


Be aware: The earlier article We offer a sensible dialogue of why Bayesian modeling could also be your best option in your process.
This tutorial focuses on the workflow and code walkthrough for constructing a Bayesian regression mannequin. StanSTAN, a probabilistic programming language, is broadly adopted and interfaces along with your language of selection (R, Python, shell, MATLAB, Julia, Stata). install Information and document.
I exploit Pistan On this tutorial, I’m merely coding in Python, however the normal Bayesian practices and STAN language syntax described right here is not going to change considerably should you use a special language.
For the extra sensible readers, right here is the hyperlink. Notes This tutorial is a part of the Bayesian Modeling Workshop at Northwestern College (April 2024).
Let’s get began!
Learn to construct a easy Bayesian linear regression mannequin, essential for any statistician. Given a dependent variable: sure and covariates XI counsel a easy mannequin:
sure = α + β * X + ϵ
the place ⍺ is the intercept, β is the slope, and ϵ is the random error.
ϵ ~ regular distribution(0, σ)
We will present that
sure ~ Regular distribution (α + β * X, σ)
You’ll discover ways to code this mannequin kind in STAN.
Generate Information
First, let’s generate some pretend knowledge.
#Mannequin Parameters
alpha = 4.0 #intercept
beta = 0.5 #slope
sigma = 1.0 #error-scale
#Generate pretend knowledge
x = 8 * np.random.rand(100)
y = alpha + beta * x
y = np.random.regular(y, scale=sigma) #noise
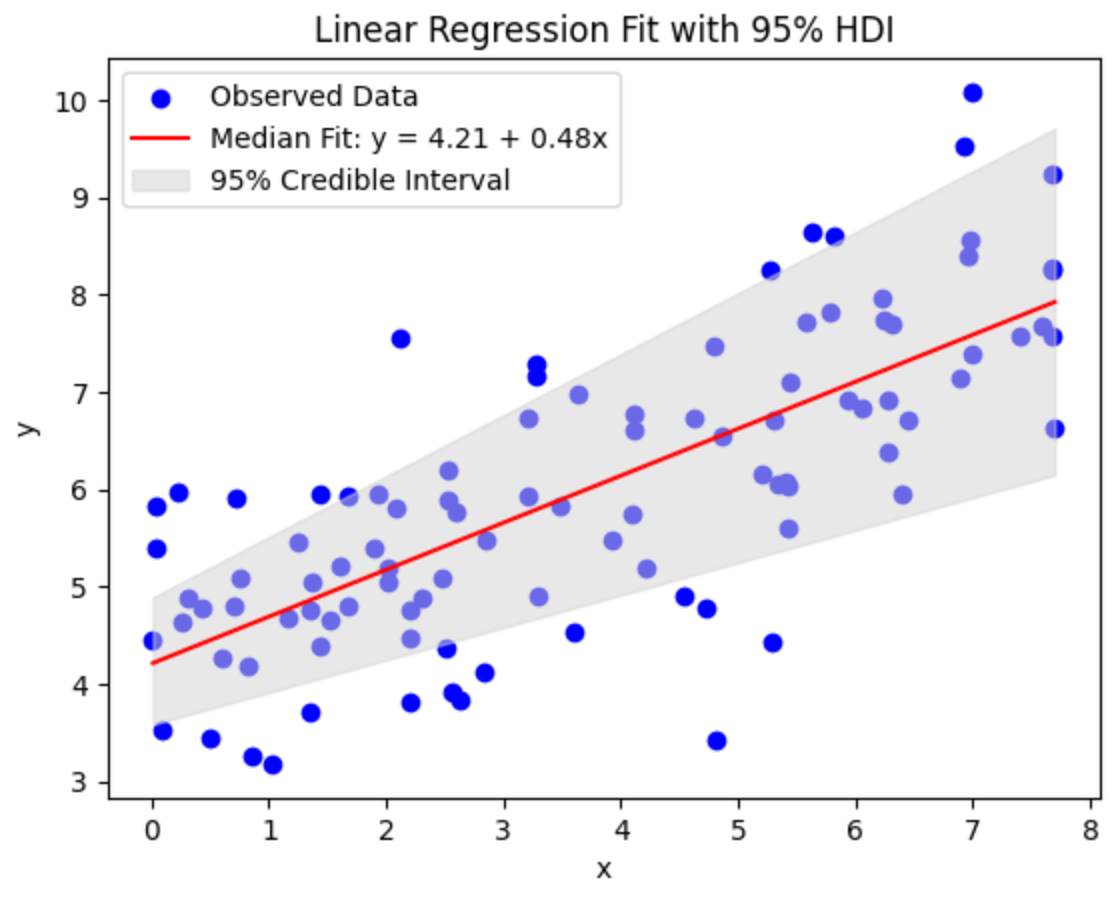
#visualize generated knowledge
plt.scatter(x, y, alpha = 0.8)

