


Doc Understanding (DU) focuses on the automated interpretation and processing of paperwork that comprise complicated structure buildings and multimodal parts resembling textual content, tables, graphs, photographs, and many others. This process is crucial to extract and leverage the huge quantity of data contained within the paperwork generated yearly.
One important problem is knowing lengthy contextual paperwork that span many pages and require completely different codecs and cross-page understanding. Conventional single-page DU fashions battle with this downside, making it essential to develop benchmarks to judge mannequin efficiency on lengthy paperwork. Researchers have recognized that these lengthy contextual paperwork require particular options resembling localization and cross-page understanding, which aren’t properly addressed by present single-page DU datasets.
Present strategies at DU embrace large-scale visible language fashions (LVLMs) resembling GPT-4o, Gemini-1.5, and Claude-3 developed by corporations resembling OpenAI and Anthropic. Whereas these fashions present promise for single-page duties, they need assistance understanding lengthy, contextual paperwork as a result of they require multi-page understanding and the combination of multi-modal parts. This functionality hole highlights the significance of making complete benchmarks to drive the event of extra superior fashions.
Researchers from Nanyang Technological College, Shanghai Institute of Synthetic Intelligence, Peking College, and different institutes have introduced MMLongBench-Doc, a complete benchmark designed to judge LVLM’s long-context DU capabilities. The benchmark accommodates 135 PDF-formatted paperwork from numerous domains, with a mean of 47.5 pages and 21,214.1 textual content tokens. There are 1,091 questions that require proof from textual content, photographs, graphs, tables, and structure buildings, nearly all of which require cross-page understanding. This rigorous benchmark goals to push the bounds of present DU fashions.
Intimately, the methodology makes use of screenshots of doc pages as enter to LVLM and compares its efficiency with conventional OCR parsing textual content fashions. The development of the benchmark was meticulously carried out by 10 professional annotators who edited questions from current datasets and created new questions for comprehensiveness. The annotation course of ensured prime quality by three rounds of semi-automated evaluation processes. This method emphasised the necessity for fashions to comprehensively deal with lengthy paperwork, making MMLongBench-Doc an essential software for evaluating and bettering DU fashions.
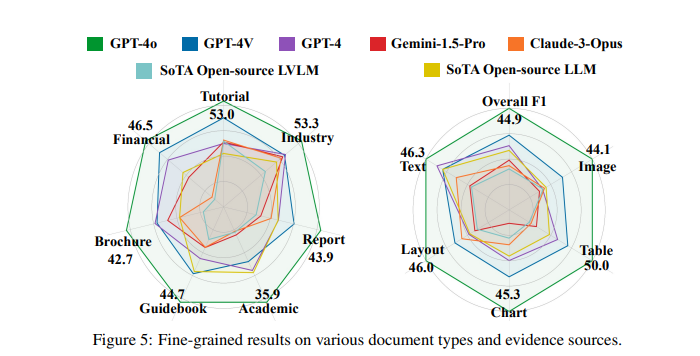
Efficiency analysis revealed that LVLMs typically battle with long-context DUs. For instance, the best-performing mannequin, GPT-4o, achieved an F1 rating of 44.9%, whereas the second-best mannequin, GPT-4V, achieved 30.5%. Different fashions, resembling Gemini-1.5 and Claude-3, carried out even worse. These outcomes point out that long-context DUs pose appreciable challenges and additional progress is required. The research in contrast these outcomes with OCR-based fashions and famous that some LVLMs carried out worse than single-modal LLMs when fed with lossy OCR parsed textual content.
Detailed outcomes spotlight that though LVLM can deal with multimodal enter to some extent, its capabilities nonetheless should be improved. For instance, 33.0% of the benchmark questions had been cross-page questions that required understanding of a number of pages, and 22.5% had been designed to be unanswerable to detect potential hallucinations. This rigorous take a look at highlighted the necessity for a extra performant LVLM. Our proprietary mannequin carried out higher than the open-source fashions as a result of greater variety of photographs and most picture decision allowed.

In conclusion, this work highlights the complexity of lengthy context doc understanding and the necessity for superior fashions that may successfully course of and perceive lengthy multimodal paperwork. The MMLongBench-Doc benchmark, developed in collaboration with main analysis establishments, is a priceless software to judge and enhance the efficiency of those fashions. The outcomes of this work spotlight important challenges with present fashions and the necessity for continued analysis and improvement on this space to attain more practical and complete DU options.
Please examine paperAll credit score for this analysis goes to the researchers of this challenge. Additionally, remember to observe us. twitter.
take part Telegram Channel and LinkedIn GroupsUp.
When you like our work, you’ll love our Newsletter..
Please be part of us 46k+ ML Subreddit
Nikhil is an Intern Marketing consultant at Marktechpost. He’s pursuing a twin diploma in Built-in Supplies from Indian Institute of Know-how Kharagpur. Nikhil is an avid advocate of AI/ML and is continually exploring its purposes in areas resembling biomaterials and biomedicine. Along with his in depth expertise in supplies science, Nikhil enjoys exploring new developments and creating alternatives to contribute.

{kind=link}