


This put up describes and demonstrates the idea of “structured generative AI,” which is generative AI constrained to an outlined format. By the top of this text, you will perceive the place and when you need to use a transformer mannequin, and tips on how to implement it, whether or not you are constructing one from scratch or leveraging Hugging Face’s mannequin. Moreover, we’ll cowl vital tokenization suggestions particularly associated to structured languages.
One of many many makes use of of generative AI is as a translation instrument. This usually includes translation between two human languages, however also can embody pc languages and codecs. For instance, an software could must translate pure (human) language to SQL.
Pure language: “Get buyer names and emails of consumers from the US”SQL: "SELECT title, e mail FROM clients WHERE nation = 'USA'"
Alternatively, to transform textual content information to JSON format:
Pure language: “I'm John Doe, cellphone quantity is 555–123–4567,
my pals are Anna and Sara”JSON: {title: "John Doe",
phone_number: "555–123–5678",
pals: {
title: [["Anna", "Sara"]]}
}
After all, many extra purposes are attainable for different structured languages. The coaching course of for such duties includes feeding the encoder/decoder mannequin with pure language examples together with a structured format. Alternatively, you’ll be able to merely leverage a pre-trained language mannequin (LLM).
Though it’s unattainable to attain 100% accuracy, there’s one sort of error that may be eradicated. That is a syntax error. These are violations of language formatting, resembling changing commas with dots, utilizing desk names that do not exist within the SQL schema, or omitting bracket closures, which stop you from executing SQL or JSON.
The truth that we’re changing to a structured language implies that the checklist of authorized tokens at every era step is proscribed and predetermined. If this information may be integrated into the AI era course of, widespread inaccurate outcomes may be averted. That is the concept behind structured generative AI. In different phrases, restrict the AI to the checklist of professional tokens.
A fast notice on tips on how to generate tokens
Token era operates sequentially, no matter whether or not you utilize an encoder/decoder or GPT structure.The number of every token depends upon each the enter token and the beforehand generated tokens, indicating the completion of the sequence

Token era limitations
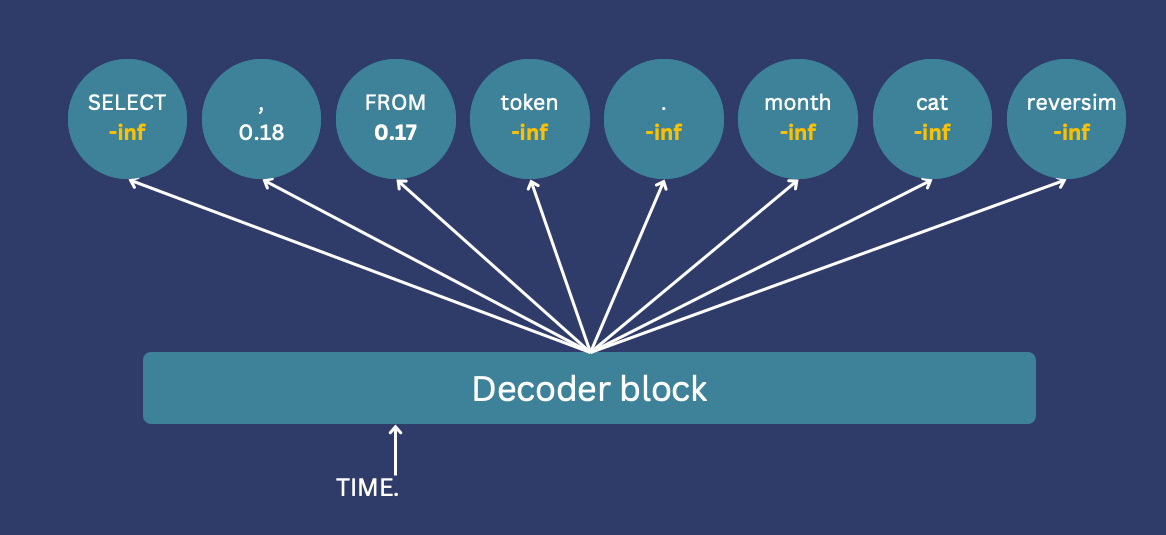
Incorporates information concerning the construction of the output language to constrain token era. The logit of invalid tokens is ready to -inf to make sure they’re excluded from choice. For instance, if solely a comma or “FROM” is legitimate after “Choose Identify”, all different token logs might be set to -inf.
If you’re utilizing Hugging Face, this may be carried out utilizing a “Lojitz Processor”. To make use of this, it’s essential to implement a category that features a __call__ methodology. This methodology is known as after logits are calculated and earlier than sampling. This methodology takes all token logs and generated enter IDs and returns a modified log of all tokens.

