 6 occasions quicker than open rivals in eventualities with giant I/O tokens with out compromising activity accuracy.
Benchmark: Glorious reasoning and multilingual options
In a direct analysis, the Nemotron Nano 2 fashions are superior.
| Job/Bench | Nemotron-Nano-9B-V2 | QWEN3-8B | gemma3-12b |
|---|---|---|---|
| MMLU (basic) | 74.5 | 76.4 | 73.6 |
| mmlu-pro (5 photographs) | 59.4 | 56.3 | 45.1 |
| GSM8K Cot (Arithmetic) | 91.4 | 84.0 | 74.5 |
| Arithmetic | 80.5 | 55.4 | 42.4 |
| Humaneval+ | 58.5 | 57.6 | 36.7 |
| Ruler-128K (lengthy context) | 82.2 | – | 80.7 |
| GlobalMMLU-Lite (AVG Multi) | 69.9 | 72.8 | 71.9 |
| MGSM Multilingual Arithmetic (AVG) | 84.8 | 64.5 | 57.1 |
- Throughput (token/s/gpu) 8k enter/16k output:
- Nemotron-Nano-9B-V2: As much as 6.3 x QWEN3-8B with inference traces.
- Maintains a most of 128K context with batch measurement = 1. This can develop into inactive on mid-range GPUs.
Conclusion
Nvidia’s Nemotron Nano 2 launch is a key second for open LLM analysis. Redefine what is feasible with a single cost-effective GPU whereas elevating the usual for information transparency and reproducibility. Its hybrid structure, throughput supreme, and prime quality open datasets are set to speed up innovation throughout the AI ecosystem.
Please test Technical details, paper and Model hugging her face. Please be happy to test GitHub pages for tutorials, code and notebooks. Additionally, please be happy to comply with us Twitter And do not forget to hitch us 100k+ ml subreddit And subscribe Our Newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, ASIF is dedicated to leveraging the probabilities of synthetic intelligence for social advantages. His newest efforts are the launch of MarkTechPost, a man-made intelligence media platform. That is distinguished by its detailed protection of machine studying and deep studying information, and is simple to grasp by a technically sound and broad viewers. The platform has over 2 million views every month, indicating its reputation amongst viewers.

{kind=link}