


Zhipu AI has formally launched the GLM-4.5V, the next-generation visible language mannequin (VLM), which tremendously advances the state of open multimodal AI, and is supplying open supply. Based mostly on Zhipu’s 100 billion parameter GLM-4.5 air structure, the 12 billion energetic parameters – GLM-4.5V by way of a mix of Consultants (MOE) designs brings highly effective real-world efficiency and unparalleled versatility throughout visible and textual content content material.
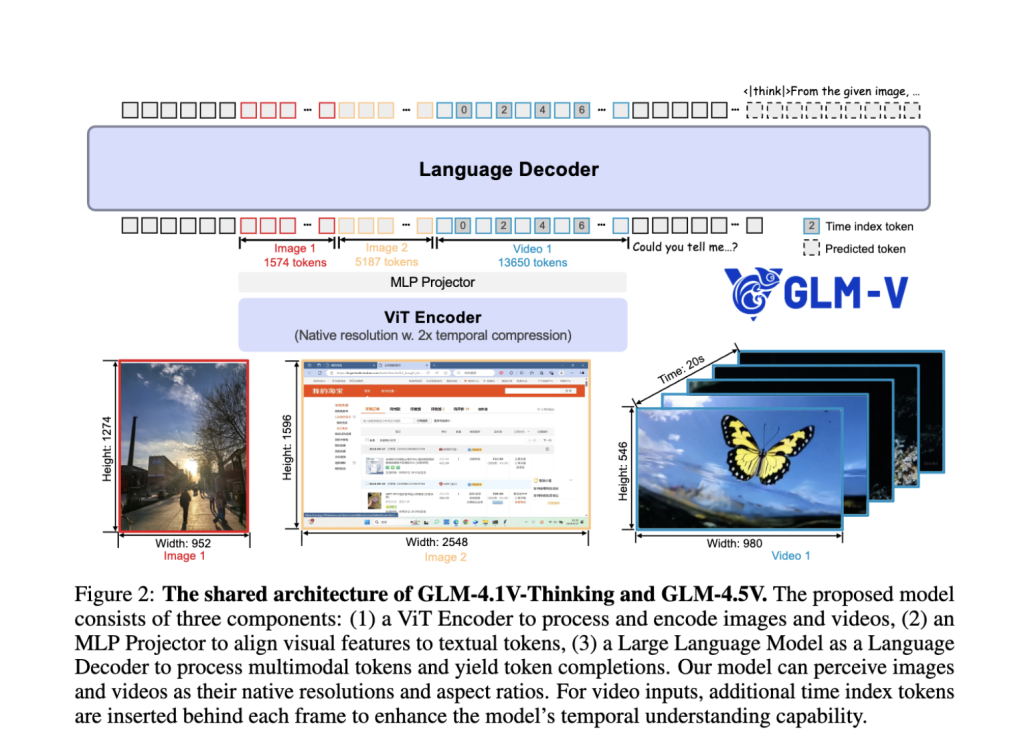
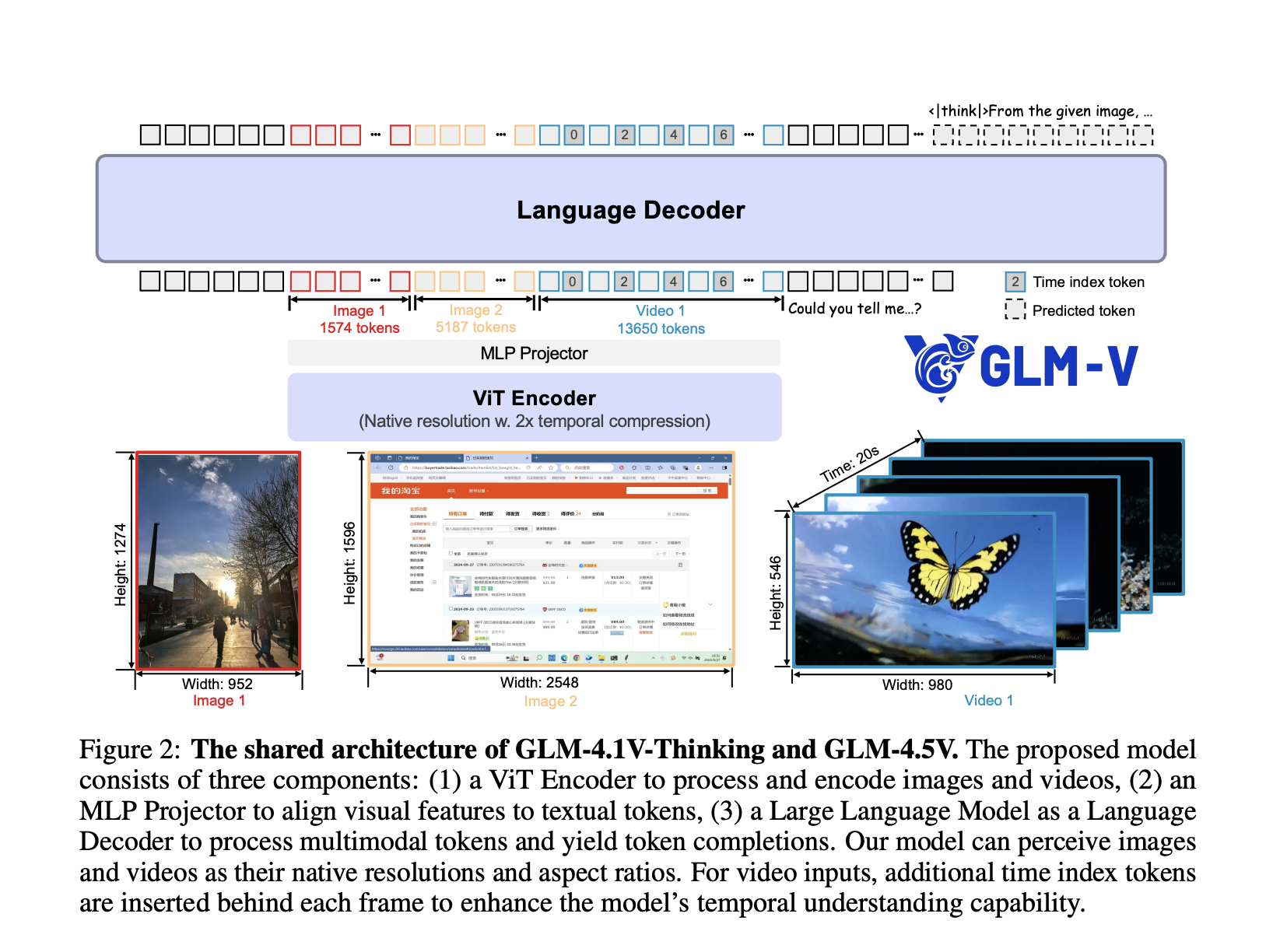
Foremost options and design innovation
1. Complete Visible Inference
- Picture reasoning: The GLM-4.5V achieves superior scene understanding, multi-image evaluation, and spatial recognition. Detailed relationships may be interpreted in advanced scenes (similar to distinguishing product defects, analyzing geographic cues, and inferring contexts from a number of photographs).
- Video Understanding: Processes lengthy movies, performs automated segmentation, and acknowledges delicate occasions because of the 3D convolutional imaginative and prescient encoder. This permits purposes similar to storyboarding, sports activities evaluation, monitoring evaluations, lecture summaries, and extra.
- Spatial reasoning: Built-in 3D Rotational Place Encoding (3D Rope) offers the mannequin a sturdy notion of three-dimensional spatial relationships, vital for deciphering visible scenes and grounding visible parts.
2. Superior GUI and Agent Duties
- Display screen studying and icon recognition: This mannequin is great at studying desktop/app interfaces, localizing buttons and icons, and aiding in automation. RPA (Robotic Course of Automation) and Accessibility Instruments are important.
