


We at the moment are Choice Shuffle Ensemble We create a number of variations of the identical take a look at drawback by shuffling the order of reply selections for every drawback. The LLM is then offered with these variations and the corresponding few-shot examples, and generates inference steps and solutions for every variation. Lastly, we take a majority vote on the predictions from all variations to pick the ultimate prediction.
The related code for this implementation will be discovered right here github repository link.
We use MedQA [6] Dataset for implementing and evaluating Medprompt. First, we outline a helper operate to parse jsonl recordsdata.
def write_jsonl_file(file_path, dict_list):
"""
Write a listing of dictionaries to a JSON Strains file.Args:
- file_path (str): The trail to the file the place the information will likely be written.
- dict_list (checklist): A listing of dictionaries to write down to the file.
"""
with open(file_path, 'w') as file:
for dictionary in dict_list:
json_line = json.dumps(dictionary)
file.write(json_line + 'n')
def read_jsonl_file(file_path):
"""
Parses a JSONL (JSON Strains) file and returns a listing of dictionaries.
Args:
file_path (str): The trail to the JSONL file to be learn.
Returns:
checklist of dict: A listing the place every aspect is a dictionary representing
a JSON object from the file.
"""
jsonl_lines = []
with open(file_path, 'r', encoding="utf-8") as file:
for line in file:
json_object = json.hundreds(line)
jsonl_lines.append(json_object)
return jsonl_lines
Implementing a self-generated CoT
For our implementation, we use the MedQA coaching set. We implement zero-shot CoT prompts to deal with all coaching questions. GPT-4o In our implementation, we generate a CoT and the corresponding reply for every query. We outline the prompts primarily based on the templates supplied within the Medprompt paper.
system_prompt = """You might be an professional medical skilled. You might be supplied with a medical query with a number of reply selections.
Your objective is to assume via the query rigorously and clarify your reasoning step-by-step earlier than deciding on the ultimate reply.
Reply solely with the reasoning steps and reply as specified under.
Beneath is the format for every query and reply:Enter:
## Query: {{query}}
{{answer_choices}}
Output:
## Reply
(mannequin generated chain of thought rationalization)
Due to this fact, the reply is [final model answer (e.g. A,B,C,D)]"""
def build_few_shot_prompt(system_prompt, query, examples, include_cot=True):
"""
Builds the zero-shot immediate.Args:
system_prompt (str): Job Instruction for the LLM
content material (dict): The content material for which to create a question, formatted as
required by `create_query`.
Returns:
checklist of dict: A listing of messages, together with a system message defining
the duty and a person message with the enter query.
"""
messages = [{"role": "system", "content": system_prompt}]
for elem in examples:
messages.append({"position": "person", "content material": create_query(elem)})
if include_cot:
messages.append({"position": "assistant", "content material": format_answer(elem["cot"], elem["answer_idx"])})
else:
answer_string = f"""## AnswernTherefore, the reply is {elem["answer_idx"]}"""
messages.append({"position": "assistant", "content material": answer_string})
messages.append({"position": "person", "content material": create_query(query)})
return messages
def get_response(messages, model_name, temperature = 0.0, max_tokens = 10):
"""
Obtains the responses/solutions of the mannequin via the chat-completions API.
Args:
messages (checklist of dict): The constructed messages supplied to the API.
model_name (str): Identify of the mannequin to entry via the API
temperature (float): A worth between 0 and 1 that controls the randomness of the output.
A temperature worth of 0 ideally makes the mannequin choose the more than likely token, making the outputs deterministic.
max_tokens (int): Most variety of tokens that the mannequin ought to generate
Returns:
str: The response message content material from the mannequin.
"""
response = consumer.chat.completions.create(
mannequin=model_name,
messages=messages,
temperature=temperature,
max_tokens=max_tokens
)
return response.selections[0].message.content material
We additionally outline helper capabilities for parsing inferences from LLM responses and ultimate reply choices.
def matches_ans_option(s):
"""
Checks if the string begins with the precise sample 'Due to this fact, the reply is [A-Z]'.Args:
s (str): The string to be checked.
Returns:
bool: True if the string matches the sample, False in any other case.
"""
return bool(re.match(r'^Due to this fact, the reply is [A-Z]', s))
def extract_ans_option(s):
"""
Extracts the reply possibility (a single capital letter) from the beginning of the string.
