


Addressing compatibility points throughout set up | ONNX for NVIDIA GPUs | Hugging Face’s Optimum library
This text discusses the ONNX runtime, one of the vital efficient methods of rushing up Secure Diffusion inference. On an A100 GPU, operating SDXL for 30 denoising steps to generate a 1024 x 1024 picture will be as quick as 2 seconds. Nonetheless, the ONNX runtime relies on a number of transferring items, and putting in the precise variations of all of its dependencies will be tough in a always evolving ecosystem. Take this as a high-level debugging information, the place I share my struggles in hopes of saving you time. Whereas the precise variations and instructions would possibly rapidly grow to be out of date, the high-level ideas ought to stay related for an extended time frame.

ONNX can truly refer to 2 completely different (however associated) elements of the ML stack:
- ONNX is a format for storing machine studying fashions. It stands for Open Neural Community Trade and, as its identify suggests, its essential objective is interoperability throughout platforms. ONNX is a self-contained format: it shops each the mannequin weights and structure. Because of this a single .onnx file comprises all the knowledge wanted to run inference. No want to jot down any extra code to outline or load a mannequin; as an alternative, you merely go it to a runtime (extra on this beneath).
- ONNX can be a runtime to run mannequin which might be in ONNX format. It actually runs the mannequin. You possibly can see it as a mediator between the architecture-agnostic ONNX format and the precise {hardware} that runs inference. There’s a separate model of the runtime for every supported accelerator kind (see full list here). Be aware, nevertheless, that the ONNX runtime will not be the one option to run inference with a mannequin that’s in ONNX format — it’s only one method. Producers can select to construct their very own runtimes which might be hyper-optimized for his or her {hardware}. As an illustration, NVIDIA’s TensorRT is an alternative choice to the ONNX runtime.
This text focuses on operating Secure Diffusion fashions utilizing the ONNX runtime. Whereas the high-level ideas are in all probability timeless, observe that the ML tooling ecosystem is in fixed change, so the precise workflow or code snippets would possibly grow to be out of date (this text was written in Could 2024). I’ll deal with the Python implementation specifically, however observe that the ONNX runtime can even function in other languages like C++, C#, Java or JavaScript.
Execs of the ONNX Runtime
- Stability between inference pace and interoperability. Whereas the ONNX runtime is not going to all the time be the quickest answer for all sorts of {hardware}, it’s a quick sufficient answer for most forms of {hardware}. That is significantly interesting for those who’re serving your fashions on a heterogeneous fleet of machines and don’t have the sources to micro-optimize for every completely different accelerator.
- Large adoption and dependable authorship. ONNX was open-sourced by Microsoft, who’re nonetheless sustaining it. It’s broadly adopted and properly built-in into the broader ML ecosystem. As an illustration, Hugging Face’s Optimum library means that you can outline and run ONNX mannequin pipelines with a syntax that’s paying homage to their in style transformers and diffusers libraries.
Cons of the ONNX Runtime
- Engineering overhead. In comparison with the choice of operating inference straight in PyTorch, the ONNX runtime requires compiling your mannequin to the ONNX format (which may take 20–half-hour for a Secure Diffusion mannequin) and putting in the runtime itself.
- Restricted set of ops. The ONNX format doesn’t help all PyTorch operations (it’s much more restrictive than TorchScript). In case your mannequin is utilizing an unsupported operation, you’ll both need to reimplement the related portion, or drop ONNX altogether.
- Brittle set up and setup. Because the ONNX runtime makes the interpretation from the ONNX format to architecture-specific directions, it may be tough to get the precise mixture of software program variations to make it work. As an illustration, if operating on an NVIDIA GPU, it’s essential to guarantee compatibility of (1) working system, (2) CUDA model, (3) cuDNN model, and (4) ONNX runtime model. There are helpful sources just like the CUDA compatibility matrix, however you would possibly nonetheless find yourself losing hours discovering the magic mixture that works at a given cut-off date.
- {Hardware} limitations. Whereas the ONNX runtime can run on many architectures, it can’t run on all architectures like pure PyTorch fashions can. As an illustration, there may be at present (Could 2024) no help for Google Cloud TPUs or AWS Inferentia chips (see FAQ).