- Desktop operation help: With an in depth visible understanding, GLM-4.5V can plan and describe GUI operations and assist customers navigate software program or carry out advanced workflows.
3. Complicated Charts and Doc Evaluation
- Understanding the Chart: GLM-4.5V can analyze charts, infographics, and scientific diagrams in PDF or PowerPoint information, and extract abstract conclusions and structured information from lengthy, dense paperwork.
- Interpretation of lengthy paperwork: With help of as much as 64,000 tokens in a multimodal context, it’s perfect for enterprise intelligence and data extraction by analyzing and summarizing enhanced image-rich paperwork (similar to analysis papers, contracts, compliance reviews).
4. Grounding and visible localization
- Correct grounding: This mannequin can precisely localize and describe visible parts, similar to objects, bounding bins, or particular UI parts, utilizing pixel-level cues in addition to world data and semantic contexts. This permits for detailed evaluation of high quality management, AR purposes, and picture annotation workflows.
Structure highlights
- Hybrid Imaginative and prescient Language Pipeline: The system integrates highly effective visible encoders, MLP adapters and language decoders to permit for a seamless fusion of visible and textual info. Static photographs, movies, GUIs, charts and paperwork are all handled as top notch inputs.
- Combination Combination (MOE) Effectivity: Whereas housed a complete parameter of 106B, the MOE design prompts solely 12B per inference, guaranteeing excessive throughput and reasonably priced deployment with out sacrificing accuracy.
- 3D convolution for movies and pictures: Video inputs are processed utilizing temporal downsampling and 3D convolution to permit evaluation of high-resolution video and native side ratios whereas sustaining effectivity.
- Adaptive context size: It helps as much as 64k tokens, permitting strong dealing with of multi-image prompts, concatenated paperwork, and lengthy dialogs in a single move.
- Revolutionary pre-training and RL: The coaching regime consists of large multimodal pre-training, supervised fine-tuning, and Reinforcement studying by means of curriculum sampling (RLCS) For lengthy chain inference, mastery and robustness of real-world duties.
“Pondering Mode” for adjustable reasoning depth
A notable function is the “pondering mode” toggle.
- Pondering mode on: Prioritize deep, step-by-step inference, appropriate for advanced duties (e.g. logical deduction, multi-step charts, or doc evaluation).
- Pondering mode off: Offers sooner and direct solutions for normal lookups or easy Q&As. Customers can management the depth of inference in a mannequin with inference and stability interpretability and rigor.