Args:
s (str): The string containing the reply sample.
Returns:
str or None: The captured reply possibility if the sample is discovered, in any other case None.
"""
match = re.search(r'^Due to this fact, the reply is ([A-Z])', s)
if match:
return match.group(1) # Returns the captured alphabet
return None
def matches_answer_start(s):
"""
Checks if the string begins with the markdown header '## Reply'.
Args:
s (str): The string to be checked.
Returns:
bool: True if the string begins with '## Reply', False in any other case.
"""
return s.startswith("## Reply")
def validate_response(s):
"""
Validates a multi-line string response that it begins with '## Reply' and ends with the reply sample.
Args:
s (str): The multi-line string response to be validated.
Returns:
bool: True if the response is legitimate, False in any other case.
"""
file_content = s.cut up("n")
return matches_ans_option(file_content[-1]) and matches_answer_start(s)
def parse_answer(response):
"""
Parses a response that begins with '## Reply', extracting the reasoning and the reply alternative.
Args:
response (str): The multi-line string response containing the reply and reasoning.
Returns:
tuple: A tuple containing the extracted CoT reasoning and the reply alternative.
"""
split_response = response.cut up("n")
assert split_response[0] == "## Reply"
cot_reasoning = "n".be part of(split_response[1:-1]).strip()
ans_choice = extract_ans_option(split_response[-1])
return cot_reasoning, ans_choice
Subsequent, we course of the questions within the coaching set of MedQA. We get the CoT responses and solutions for all of the questions and save them in a folder.
train_data = read_jsonl_file("knowledge/phrases_no_exclude_train.jsonl")cot_responses = []
# os.mkdir("cot_responses")
existing_files = os.listdir("cot_responses/")
for idx, merchandise in enumerate(tqdm(train_data)):
if str(idx) + ".txt" in existing_files:
proceed
immediate = build_zero_shot_prompt(system_prompt, merchandise)
strive:
response = get_response(immediate, model_name="gpt-4o", max_tokens=500)
cot_responses.append(response)
with open(os.path.be part of("cot_responses", str(idx) + ".txt"), "w", encoding="utf-8") as f:
f.write(response)
besides Exception as e :
print(str(e))
cot_responses.append("")
We then iterate via all of the generated responses to test if they’re legitimate and conform to the prediction format outlined within the immediate. We discard any responses that don’t conform to the required format. We then match the expected solutions for every query with the precise solutions and maintain solely these questions whose predicted solutions match the precise solutions.
questions_dict = []
ctr = 0
for idx, query in enumerate(tqdm(train_data)):
file = open(os.path.be part of("cot_responses/", str(idx) + ".txt"), encoding="utf-8").learn()
if not validate_response(file):
proceedcot, pred_ans = parse_answer(file)
dict_elem = {}
dict_elem["idx"] = idx
dict_elem["question"] = query["question"]
dict_elem["answer"] = query["answer"]
dict_elem["options"] = query["options"]
dict_elem["cot"] = cot
dict_elem["pred_ans"] = pred_ans
questions_dict.append(dict_elem)
filtered_questions_dict = []
for merchandise in tqdm(questions_dict):
pred_ans = merchandise["options"][item["pred_ans"]]
if pred_ans == merchandise["answer"]:
filtered_questions_dict.append(merchandise)
Implementing the KNN mannequin
After processing the coaching set and acquiring the CoT responses for all these questions, we Textual content Embedding – ada-002 From OpenAI.
def get_embedding(textual content, mannequin="text-embedding-ada-002"):
return consumer.embeddings.create(enter = [text], mannequin=mannequin).knowledge[0].embeddingfor merchandise in tqdm(filtered_questions_dict):
merchandise["embedding"] = get_embedding(merchandise["question"])
inv_options_map = {v:ok for ok,v in merchandise["options"].objects()}
merchandise["answer_idx"] = inv_options_map[item["answer"]]
Now, we use these query embeddings to coach a KNN mannequin, which acts as a retriever throughout inference and helps to retrieve comparable knowledge factors from the coaching set which might be most just like the questions within the take a look at set.
import numpy as np
from sklearn.neighbors import NearestNeighborsembeddings = np.array([d["embedding"] for d in filtered_questions_dict])
indices = checklist(vary(len(filtered_questions_dict)))
knn = NearestNeighbors(n_neighbors=5, algorithm='auto', metric='cosine').match(embeddings)
Implementing Dynamic Few-Shot and Choice Shuffle Ensemble Logic
Now we will run inference. For analysis, we subsample 500 questions from the MedQA take a look at set. For every query, we use the KNN module to acquire the 5 most comparable questions from the coaching set together with their respective CoT inference steps and predicted solutions. We use these examples to create a number of prompts.