At first look, the record of cons appears longer than the record of professionals, however don’t be discouraged — as proven in a while, the enhancements in mannequin latency will be important and price it.
Choice #1: Set up from source
As talked about above, the ONNX runtime requires compatibility between many items of software program. If you wish to be on the leading edge, one of the simplest ways to get the newest model is to comply with the directions within the official Github repository. For Secure Diffusion specifically, this folder comprises set up directions and pattern scripts for producing photographs. Anticipate constructing from supply to take fairly some time (round half-hour).
On the time of writing (Could 2024), this answer labored seamlessly for me on an Amazon EC2 occasion (g5.2xlarge, which comes with a A10G GPU). It avoids compatibility points mentioned beneath through the use of a Docker picture that comes with the precise dependencies.
Choice #2: Set up through PyPI
In manufacturing, you’ll more than likely desire a secure model of the ONNX runtime from PyPI, as an alternative of putting in the newest model from supply. For Python specifically, there are two completely different libraries (one for CPU and one for GPU). Right here is the command to put in it for CPU:
pip set up onnxruntime
And right here is the command to put in it for GPU:
pip set up onnxruntime-gpu
You must by no means set up each. Having them each would possibly result in error messages or behaviors that aren’t straightforward to trace again to this root trigger. The ONNX runtime would possibly merely fail to acknowledge the presence of the GPU, which can look shocking provided that onnxruntime-gpu is certainly put in.
In a super world, pip set up onnxruntime-gpu can be the tip of the story. Nonetheless, in follow, there are sturdy compatibility necessities between different items of software program in your machine, together with the working system, the hardware-specific drivers, and the Python model.
Say that you simply wish to use the newest model of the ONNX runtime (1.17.1) on the time of writing. So what stars do we have to align to make this occur?
Listed below are a few of the commonest sources of incompatibility that may assist you arrange your setting. The precise particulars will rapidly grow to be out of date, however the high-level concepts ought to proceed to use for some time.
CUDA compatibility
If you’re not planning on utilizing an NVIDIA GPU, you may skip this part. CUDA is a platform for parallel computing that sits on prime of NVIDIA GPUs, and is required for machine studying workflows. Every model of the ONNX runtime is suitable with solely sure CUDA variations, as you may see in this compatibility matrix.
In accordance with this matrix, the newest ONNX runtime model (1.17) is suitable with each CUDA 11.8 and CUDA 12. However it’s essential to take note of the high quality print: by default, ONNX runtime 1.17 expects CUDA 11.8. Nonetheless, most VMs in the present day (Could 2024) include CUDA 12.1 (you may verify the model by operating nvcc --version). For this explicit setup, you’ll have to switch the standard pip set up onnxruntime-gpu with:
pip set up onnxruntime-gpu==1.17.1 --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-12/pypi/easy/
Be aware that, as an alternative of being on the mercy of no matter CUDA model occurs to be put in in your machine, a cleaner answer is to do your work from inside a Docker container. You merely select the picture that has your required model of Python and CUDA. As an illustration:
docker run --rm -it --gpus all nvcr.io/nvidia/pytorch:23.10-py3
OS + Python + pip compatibility
This part discusses compatibility points which might be architecture-agnostic (i.e. you’ll encounter them whatever the goal accelerator). It boils down to creating positive that your software program (working system, Python set up and pip set up) are suitable along with your desired model of the ONNX runtime library.
Pip model: Except you’re working with legacy code or methods, your most secure wager is to improve pip to the newest model:
python -m pip set up --upgrade pip
Python model: As of Could 2024, the Python model that’s least possible to offer you complications is 3.10 (that is what most VMs include by default). Once more, until you’re working with legacy code, you definitely need a minimum of 3.8 (since 3.7 was deprecated in June 2023).
Working system: The truth that the OS model can even hinder your potential to put in the specified library got here as a shock to me, particularly that I used to be utilizing essentially the most normal EC2 situations. And it wasn’t easy to determine that the OS model was the wrongdoer.