Now that we now have the info to mannequin, let’s examine easy methods to construction it and move it to STAN together with modeling directions. That is Mannequin A string often consists of 4 blocks (typically extra). knowledge, Parameters, Mannequinand Generated amountAllow us to focus on every of those blocks intimately.
Information Blocks
knowledge { //enter the info to STAN
int<decrease=0> N;
vector[N] x;
vector[N] y;
}
of knowledge Blocks are most likely the best, they simply inform the STAN internals what knowledge to anticipate and in what format. For instance, right here we move within the following:
no: The scale (kind) of the dataset integer. <下=0> The half declares N ≥ 0. (Clearly, the info size can by no means be detrimental, however specifying these bounds is an ordinary observe to make working with STAN simpler.)
x: Signify the covariates as vectors of size N.
Yeah: Signify the dependent variables as vectors of size N.
look Documentation here Full vary of supported knowledge sorts. STAN helps a variety of sorts similar to arrays, vectors, matrices, and so on. As we noticed above, STAN additionally helps encoding. restrict About variables. We advocate encoding the restrictions, as this creates a greater specified mannequin and simplifies the stochastic sampling course of that’s carried out internally.
Mannequin Blocks
Subsequent Mannequin Within the block, you inform STAN the construction of your mannequin.
//easy mannequin block
mannequin {
//priors
alpha ~ regular(0,10);
beta ~ regular(0,1); //mannequin
y ~ regular(alpha + beta * x, sigma);
}
Mannequin blocks additionally include vital, and infrequently complicated, components. earlier than Specification. The prior distribution is Typical It’s a part of Bayesian modelling and must be correctly specified in your sampling process.
Final time article A primer on the function and instinct behind prior possibilities. To summarize: earlier than That is the useful kind that’s assumed for the distribution of parameter values, and is just Prior beliefsAdvance don’t Precisely Match As a ultimate resolution, they gave us pattern From there.
On this instance, we use a traditional distribution with imply 0, with totally different variances relying on how assured we’re of a given imply: 10 for alpha (very uncertain) and 1 for beta (considerably assured). perception Alpha can tackle a variety of various values, however the slope is mostly restricted and won’t scale to massive values.
So within the above instance, the prior chance for alpha is “weaker” than for beta.
As fashions turn out to be extra advanced, the sampling resolution area expands and it turns into vital to offer beliefs. In any other case, until you will have a robust instinct, it’s higher to not give an excessive amount of perception to the mannequin. That’s, The quantity of data is weak Put together prematurely and be versatile in responding to incoming knowledge.
As you might already know, the type of y is an ordinary linear regression equation.
Quantity produced
Lastly, our block is Quantity producedNow we inform STAN what quantity we need to calculate and obtain as output.
generated portions { //get portions of curiosity from fitted mannequin
vector[N] yhat;
vector[N] log_lik;
for (n in 1:N) alpha + x[n] * beta, sigma);
//chance of knowledge given the mannequin and parameters
}
NOTE: STAN helps passing vectors into the equations both immediately or as a 1:N iteration for every component n. In observe, I’ve discovered that this assist varies between variations of STAN, so if the vectorized model fails to compile, I counsel making an attempt the iteration declaration.
Within the above instance,
sure: Generate samples of y from the fitted parameter values.
Just like the log: Generates possibilities for the info primarily based on the mannequin and fitted parameter values.
The aim of those values will turn out to be clearer after we focus on mannequin analysis.
Total, we now have absolutely specified our first naive Bayesian regression mannequin.
mannequin = """
knowledge { //enter the info to STAN
int<decrease=0> N;
vector[N] x;
vector[N] y;
}
parameters {
actual alpha;
actual beta;
actual<decrease=0> sigma;
}mannequin {
alpha ~ regular(0,10);
beta ~ regular(0,1);
y ~ regular(alpha + beta * x, sigma);
}generated portions {
vector[N] yhat;
vector[N] log_lik;for (n in 1:N) alpha + x[n] * beta, sigma);
}
"""
All that is left is to compile the mannequin and run the sampling.
#STAN takes knowledge as a dict
knowledge = {'N': len(x), 'x': x, 'y': y}
STAN receives enter knowledge within the type of a dictionary, it is vital that this dictionary accommodates all of the variables you advised STAN to anticipate within the mannequin knowledge block, in any other case the mannequin is not going to compile.
#parameters for STAN becoming
chains = 2
samples = 1000
warmup = 10
# set seed
# Compile the mannequin
posterior = stan.construct(mannequin, knowledge=knowledge, random_seed = 42)
# Practice the mannequin and generate samples
match = posterior.pattern(num_chains=chains, num_samples=samples)The .pattern() technique parameters management the Hamiltonian Monte Carlo (HMC) sampling course of, the place —
- Variety of Chains: The variety of instances to repeat the sampling course of.
- Variety of samples: The variety of samples to be taken in every chain.
- heat up: The variety of preliminary samples to discard (as a result of it takes a very long time to achieve a top level view of the answer area).
Figuring out the suitable values for these parameters depends upon each the complexity of the mannequin and the accessible assets.
After all, a bigger sampling measurement is right, but when the mannequin shouldn’t be correctly specified, it’s going to solely waste time and computation. In my expertise, I’ve needed to wait per week for a big knowledge mannequin to complete working solely to seek out that the mannequin by no means converged. You will need to begin sluggish and examine the validity of the mannequin earlier than performing full-scale sampling.
Mannequin analysis
The quantity produced is
- The goodness of match, i.e., convergence, is evaluated.
- prediction
- Examine Fashions
convergence
Step one in evaluating a mannequin in a Bayesian framework is visible. Hamilton Monte Carlo (HMC) Sampling course of.