For every query, we shuffle the order of the choices 5 occasions to create completely different variations, after which use a small set of constructed prompts to get predicted solutions for every variation with shuffled choices.
def shuffle_option_labels(answer_options):
"""
Shuffles the choices of the query.Parameters:
answer_options (dict): A dictionary with the choices.
Returns:
dict: A brand new dictionary with the shuffled choices.
"""
choices = checklist(answer_options.values())
random.shuffle(choices)
labels = [chr(i) for i in range(ord('A'), ord('A') + len(options))]
shuffled_options_dict = {label: possibility for label, possibility in zip(labels, choices)}
return shuffled_options_dict
test_samples = read_jsonl_file("final_processed_test_set_responses_medprompt.jsonl")for query in tqdm(test_samples, color ="inexperienced"):
question_variants = []
prompt_variants = []
cot_responses = []
question_embedding = get_embedding(query["question"])
distances, top_k_indices = knn.kneighbors([question_embedding], n_neighbors=5)
top_k_dicts = [filtered_questions_dict[i] for i in top_k_indices[0]]
query["outputs"] = []
for idx in vary(5):
question_copy = query.copy()
shuffled_options = shuffle_option_labels(query["options"])
inv_map = {v:ok for ok,v in shuffled_options.objects()}
question_copy["options"] = shuffled_options
question_copy["answer_idx"] = inv_map[question_copy["answer"]]
question_variants.append(question_copy)
immediate = build_few_shot_prompt(system_prompt, question_copy, top_k_dicts)
prompt_variants.append(immediate)
for immediate in tqdm(prompt_variants):
response = get_response(immediate, model_name="gpt-4o", max_tokens=500)
cot_responses.append(response)
for question_sample, reply in zip(question_variants, cot_responses):
if validate_response(reply):
cot, pred_ans = parse_answer(reply)
else:
cot = ""
pred_ans = ""
query["outputs"].append({"query": question_sample["question"], "choices": question_sample["options"], "cot": cot, "pred_ans": question_sample["options"].get(pred_ans, "")})
Subsequent, we consider the outcomes of Medprompt on the take a look at set. For every query, there are 5 predictions generated by the ensemble logic. We take the mode of every query, i.e. essentially the most continuously occurring prediction, as the ultimate prediction and consider the efficiency. Right here, there are two edge circumstances to think about:
- Two completely different reply choices are predicted twice every, with no clear winner.
- The generated response accommodates an error and has no predicted reply choices.
In each of those edge circumstances, the query will likely be thought-about answered incorrectly by the LLM.
def find_mode_string_list(string_list):
"""
Finds essentially the most continuously occurring strings.Parameters:
string_list (checklist of str): A listing of strings.
Returns:
checklist of str or None: A listing containing essentially the most frequent string(s) from the enter checklist.
Returns None if the enter checklist is empty.