Right here I’ll stroll you thru my debugging course of, within the hopes that the workflow itself is longer-lived than the specifics of the variations in the present day. First, I put in onnxruntime-gpu with the next command (since I had CUDA 12.1 put in on my machine):
pip set up onnxruntime-gpu --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-12/pypi/easy/
On the floor, this could set up the newest model of the library obtainable on PyPI. In actuality nevertheless, this can set up the newest model suitable along with your present setup (OS + Python model + pip model). For me on the time, that occurred to be onnxruntime-gpu==1.16.0. (versus 1.17.1, which is the newest). Unknowingly putting in an older model merely manifested within the ONNX runtime being unable to detect the GPU, with no different clues. After considerably by chance discovering the model is older than anticipated, I explicitly requested for the newer one:
pip set up onnxruntime-gpu==1.17.1 --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-12/pypi/easy/
This resulted in a message from pip complaining that the model I requested will not be truly obtainable (regardless of being listed on PyPI):
ERROR: Couldn't discover a model that satisfies the requirement onnxruntime-gpu==1.17.1 (from variations: 1.12.0, 1.12.1, 1.13.1, 1.14.0, 1.14.1, 1.15.0, 1.15.1, 1.16.0, 1.16.1, 1.16.2, 1.16.3)
ERROR: No matching distribution discovered for onnxruntime-gpu==1.17.1
To know why the newest model will not be getting put in, you may go a flag that makes pip verbose: pip set up ... -vvv. This reveals all of the Python wheels that pip cycles via with the intention to discover the most recent one that’s suitable to your system. Here’s what the output seemed like for me:
Skipping hyperlink: not one of the wheel's tags (cp35-cp35m-manylinux1_x86_64) are suitable (run pip debug --verbose to indicate suitable tags): https://recordsdata.pythonhosted.org/packages/26/1a/163521e075d2e0c3effab02ba11caba362c06360913d7c989dcf9506edb9/onnxruntime_gpu-0.1.2-cp35-cp35m-manylinux1_x86_64.whl (from https://pypi.org/easy/onnxruntime-gpu/)
Skipping hyperlink: not one of the wheel's tags (cp36-cp36m-manylinux1_x86_64) are suitable (run pip debug --verbose to indicate suitable tags): https://recordsdata.pythonhosted.org/packages/52/f2/30aaa83bc9e90e8a919c8e44e1010796eb30f3f6b42a7141ffc89aba9a8e/onnxruntime_gpu-0.1.2-cp36-cp36m-manylinux1_x86_64.whl (from https://pypi.org/easy/onnxruntime-gpu/)
Skipping hyperlink: not one of the wheel's tags (cp37-cp37m-manylinux1_x86_64) are suitable (run pip debug --verbose to indicate suitable tags): https://recordsdata.pythonhosted.org/packages/a2/05/af0481897255798ee57a242d3989427015a11a84f2eae92934627be78cb5/onnxruntime_gpu-0.1.2-cp37-cp37m-manylinux1_x86_64.whl (from https://pypi.org/easy/onnxruntime-gpu/)
Skipping hyperlink: not one of the wheel's tags (cp35-cp35m-manylinux1_x86_64) are suitable (run pip debug --verbose to indicate suitable tags): https://recordsdata.pythonhosted.org/packages/17/cb/0def5a44db45c6d38d95387f20057905ce2dd4fad35c0d43ee4b1cebbb19/onnxruntime_gpu-0.1.3-cp35-cp35m-manylinux1_x86_64.whl (from https://pypi.org/easy/onnxruntime-gpu/)
Skipping hyperlink: not one of the wheel's tags (cp36-cp36m-manylinux1_x86_64) are suitable (run pip debug --verbose to indicate suitable tags): https://recordsdata.pythonhosted.org/packages/a6/53/0e733ebd72d7dbc84e49eeece15af13ab38feb41167fb6c3e90c92f09cbb/onnxruntime_gpu-0.1.3-cp36-cp36m-manylinux1_x86_64.whl (from https://pypi.org/simple/onnxruntime-gpu/)
...
