


A serious development in synthetic intelligence, multimodal large-scale language fashions (MLLMs) mix language understanding with visible understanding to supply extra correct representations of multimodal inputs. By integrating knowledge from a number of sources, corresponding to textual content and pictures, these fashions enhance their understanding of complicated relationships between totally different modalities. This integration permits superior duties that require an intensive understanding of many sorts of knowledge. Because of this, MLLMs have change into a key space of curiosity for contemporary AI analysis.
A key problem in multimodal studying is reaching an efficient illustration of multimodal data. Present analysis contains frameworks corresponding to CLIP, which makes use of contrastive studying of image-text pairs to match visible and language representations. Fashions corresponding to BLIP, KOSMOS, LLaMA-Adapter, and LLaVA prolong LLM to deal with multimodal data. These strategies usually use separate encoders for textual content and pictures, leading to poor integration of interleaved inputs. Moreover, they require intensive and dear multimodal coaching knowledge to assist in complete language understanding and complicated visual-language duties, and have but to realize common and environment friendly multimodal embeddings.
To deal with these limitations, researchers from Beihang College and Microsoft launched the E5-V framework, designed to adapt MLLM to common multimodal embeddings. This progressive strategy leverages unimodal coaching of textual content pairs, considerably decreasing coaching prices and eliminating the necessity for multimodal knowledge assortment. By specializing in textual content pairs, the E5-V framework achieves considerably improved illustration of multimodal inputs in comparison with conventional strategies, making it a promising different for future developments on this subject.
The E5-V framework employs a novel prompt-based illustration methodology to unify multimodal embeddings right into a single area. Throughout coaching, the mannequin solely makes use of textual content pairs, simplifying the method and decreasing the prices related to accumulating multimodal knowledge. The important thing innovation is to instruct MLLM to symbolize multimodal inputs as phrases, successfully eliminating the modality hole. This methodology permits the mannequin to deal with extremely correct duties corresponding to artificial picture retrieval. By unifying totally different embeddings into the identical area primarily based on which means, the E5-V framework makes multimodal representations extra sturdy and versatile.
E5-V has demonstrated wonderful efficiency in quite a lot of duties, together with textual content picture retrieval, artificial picture retrieval, sentence embedding, and picture picture retrieval. The framework outperforms state-of-the-art fashions in a number of benchmarks. For instance, within the zero-shot picture retrieval process, E5-V outperforms CLIP ViT-L by 12.2% on Flickr30K and 15.0% on COCO with Recall@1, demonstrating its superior skill to combine visible and linguistic data. Moreover, E5-V considerably improves the artificial picture retrieval process, outperforming the present state-of-the-art methodology, iSEARLE-XL, on the CIRR dataset by 8.50% in Recall@1 and 10.07% in Recall@5. These outcomes spotlight the effectiveness of the framework in precisely representing interleaved inputs and complicated interactions.
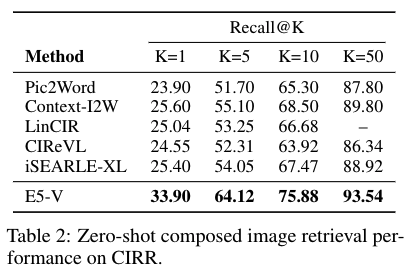
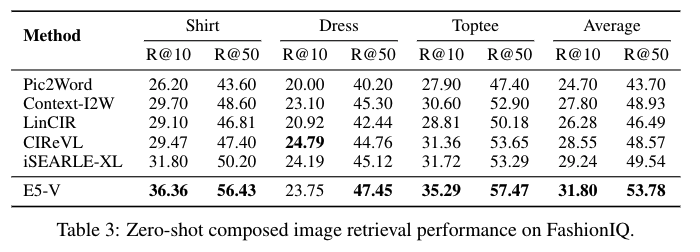
The researchers carried out intensive experiments to validate the effectiveness of E5-V. In textual content and picture retrieval duties, E5-V achieved aggressive efficiency on the Flickr30K and COCO datasets. For instance, E5-V confirmed a Recall@10 of 98.7% on Flickr30K, outperforming fashions skilled on image-text pairs. In artificial picture retrieval duties, E5-V confirmed Recall@10 scores of 75.88% on CIRR and 53.78% on FashionIQ, demonstrating important enhancements over present baselines. These outcomes spotlight E5-V’s skill to precisely symbolize multimodal data with out the necessity for extra fine-tuning or complicated coaching knowledge.
In conclusion, the E5-V framework represents a significant development in multimodal studying. By leveraging single-modality coaching and prompt-based illustration strategies, E5-V addresses the restrictions of conventional approaches and offers a extra environment friendly and efficient answer for multimodal embedding. This work demonstrates the potential of MLLM to revolutionize duties requiring built-in imaginative and prescient and language understanding, paving the way in which for future improvements in synthetic intelligence. The work of a analysis workforce from Beihang College and Microsoft Company highlights the transformative potential of the strategy and units a brand new benchmark for multimodal modeling.
Please examine paper, Model Cardand GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, do not forget to comply with us. twitter And our Telegram Channel and LinkedIn GroupsUp. When you like our work, you’ll love our Newsletter..
Please be a part of us 47,000+ ML subreddits
Try our upcoming AI webinars right here
Nikhil is an Intern Guide at Marktechpost. He’s pursuing a twin diploma in Built-in Supplies from Indian Institute of Know-how Kharagpur. Nikhil is an avid advocate of AI/ML and is continually exploring its functions in areas corresponding to biomaterials and biomedicine. Along with his intensive expertise in supplies science, Nikhil enjoys exploring new developments and creating alternatives to contribute.


{kind=link}