"""
if not string_list:
return None
string_counts = Counter(string_list)
max_freq = max(string_counts.values())
mode_strings = [string for string, count in string_counts.items() if count == max_freq]
return mode_strings
ctr = 0
for merchandise in test_samples:
pred_ans = [x["pred_ans"] for x in merchandise["outputs"]]
freq_ans = find_mode_string_list(pred_ans)
if len(freq_ans) > 1:
final_prediction = ""
else:
final_prediction = freq_ans[0]
if final_prediction == merchandise["answer"]:
ctr +=1
print(ctr / len(test_samples))
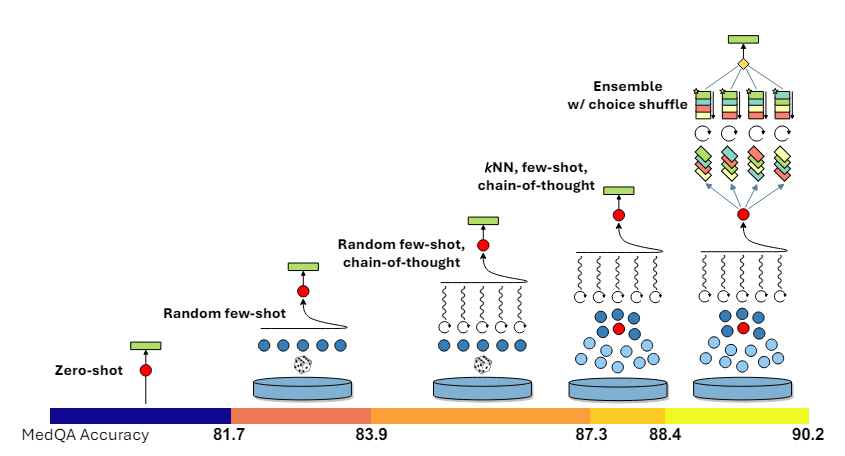
We consider the efficiency of Medprompt with GPT-4o when it comes to accuracy on the MedQA take a look at subset. Moreover, we benchmark the efficiency of zero-shot prompts, random few-shot prompts, and random few-shot with CoT prompts.

We are able to see that the Medprompt and Random Few-Shot CoT prompts outperform the baseline of Zero and Few-Shot prompts. Nevertheless, surprisingly, Random Few-Shot CoT outperforms Medprompt. There are a number of potential causes for this:
- The unique Medprompt paper benchmarked the efficiency of GPT-4, and we see that GPT-4o considerably outperforms GPT-4T and GPT-4 on a spread of textual content benchmarks (https://openai.com/index/hello-gpt-4o/), which means that Medprompt might have much less affect on highly effective fashions like GPT-4o.
- Our analysis is proscribed to a subsample of 500 questions from MedQA. The Medprompt paper evaluates different Medical MCQA datasets in addition to the complete model of MedQA. Evaluating GPT-4o on the complete dataset would offer a extra correct image of its total efficiency.
Medprompt is an fascinating framework for creating subtle immediate pipelines, particularly helpful for adapting generalist LLMs to particular domains with out the necessity for fine-tuning. It additionally highlights the issues to make when deciding between prompts and fine-tuning for various use circumstances. Exploring to what extent prompts will be leveraged to enhance LLM efficiency is vital, as prompts is usually a resource- and cost-effective different to fine-tuning.
[1] Nori, H., Lee, YT, Zhang, S., Carignan, D., Edgar, R., Fusi, N., … & Horvitz, E. (2023). Can generalist foundational fashions beat special-purpose tuning? A case research in medication. arXiv preprint arXiv:2311.16452. (https://arxiv.org/abs/2311.16452)
[2] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., … & Zhou, D. (2022). Facilitating thought chaining to elicit inferences in large-scale language fashions. Advances in neural data processing programs, 3524824–24837. (https://openreview.net/pdf?id=_VjQlMeSB_J)
[3] Gekhman, Z., Yona, G., Aharoni, R., Eyal, M., Feder, A., Reichart, R., & Herzig, J. (2024). Does tweaking your legislation diploma primarily based on new information promote hallucinations? arXiv preprint arXiv:2405.05904. (https://arxiv.org/abs/2405.05904)
[4] Singhal, Okay., Azizi, S., Tu, T., Mahdavi, SS, Wei, J., Chung, HW, … & Natarajan, V. (2023). Massive-scale language fashions encode scientific information. Nature, 620(7972), 172-180.https://www.nature.com/articles/s41586-023-06291-2)
[5] Singhal, Okay., Tu, T., Gottweis, J., Sayres, R., Wulczyn, E., Hou, L., … & Natarajan, V. (2023). In the direction of expert-level medical query answering with large-scale language fashions. arXiv preprint arXiv:2305.09617. (https://arxiv.org/abs/2305.09617)
[6] Jin, D., Pan, E., Oufattole, N., Weng, W.H., Fang, H., & Szolovits, P. (2021). “What illness does this affected person have?” A big-scale open-domain question-answering dataset from medical examinations. Utilized Science, 11(14), 6421. (Source: http://arxiv.org/abs/2009.13081) (The unique dataset is launched beneath the MIT license.)

{kind=link}