


We sit up for right this moment to announce the launch of the Amazon Sagemaker Giant-Scale Mannequin Inference (LMI) Container V15, which helps the VLLM V1 engine and options VLLM 0.8.4. This model helps the newest open supply fashions, together with Meta’s Llama 4 Fashions Scout, Maverick, Google’s Gemma 3, Alibaba’s Qwen, Mistral AI, and Deepseek-R. Amazon Sagemaker AI continues to evolve generative AI inference capabilities to satisfy the rising demand for fundamental fashions (FMS) efficiency and mannequin assist.
This launch introduces important efficiency enhancements, elevated mannequin compatibility with multimodality (i.e. the flexibility to grasp and analyze text-to-text, image-to-text, and textual content knowledge), and offers built-in integration with VLLM to deploy seamlessly at massive efficiency and ship efficiency at scale.
what’s new?
The LMI V15 brings a number of enhancements that enhance throughput, latency and usefulness.
- Asynchronous mode that integrates straight with VLLM’s AsyncllMengine for improved request dealing with. This mode creates a extra environment friendly background loop that repeatedly processes incoming requests, permitting a number of concurrent requests and stream output to be processed at increased throughput than earlier rolling batch implementations of V14.
- Assist for VLLM V1 engines. This affords as much as 111% throughput in comparison with earlier V0 engines for smaller fashions with excessive concurrency. This efficiency enchancment comes from diminished CPU overhead, optimized execution paths, and extra environment friendly useful resource utilization within the V1 structure. The LMI V15 helps each the V1 and V0 engines, and V1 is the default. If it’s essential use V0, you should use the V0 engine by specifying it
VLLM_USE_V1=0. The VLLM V1 engine additionally comes with core reorganization of the serving engine with easy scheduling, zero-overhead prefix caching, clear tensor parallel inference, environment friendly enter preparation, and superior optimization with TORCH.comPile and Flash consideration. For extra data, please see VLLM Blog. - Enhanced API schema assist with three versatile choices that enable for seamless integration with functions constructed on fashionable API patterns:
- The message format is suitable with Openai Chat completion API.
- OpenAI full format.
- A Textual content Technology Inference (TGI) schema that helps backward compatibility with older fashions.
- Multimodal assist with enhancements to imaginative and prescient language fashions together with optimizations akin to multimodal prefix caches
- Constructed-in assist for useful and power calls that allows refined agent-based workflows.
Enhanced mannequin assist
The LMI V15 helps a broad roster of cutting-edge fashions, together with the newest releases from main mannequin suppliers. Containers present instantaneous compatibility, however should not restricted to, for the next causes:
- Llama 4 -llama-4-scout-17b-16e and llama-4-maverick-17b-128e-instruct
- Gemma 3 – Google’s light-weight and environment friendly mannequin, recognized for its small measurement however highly effective efficiency
- Qwen 2.5 – Superior fashions from Alibaba together with QWQ 2.5 and QWEN2-VL with multimodal options
- Mistral AI Mannequin – Excessive-performance mannequin of Mistral AI that gives environment friendly scaling and particular options
- deepseek-r1/v3 – The leading edge inference mannequin
Every mannequin household might be deployed utilizing an LMI V15 container by specifying the suitable mannequin ID, akin to Meta-lama/Llama-4-Scout-17E, for instance Meta-lama-4-Scout-17B-16E, and configuration parameters as surroundings variables, with out the necessity for customized code or optimization work.
benchmark
Our benchmarks present the efficiency advantages of the LMI V15’s V1 engine in comparison with earlier variations.