The tags listed in brackets are Python platform compatibility tags, and you’ll learn extra about them here. In a nutshell, each Python wheel comes with a tag that signifies what system it will possibly run on. As an illustration, cp35-cp35m-manylinux1_x86_64 requires CPython 3.5, a set of (older) Linux distributions that fall underneath the manylinux1 umbrella, and a 64-bit x86-compatible processor.
Since I wished to run Python 3.10 on a Linux machine (therefore filtering for cp310.*manylinux.*, I used to be left with a single doable wheel for the onnxruntime-gpu library, with the next tag:
cp310-cp310-manylinux_2_28_x86_64
You may get a listing of tags which might be suitable along with your system by operating pip debug --verbose. Here’s what a part of my output seemed like:
cp310-cp310-manylinux_2_26_x86_64
cp310-cp310-manylinux_2_25_x86_64
cp310-cp310-manylinux_2_24_x86_64
cp310-cp310-manylinux_2_23_x86_64
cp310-cp310-manylinux_2_22_x86_64
cp310-cp310-manylinux_2_21_x86_64
cp310-cp310-manylinux_2_20_x86_64
cp310-cp310-manylinux_2_19_x86_64
cp310-cp310-manylinux_2_18_x86_64
cp310-cp310-manylinux_2_17_x86_64
...
In different phrases, my working system is only a tad too previous (the utmost linux tag that it helps is manylinux_2_26, whereas the onnxruntime-gpu library’s solely Python 3.10 wheel requires manylinux_2_28. Upgrading from Ubuntu 20.04 to Ubuntu 24.04 solved the issue.
As soon as the ONNX runtime is (lastly) put in, producing photographs with Secure Diffusion requires two following steps:
- Export the PyTorch mannequin to ONNX (this may take > half-hour!)
- Cross the ONNX mannequin and the inputs (textual content immediate and different parameters) to the ONNX runtime.
Choice #1: Utilizing official scripts from Microsoft
As talked about earlier than, utilizing the official sample scripts from the ONNX runtime repository labored out of the field for me. When you comply with their set up directions, you received’t even need to take care of the compatibility points talked about above. After set up, producing a picture is an easy as:
python3 demo_txt2img_xl.py "starry evening over Golden Gate Bridge by van gogh"
Beneath the hood, this script defines an SDXL mannequin utilizing Hugging Face’s diffusers library, exports it to ONNX format (which may take as much as half-hour!), then invokes the ONNX runtime.
Choice #2: Utilizing Hugging Face’s Optimum library
The Optimum library guarantees quite a lot of comfort, permitting you to run fashions on numerous accelerators whereas utilizing the acquainted pipeline APIs from the well-known transformers and diffusers libraries. For ONNX specifically, that is what inference code for SDXL appears like (extra in this tutorial):
from optimum.onnxruntime import ORTStableDiffusionXLPipelinemodel_id = "stabilityai/stable-diffusion-xl-base-1.0"
base = ORTStableDiffusionXLPipeline.from_pretrained(model_id)
immediate = "crusing ship in storm by Leonardo da Vinci"
picture = base(immediate).photographs[0]
# Do not forget to avoid wasting the ONNX mannequin
save_directory = "sd_xl_base"
base.save_pretrained(save_directory)
In follow, nevertheless, I struggled lots with the Optimum library. First, set up is non-trivial; naively following the set up instruction within the README file will run into the incompatibility points defined above. This isn’t Optimum’s fault per se, however it does add one more layer of abstraction on prime of an already brittle setup. The Optimum set up would possibly pull a model of onnxruntime that’s conflicting along with your setup.
Even after I received the battle towards compatibility points, I wasn’t in a position to run SDXL inference on GPU utilizing Optimum’s ONNX interface. The code snippet above (straight taken from a Hugging Face tutorial) fails with some form mismatches, maybe attributable to bugs within the PyTorch → ONNX conversion:
[ONNXRuntimeError] : 1 : FAIL : Non-zero standing code returned whereas operating Add node.
Title:'/down_blocks.1/attentions.0/Add'
Standing Message: /down_blocks.1/attentions.0/Add: left operand can't broadcast on dim 3 LeftShape: {2,64,4096,10}, RightShape: {2,640,64,64}
For a short second I thought of stepping into the weeds and debugging the Hugging Face code (a minimum of it’s open supply!), however gave up after I realized that Optimum has a backlog of more than 250 issues, with points going for weeks with no acknowledgement from the Hugging Face workforce. I made a decision to maneuver on and easily use Microsoft’s official scripts as an alternative.
