


Coaching large-scale language fashions (LLMs) reminiscent of GPT-3 and Llama faces important inefficiencies because of {hardware} failures and community congestion. These points lead to important wastage of GPU sources and longer coaching durations. Particularly, {hardware} failures trigger coaching to be interrupted, and community congestion forces the GPU to attend for parameter synchronization, additional delaying the coaching course of. Addressing these challenges is essential to advancing AI analysis, as they instantly have an effect on the effectivity and feasibility of coaching extremely advanced fashions.
Present strategies to deal with these challenges embrace fundamental fault tolerance and site visitors administration methods, together with the usage of redundant computation, erasure coding for storage reliability, and multi-pathing methods to deal with community anomalies. Nevertheless, these strategies have important limitations: they’re computationally advanced and require important handbook intervention to diagnose and isolate faults, making them inefficient for real-time functions. Moreover, these strategies usually fail to successfully handle community site visitors on shared bodily clusters, resulting in congestion and poor efficiency scalability.
Researchers from Alibaba Group have proposed a brand new strategy known as Calibrating Collective Communication over Converged Ethernet (C4), which is designed to deal with the inefficiencies of present strategies by specializing in bettering communication effectivity and fault tolerance for large-scale AI clusters. C4 consists of two subsystems: C4D (C4 Diagnostics) and C4P (C4 Efficiency). C4D improves coaching stability by detecting system errors in actual time, isolating defective nodes, and enabling fast restart from the final checkpoint. C4P optimizes communication efficiency by effectively managing community site visitors, decreasing congestion and bettering GPU utilization. This strategy contributes considerably to the sphere by offering a extra environment friendly and correct resolution in comparison with current strategies.
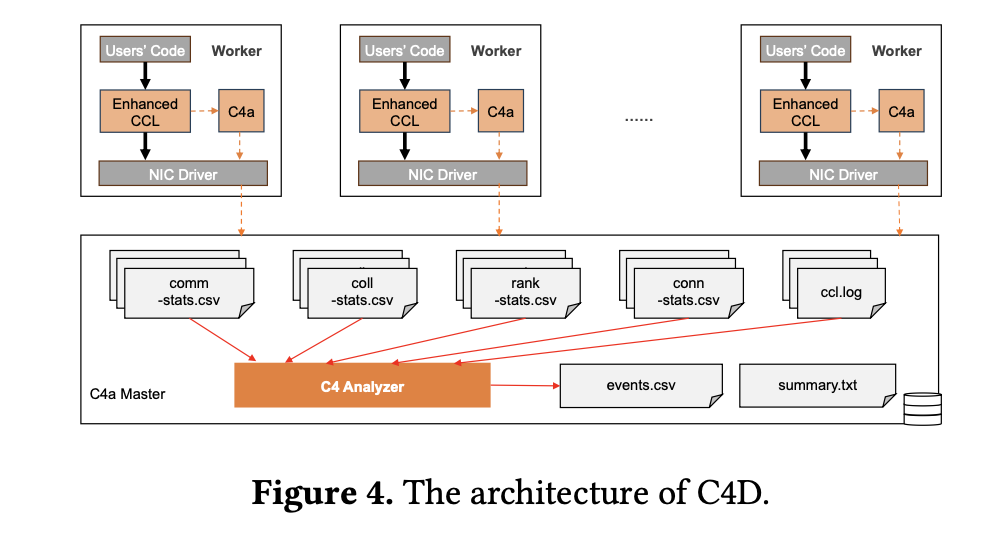
The C4 system implements the answer by leveraging the predictable communication patterns of collective operations in parallel coaching. C4D enhances the collective communication library to watch operations and detect potential errors based mostly on anomalies within the homogeneous traits of collective communication. As soon as a suspicious node is recognized, it’s remoted and its duties are resumed, minimizing downtime. C4P makes use of site visitors engineering methods to optimize community site visitors distribution, balancing the load throughout a number of paths and dynamically adapting to community modifications. Deploying the system throughout giant AI coaching clusters has demonstrated an roughly 30% discount in error overhead and an roughly 15% enchancment in runtime efficiency.
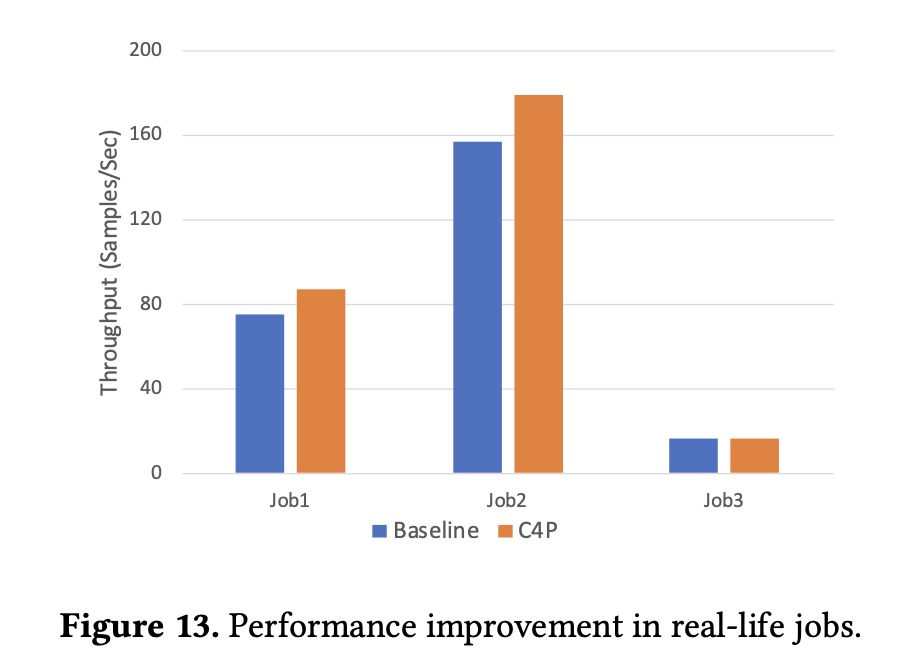
The researchers evaluated the effectiveness of C4 by specializing in key efficiency metrics reminiscent of throughput and error discount. For instance, the next determine from the paper highlights the efficiency beneficial properties for 3 consultant coaching jobs, exhibiting that C4P improves throughput by as much as 15.95% for duties with excessive communication overhead. The desk compares varied strategies, together with the proposed C4 strategy, with current baselines, highlighting important enhancements in effectivity and error dealing with.
In conclusion, the proposed strategies present a complete resolution to the inefficiencies of large-scale AI mannequin coaching. The C4 system, with subsystems C4D and C4P, addresses the important challenges of fault detection and community congestion, offering a extra environment friendly and correct approach to practice LLMs. By considerably decreasing error-induced overhead and bettering runtime efficiency, these strategies advance the sphere of AI analysis, making high-performance mannequin coaching extra sensible and cost-effective.
Please verify paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, do not forget to observe us. twitter. take part Telegram Channel, Discord Channeland LinkedIn GroupsUp.
In case you like our work, you’ll love our Newsletter..
Please be part of us 44k+ ML Subreddit
![]()
Aswin AK is a Consulting Intern at MarkTechPost. He’s pursuing a twin diploma from Indian Institute of Know-how Kharagpur. He’s captivated with Information Science and Machine Studying and has a robust tutorial background and sensible expertise in fixing real-world cross-domain issues.

{kind=link}