| Mannequin | Batch measurement | Occasion Sort | LMI V14 Throughput [tokens/s] (V0 engine) | LMI V15 Throughput [tokens/s] (V1 engine) | Enhancements | |
| 1 | deepseek-ai/deepseek-r1-distill-llama-70b | 128 | P4D.24XLARGE | 1768 | 2198 | twenty 4% |
| 2 | Metalama/llama-3.1-8b-instruct | 64 | ml.g6e.2xlarge | 1548 | 2128 | 37% |
| 3 | Mistralai/Mistral-7B-Instruct-V0.3 | 64 | ml.g6e.2xlarge | 942 | 1988 | 111% |
Deepseek-r1 llama 70b Varied ranges of concurrency
llama 3.1 8b Directions for various ranges of concurrency
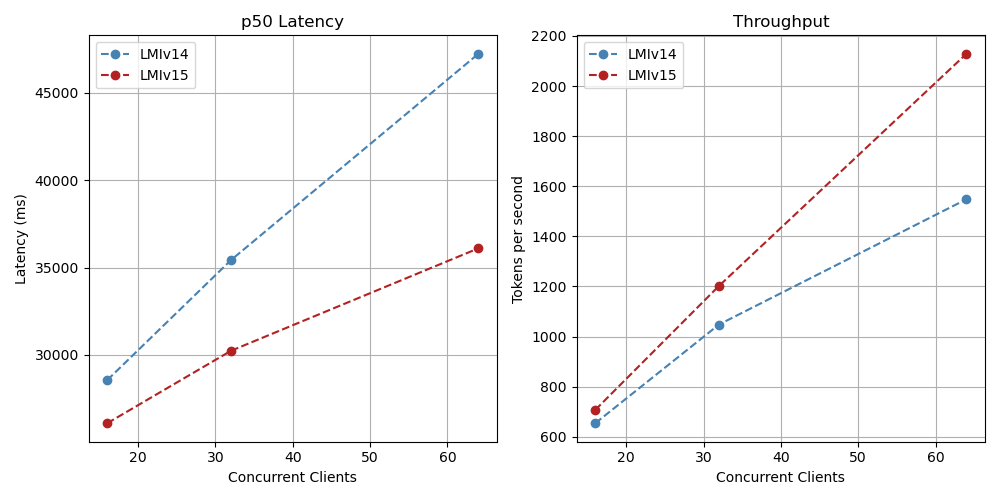
Mistral 7B with totally different ranges of concurrency

The ASYNC engine of the LMI V15 exhibits the energy of excessive present situations the place a number of simultaneous requests profit from optimized request dealing with. These benchmarks spotlight that the ASYNC mode V1 engine affords 24% to 111% increased throughput in comparison with the LMI V14 utilizing rolling batches in fashions examined in excessive parallel situations with batch sizes of 64 and 128.
- Bigger batch sizes enhance concurrency, however comes with a pure trade-off by way of latency
- Batch sizes of 4 and eight present optimum latency for many use circumstances
- Batch sizes as much as 64 and 128 obtain most throughput with acceptable latency sheet laid-off
API format
LMI V15 helps three API schemas: Openai Chat Completion, Openai Completion, and TGI.
- Chat completion – Message format is suitable with Openai Chat completion API. Use this schema for software invocations, inferences, and multimodal use circumstances. This can be a pattern name utilizing the Message API.
- OpenAI full format – Completion API endpoints now not obtain updates.
- TGI – Helps backward compatibility with older fashions.
Get began with the LMI V15
Beginning an LMI V15 is seamless and might be expanded with a number of traces of code in LMI V15. Containers can be found from the Amazon Elastic Container Registry (Amazon ECR) and deployments might be managed through Sagemaker AI Endpoints. To deploy a mannequin, you need to specify future face mannequin ID, occasion kind, and configuration choices as surroundings variables.
For optimum efficiency, we suggest the next cases:
- Llama 4 Scout: ml.p5.48xlarge
- Deepseek R1/V3: ML.P5E.48XLARGE
- QWEN 2.5 VL-32B: ML.G5.12XLARGE
- QWEN QWQ 32B: ML.G5.12XLARGE
- Mistral Giant: Ml.G6E.48XLARGE
- GEMMA3-27B: ML.G5.12XLARGE
- llama 3.3-70b: ml.p4d.24xlarge
To deploy on an LMI V15, observe these steps:
- Create a clone Notes For Amazon Sagemaker Studio Pocket book or Visible Studio Code (VS Code). You may then run the pocket book to run the preliminary setup and deploy it from the face repository the place you hug the mannequin to the Sege Maker AI endpoint. Right here we stroll by way of the important thing blocks.
- LMI V15 makes use of surroundings variables of format to take care of the identical configuration sample as earlier variations
OPTION_<CONFIG_NAME>. This constant method makes it simpler for customers accustomed to earlier LMI variations emigrate to V15.HF_MODEL_IDSet the mannequin ID from the face you hug. You can too obtain fashions from Amazon Easy Storage Service (Amazon S3).HF_TOKENSet the token and obtain the mannequin. That is required for gate fashions akin to Llama-4OPTION_MAX_MODEL_LEN. That is the utmost mannequin context size.OPTION_MAX_ROLLING_BATCH_SIZEUnits the batch measurement of the mannequin.OPTION_MODEL_LOADING_TIMEOUTSet the Sagemaker timeout worth to load the mannequin and run a well being verify.SERVING_FAIL_FAST=true. It is strongly recommended to set this flag as Sagemaker can gracefully restart the container when an irrecoverable engine error happens.OPTION_ROLLING_BATCH= disableDisables the default provision of LMI rolling batch implementation in LMI V14. I like to recommend utilizing ASYNC as this newest implementation as an alternative, bettering efficiencyOPTION_ASYNC_MODE=trueAllow Async mode.OPTION_ENTRYPOINTOffers entry factors for asynchronous integration of VLLM
- Arrange the newest container (on this instance, I used it
0.33.0-lmi15.0.0-cu128), AWS Area (us-east-1), and create mannequin artifacts on all configurations. To see the newest obtainable container variations, see Available deep learning container images. - Deploy to endpoints utilizing the mannequin
mannequin.deploy(). - When calling a mannequin, Sagemaker inference offers two APIs to invoke the mannequin –
InvokeEndpointandInvokeEndpointWithResponseStream. You may select one of many choices based mostly in your wants.