In easy phrases, STAN repeatedly samples and evaluates parameter values (HMC doesn’t). technique We wish to extract extra samples, however that’s at the moment past our scope. Converge Ideally in a typical world space Optimum.
The determine above exhibits a sampling of the mannequin throughout two impartial chains (crimson and blue).
- On the left, we see the general distribution of the fitted parameter values, i.e. rear finish. we, often The mannequin and its parameters are Effectively specified. (why What’s it? A standard distribution means that there’s a vary of values that most closely fits the parameters, which helps our selection of mannequin kind. Moreover, a major Duplicate Past the Chain if The mannequin converges to the optimum.
- On the precise, we plot the precise samples drawn at every iteration ( Further Certainly.) Right here once more, we slender Not solely the vary, however many Duplicate Through the draw.
Not all analysis metrics are visible. Gelman et al. [1] Additionally, Rat The diagnostic is actually a mathematical measure of pattern similarity between chains. Rhat permits us to outline a cutoff level the place two chains are deemed too totally different to converge; nevertheless, the iterative nature of the method and the variable warm-up interval make the cutoff tough to outline.
Due to this fact, visible comparability is a vital issue whatever the diagnostic check.
The frequentist thought right here is, “If all we now have is chains and distributions, what are the precise parameter values?” That is precisely the purpose. The Bayesian formulation is distributiondo not need level Estimates primarily based on check statistics which might be tough to interpret.
That being mentioned, the posterior distribution might be summarized as follows: Reliable The interval is Excessive Density Interval (HDI)) accommodates all of the x% highest chance density factors.

You will need to distinction with Bayesian statistics Reliable Frequentist intervals Confidence interval.
- The boldness interval is chance distribution Doable values for Parameters That’s, the chance {that a} parameter will assume every worth in a selected interval, given the info.
- The boldness interval is Parameters As a price Repairedand as a substitute, repetition random sampling Information Match.
subsequently
Whereas the Bayesian strategy permits parameter values to be in flux and takes the info at face worth, the frequentist strategy requires that there be one true parameter worth… if we had entry to all the info that has ever existed.
Phew. Learn that once more till you perceive it higher.
Use confidence intervals, in different phrases, to estimate the parameters variablethe predictions we make seize this. Uncertainty and TransparencyA selected HDI % provides you with the road of greatest match.

Examine Fashions
Within the Bayesian framework, the Watanabe-Akaike info (WAIC) rating is a broadly accepted selection for mannequin comparability. A easy clarification of the WAIC rating is that it estimates the mannequin. Risk in the meantime Regularization Relying on the variety of parameters within the mannequin, the Bayesian strategy adjusts the variety of mannequin parameters. In easy phrases, it lets you take overfitting under consideration. That is additionally an enormous attraction of the Bayesian strategy. do not need Inevitably want Current the mannequin verification Information set. Due to this fact,
Bayesian modeling presents vital benefits when knowledge are scarce.
WAIC rating is Comparatively That’s, it solely has which means compared between totally different fashions that designate the identical underlying knowledge. So, in observe, you possibly can hold including extra complexity to your mannequin so long as the WAIC will increase. If at any level on this technique of including insane complexity the WAIC begins to drop, then you possibly can name it a day. Any extra complexity gives no informational benefit in explaining the underlying knowledge distribution.
Conclusion
To summarize, a STAN mannequin block is only a string of characters that tells STAN what to move to it (the mannequin), what to search for (the parameters), what to anticipate to occur (the mannequin), and what to return (how a lot to supply).
When powered on, STAN produces energy by turning the crank.
The true problem lies in defining an applicable mannequin (see priors), structuring the info appropriately, asking STAN precisely what we want, and assessing the validity of its output.
As soon as we perceive this half, we are able to dive into the true energy of STAN: it makes specifying more and more advanced fashions a easy syntactic process. The truth is, within the subsequent tutorial, we’ll do precisely that: we’ll discover Bayesian regression, constructing on this straightforward regression instance. Hierarchical Fashions: trade normal, state-of-the-art, de facto… you identify it. See easy methods to add group-level random or mounted results to your fashions and marvel at how simply you possibly can add complexity whereas sustaining comparability in a Bayesian framework.
In the event you discovered this text useful, subscribe and keep tuned for extra!
References
[1] Andrew Gellman, John B. Carlin, Hal S. Stern, David B. Danson, Aki Betari, and Donald B. Rubin (2013). Bayesian Information Evaluation, third Version.Chapman and Corridor/CRC.

{kind=link}