


Pattern language mannequin responses to completely different types of English and native speaker responses.
ChatGPT is amazingly good at speaking with folks in English. However whose English?
Only 15% 70% of ChatGPT customers are from the US, the place Commonplace American English is the default, however the mannequin can be well-liked in international locations and communities that talk different English variants: over 1 billion folks worldwide converse Indian English, Nigerian English, Irish English, African American English, and different variants.
Audio system of those non-“commonplace” dialects typically face discrimination in the true world. They are saying that their approach of talking is Non-professional or Incorrect, Lost credibility as a witnessand Housing refusal-in spite of Widespread the study It exhibits that each one language variants are equally advanced and legit. Discrimination towards speech is usually a proxy for discrimination towards race, ethnicity, or nationality. What if ChatGPT exacerbates this discrimination?
To reply this query, Recent Publications We look at how ChatGPT’s conduct adjustments in response to a variety of English texts. We discover that ChatGPT’s responses persistently show widespread bias towards non-‘commonplace’ language, together with elevated stereotyping and insults, diminished comprehension, and condescending responses.
Our Analysis
We fed each GPT-3.5 Turbo and GPT-4 textual content with 10 types of English: two “commonplace” types of English, Commonplace American English (SAE) and Commonplace British English (SBE), and eight non-“commonplace” types of English, African-American, Indian, Irish, Jamaican, Kenyan, Nigerian, Scottish, and Singaporean. We then in contrast the language mannequin responses to the “commonplace” and non-“commonplace” types of English.
First, we needed to know whether or not the linguistic options of the variants current in a immediate have been preserved in GPT-3.5 Turbo’s responses to that immediate. We annotated the prompts and mannequin responses with the linguistic options of every variant and whether or not it makes use of American or British spelling (e.g., “color” or “practise”). This helps us perceive when ChatGPT mimics a variant and what elements affect the diploma of mimicry.
We then requested native audio system of every variant to price the mannequin’s responses on a variety of each qualities (e.g., heat, understanding, naturalness) and damaging qualities (e.g., stereotypic, degrading, condescending). Right here, along with the unique GPT-3.5 responses, we included responses from GPT-3.5 and GPT-4, the place the mannequin was instructed to imitate the model of the enter.
consequence
We anticipated ChatGPT to generate commonplace American English by default, because the mannequin was developed in the US and commonplace American English is probably going the dialect finest represented within the coaching information. Certainly, the mannequin’s responses protect way more SAE options than non-“commonplace” dialects (by over 60%). Nonetheless, surprisingly, the mannequin do It does mimic different English variants, however not persistently: in actual fact, it mimics extra generally spoken variants (reminiscent of Nigerian or Indian English) extra typically than much less generally spoken variants (reminiscent of Jamaican English), suggesting that the composition of the coaching information influences responses to non-standard dialects.
ChatGPT additionally defaults to US conventions in ways in which could frustrate non-US customers: for instance, the mannequin’s response to enter with British spelling (the default in most international locations outdoors the US) nearly universally reverts to US spelling, which can hinder a good portion of ChatGPT’s consumer base by ChatGPT’s incapacity to accommodate native spelling conventions.
The mannequin responses are persistently biased towards varieties apart from the “commonplace.” The default GPT-3.5 responses to non-“commonplace” variants persistently exhibit a variety of points: stereotyping (19% worse than the “commonplace” variant), demeaning content material (25% worse), lack of know-how (9% worse), and condescending responses (15% worse).