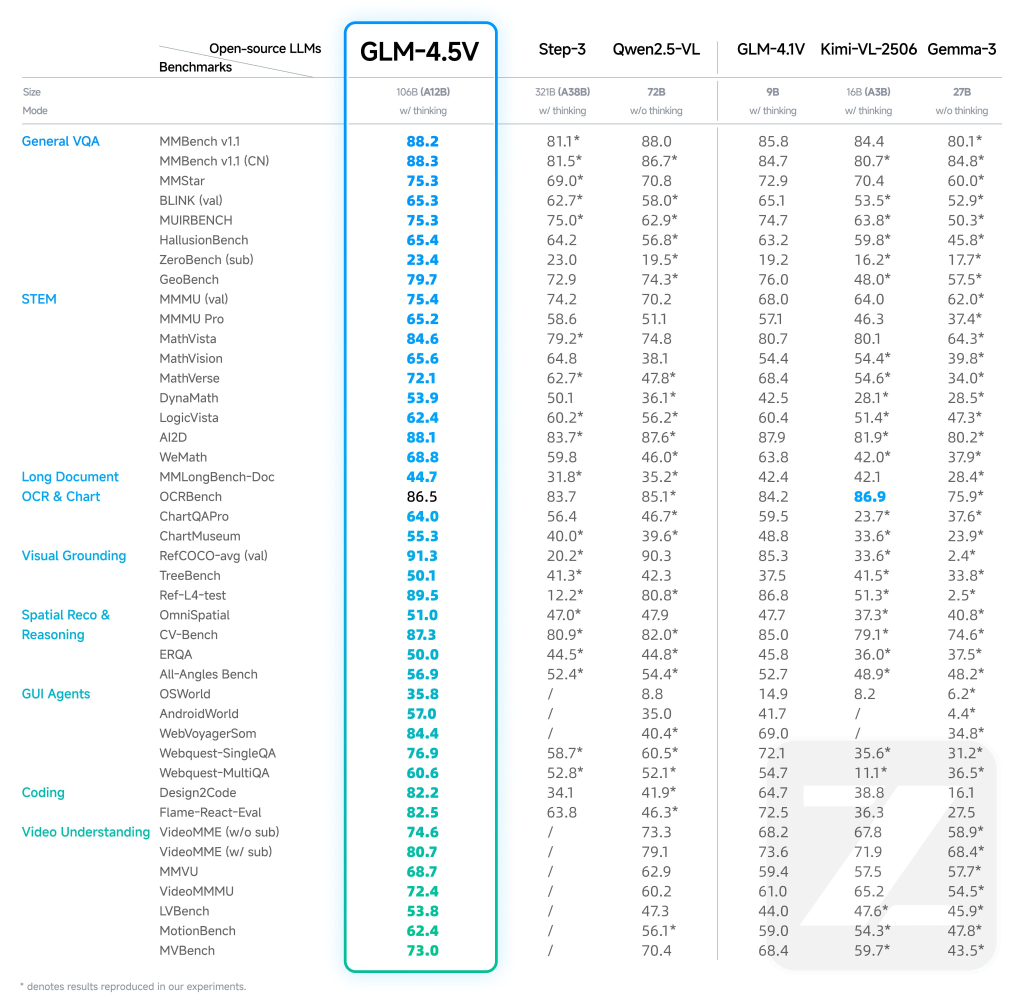
Benchmark efficiency and real-world impression
- Chopping-edge outcomes: The GLM-4.5V achieves SOTA past 41-42 public multimodal benchmarks, together with MMBench, AI2D, MMSTAR, and Mathvista, surpassing each open and premium proprietary fashions in classes similar to STEM QA, chart understanding, GUI operation, and video understanding.
- Sensible growth: Corporations and researchers report their conversion outcomes to defect detection, automated report evaluation, digital assistant creation and accessibility expertise utilizing GLM-4.5V.
- Multimodal AI democratization: Open sourced below the MIT license, this mannequin equals entry to cutting-edge multimodal inference, beforehand gated by its personal API.
Examples of use instances
| Options | I will use it | clarification |
|---|---|---|
| Picture reasoning | Defect detection, content material moderation | Understanding the scene, summarizing a number of photographs |
| Video Evaluation | Monitoring, content material creation | Lengthy video segmentation, occasion recognition |
| GUI Duties | Accessibility, automation, QA | Display screen/UI studying, icon location, operation strategies |
| Chart evaluation | Funding, analysis reviews | Visible evaluation, information extraction from advanced charts |
| Doc Evaluation | Legislation, insurance coverage, science | Analyze and summarise a protracted library |
| floor | AR, Retail, Robotics | Goal object localization, spatial reference |
abstract
The GLM-4.5V with Zhipu AI is a flagship open supply imaginative and prescient language mannequin that units new efficiency and usefulness requirements for multimodal inference. With its highly effective structure, context size, real-time “pondering modes” and a variety of purposeful spectra, the GLM-4.5V redefines what is feasible for companies, researchers and builders working on the intersection of imaginative and prescient and language.
Please test paper, Model hugging her face and The GitHub page is here. Please be at liberty to test GitHub pages for tutorials, code and notebooks. Additionally, please be at liberty to observe us Twitter And remember to hitch us 100k+ ml subreddit And subscribe Our Newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, ASIF is dedicated to leveraging the chances of synthetic intelligence for social advantages. His newest efforts are the launch of MarkTechPost, a man-made intelligence media platform. That is distinguished by its detailed protection of machine studying and deep studying information, and is simple to know by a technically sound and extensive viewers. The platform has over 2 million views every month, indicating its recognition amongst viewers.

{kind=link}