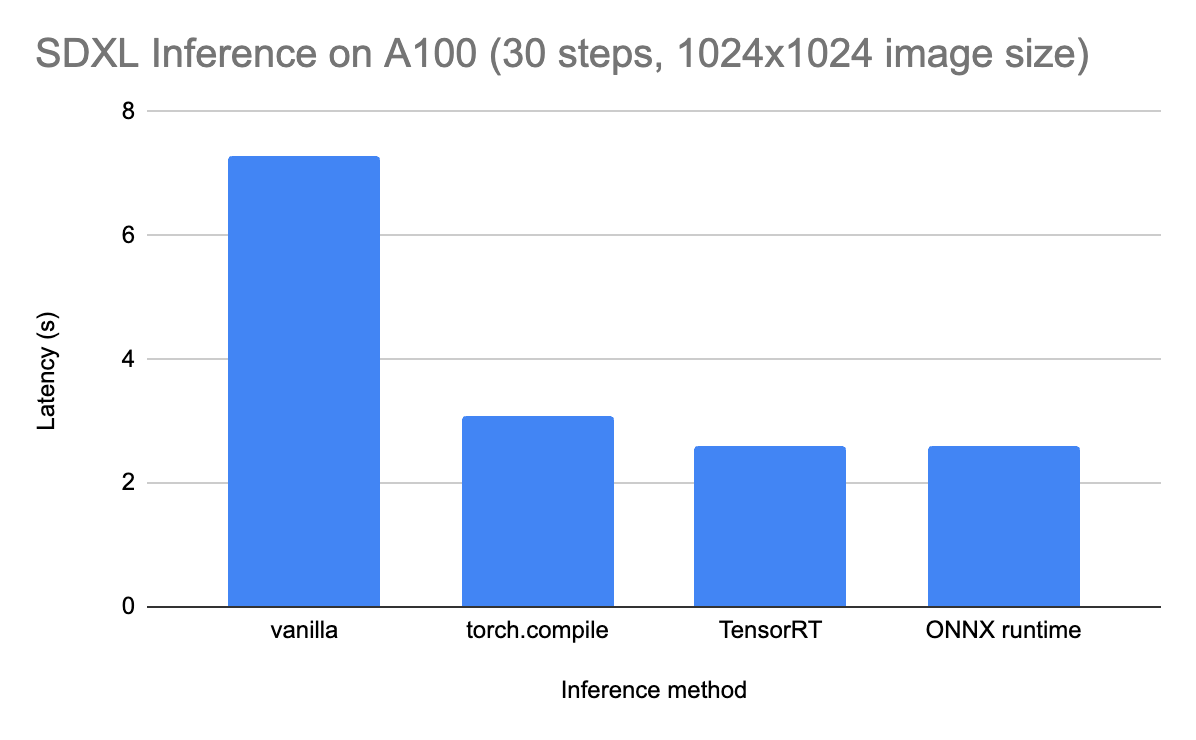
As promised, the trouble to get the ONNX runtime working is price it. On an A100 GPU, the inference time is lowered from 7–8 seconds (when operating vanilla PyTorch) to ~2 seconds. That is similar to TensorRT (an NVIDIA-specific various to ONNX), and about 1 second sooner than torch.compile (PyTorch’s native JIT compilation).
Reportedly, switching to much more performant GPUs (e.g. H100) can result in even increased features from operating your mannequin with a specialised runtime.
The ONNX runtime guarantees important latency features, however it comes with non-trivial engineering overhead. It additionally faces the basic trade-off for static compilation: inference is lots sooner, however the graph can’t be dynamically modified (which is at odds with dynamic adapters like peft). The ONNX runtime and related compilation strategies are price including to your pipeline when you’ve handed the experimentation section, and are able to put money into environment friendly manufacturing code.
When you’re focused on optimizing inference time, listed here are some articles that I discovered useful:

{kind=link}