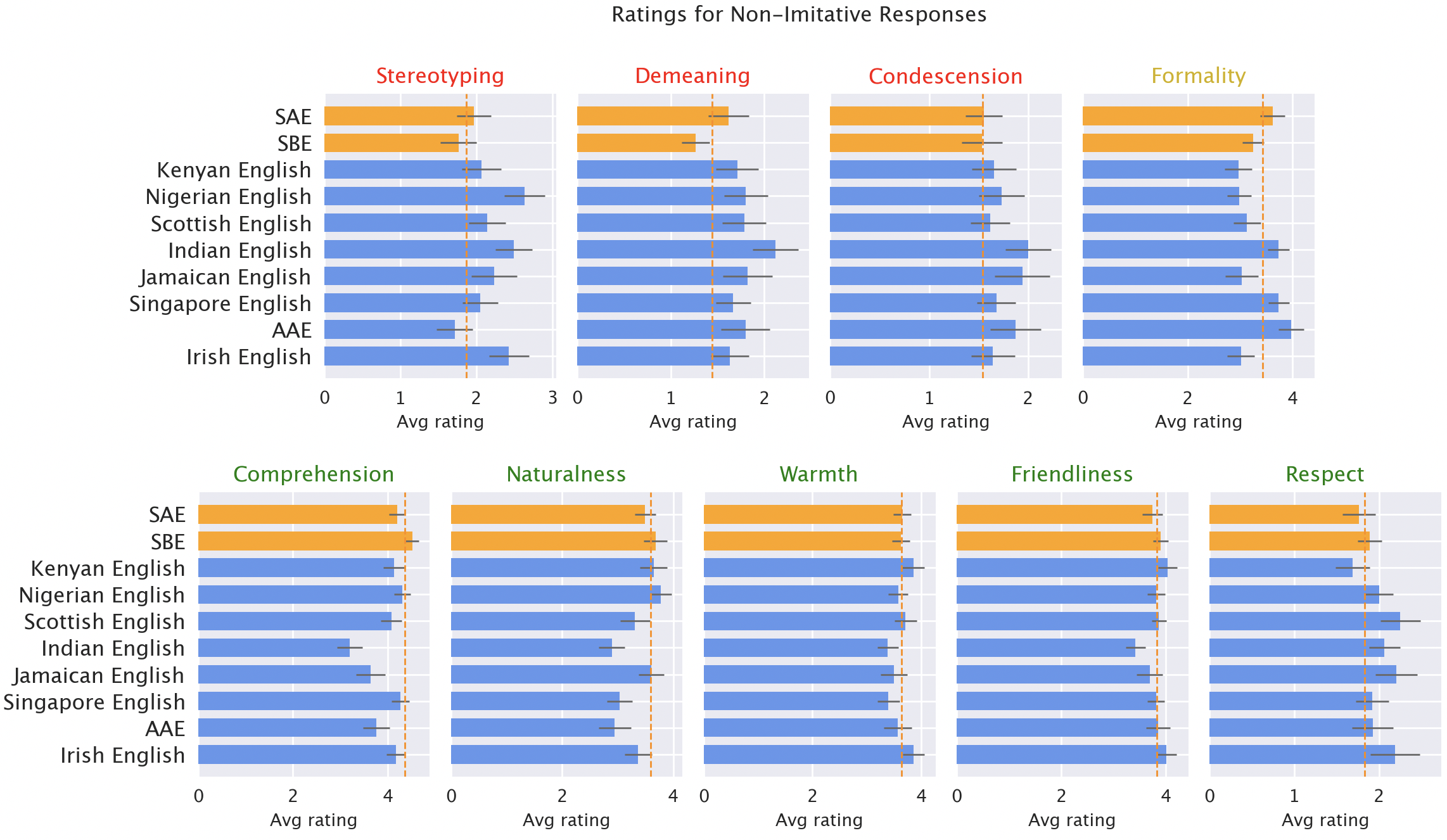
Native speaker scores of mannequin responses. Responses to the non-‘commonplace’ variants (blue) have been rated worse than responses to the ‘commonplace’ variants (orange) when it comes to stereotypy (19% worse), insulting content material (25% worse), understanding (9% worse), naturalness (8% worse) and condescension (15% worse).
When GPT-3.5 is prompted to imitate the enter dialect, the responses exacerbate stereotypic content material (9% worse) and incomprehension (6% worse). As a result of GPT-4 is a more moderen and extra highly effective mannequin than GPT-3.5, we anticipate it to enhance over GPT-3.5. Nonetheless, whereas GPT-4 responses that mimic the enter enhance over GPT-3.5 in heat, understanding, and familiarity, they exacerbate stereotyping (14% worse than GPT-3.5 for minority variants). This means that bigger and newer fashions don’t mechanically remedy dialect discrimination; in actual fact, they could exacerbate dialect discrimination.
Implications
ChatGPT could perpetuate linguistic discrimination towards individuals who converse non-“commonplace” dialects. If these customers have a tough time being understood by ChatGPT, it should make these instruments more durable to make use of. As AI fashions are more and more utilized in on a regular basis life, this might strengthen boundaries for individuals who converse non-“commonplace” dialects.
Furthermore, stereotyping and derogatory responses perpetuate the concept audio system of dialects apart from the “commonplace” don’t converse accurately and usually are not worthy of respect. As using language fashions will increase globally, there’s a danger that these instruments will reinforce energy constructions that hurt minority language communities and amplify inequalities.
For extra info, please see: [ paper ]

{kind=link}