To carry out multimodal inference in llama-4 scouts, see Notes The whole code pattern makes use of the picture to carry out the inference request.
Conclusion
The Amazon Sagemaker LMI Container V15 represents a significant advance within the large-scale mannequin inference capabilities. The brand new VLLM V1 engine, ASYNC working modes, prolonged mannequin assist and optimized efficiency enable for improved efficiency and adaptability to deploy cutting-edge LLM. Container configurable choices present the flexibleness to fine-tune your deployment to your particular wants, whether or not optimized for latency, throughput, or value.
We suggest exploring this launch to deploy generated AI fashions.
Please verify A notebook example was provided Begin deploying the mannequin with the LMI V15.
In regards to the creator
 Vivek Gangasani Lead Specialist Answer Architect for AWS Inference. He makes use of AWS providers and accelerated computing to assist new era AI corporations construct progressive options. At the moment he focuses on creating methods to fine-tune and optimize the inference efficiency of large-scale language fashions. Throughout his free time, Vivek hikes, watches motion pictures and experiments with a wide range of dishes.
Vivek Gangasani Lead Specialist Answer Architect for AWS Inference. He makes use of AWS providers and accelerated computing to assist new era AI corporations construct progressive options. At the moment he focuses on creating methods to fine-tune and optimize the inference efficiency of large-scale language fashions. Throughout his free time, Vivek hikes, watches motion pictures and experiments with a wide range of dishes.
 Siddharth Venkatesan I’m a software program engineer at AWS Deep Studying. He’s at present specializing in constructing options for large-scale mannequin inference. Earlier than AWS, he had constructed new fee capabilities for patrons all over the world with Amazon Grocery Org. Exterior of labor, he enjoys snowboarding, the outside and watching sports activities.
Siddharth Venkatesan I’m a software program engineer at AWS Deep Studying. He’s at present specializing in constructing options for large-scale mannequin inference. Earlier than AWS, he had constructed new fee capabilities for patrons all over the world with Amazon Grocery Org. Exterior of labor, he enjoys snowboarding, the outside and watching sports activities.
 Felipe Lopez I’m AWS Senior AI/ML Specialist Answer Architect. Previous to becoming a member of AWS, Felipe labored with GE Digital and SLB to give attention to industrial software modeling and optimization merchandise.
Felipe Lopez I’m AWS Senior AI/ML Specialist Answer Architect. Previous to becoming a member of AWS, Felipe labored with GE Digital and SLB to give attention to industrial software modeling and optimization merchandise.
 Banu Nagasundaram Main merchandise, engineering and strategic partnerships for Amazon Sagemaker Jumpstart, Sagemaker Machine Studying, and Generative AI Hub. She is obsessed with constructing options that assist clients speed up their AI journey and unlock enterprise worth.
Banu Nagasundaram Main merchandise, engineering and strategic partnerships for Amazon Sagemaker Jumpstart, Sagemaker Machine Studying, and Generative AI Hub. She is obsessed with constructing options that assist clients speed up their AI journey and unlock enterprise worth.
 Dmitry soldatkin A senior AI/ML Options Architect at Amazon Internet Providers (AWS), serving to clients design and construct AI/ML options. Dmitry’s work covers a variety of ML use circumstances and has a significant curiosity in producing AI, deep studying, and scaling ML throughout the enterprise. He has supported corporations in lots of industries, together with insurance coverage, monetary providers, utility and telecommunications. Could be related to the dormitory LinkedIn.
Dmitry soldatkin A senior AI/ML Options Architect at Amazon Internet Providers (AWS), serving to clients design and construct AI/ML options. Dmitry’s work covers a variety of ML use circumstances and has a significant curiosity in producing AI, deep studying, and scaling ML throughout the enterprise. He has supported corporations in lots of industries, together with insurance coverage, monetary providers, utility and telecommunications. Could be related to the dormitory LinkedIn.

{kind=link}