I’ll present the code with a easy instance. First, initialize the mannequin. On this case we’ll use Bart, however this may work with any mannequin.
from transformers import BartForConditionalGeneration, BartTokenizerFast, PreTrainedTokenizer
from transformers.era.logits_process import LogitsProcessorList, LogitsProcessor
import torchtitle = 'fb/bart-large'
tokenizer = BartTokenizerFast.from_pretrained(title, add_prefix_space=True)
pretrained_model = BartForConditionalGeneration.from_pretrained(title)
If you wish to generate a pure language to SQL translation, you are able to do the next:
to_translate = 'clients emails from the us'
phrases = to_translate.cut up()
tokenized_text = tokenizer([words], is_split_into_words=True)out = pretrained_model.generate(
torch.tensor(tokenized_text["input_ids"]),
max_new_tokens=20,
)
print(tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(
out[0], skip_special_tokens=True)))
return
'Extra emails from the us'
We’ve not fine-tuned the mannequin for text-to-SQL duties, so the output would not resemble SQL. This tutorial doesn’t practice a mannequin, however guides it to generate SQL queries. That is achieved by utilizing a perform that maps every generated token to an inventory of the following allowed tokens. For readability, we are going to focus solely on the instantly previous token, however extra advanced mechanisms may be simply carried out. Use a dictionary that defines every token and permits subsequent tokens. For instance, a question should begin with “SELECT” or “DELETE”, and solely “title”, “e mail”, or “id” are allowed after “SELECT”. As a result of these are columns within the schema.
guidelines = {'<s>': ['SELECT', 'DELETE'], # starting of the era
'SELECT': ['name', 'email', 'id'], # names of columns in our schema
'DELETE': ['name', 'email', 'id'],
'title': [',', 'FROM'],
'e mail': [',', 'FROM'],
'id': [',', 'FROM'],
',': ['name', 'email', 'id'],
'FROM': ['customers', 'vendors'], # names of tables in our schema
'clients': ['</s>'],
'distributors': ['</s>'], # finish of the era
}
Subsequent, it’s essential to convert these tokens to IDs utilized in your mannequin. This happens inside courses that inherit from LogitsProcessor.
def convert_token_to_id(token):
return tokenizer(token, add_special_tokens=False)['input_ids'][0]class SQLLogitsProcessor(LogitsProcessor):
def __init__(self, tokenizer: PreTrainedTokenizer):
self.tokenizer = tokenizer
self.guidelines = {convert_token_to_id(ok): [convert_token_to_id(v0) for v0 in v] for ok,v in guidelines.gadgets()}
Lastly, implement the __call__ perform that might be known as after calculating the logit. This perform creates a brand new tensor of -infs, checks which IDs are professional in accordance with the foundations (dictionary), and locations the scores into the brand new tensor. The consequence might be a tensor with solely legitimate values for legitimate tokens.
class SQLLogitsProcessor(LogitsProcessor):
def __init__(self, tokenizer: PreTrainedTokenizer):
self.tokenizer = tokenizer
self.guidelines = {convert_token_to_id(ok): [convert_token_to_id(v0) for v0 in v] for ok,v in guidelines.gadgets()}def __call__(self, input_ids: torch.LongTensor, scores: torch.LongTensor):
if not (input_ids == self.tokenizer.bos_token_id).any():
# we should enable the beginning token to seem earlier than we begin processing
return scores
# create a brand new tensor of -inf
new_scores = torch.full((1, self.tokenizer.vocab_size), float('-inf'))
# ids of professional tokens
legit_ids = self.guidelines[int(input_ids[0, -1])]
# place their values within the new tensor
new_scores[:, legit_ids] = scores[0, legit_ids]
return new_scores
that is all! Now you’ll be able to run generations utilizing logits-processor.
to_translate = 'clients emails from the us'
phrases = to_translate.cut up()
tokenized_text = tokenizer([words], is_split_into_words=True, return_offsets_mapping=True)logits_processor = LogitsProcessorList([SQLLogitsProcessor(tokenizer)])
out = pretrained_model.generate(
torch.tensor(tokenized_text["input_ids"]),
max_new_tokens=20,
logits_processor=logits_processor
)
print(tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(
out[0], skip_special_tokens=True)))
return
SELECT e mail , e mail , id , e mail FROM clients
The outcomes are somewhat unusual, however maintain this in thoughts: We haven’t even skilled the mannequin! We solely compelled the era of tokens primarily based on particular guidelines. Specifically, limiting era doesn’t stop coaching. Constraints are solely utilized throughout post-training era. Subsequently, correctly implementing these constraints will solely enhance the accuracy of the era.
Our simplified implementation falls in need of protecting all SQL syntax. Precise implementations ought to doubtlessly think about a number of tokens slightly than simply the final one to help extra syntax and allow batch era. With these enhancements in place, skilled fashions can reliably generate executable SQL queries constrained to legitimate desk and column names from the schema. The same method means that you can implement constraints when producing JSON, making certain key existence and parenthesis closure.
Watch out for tokenization
Tokenization is usually missed, however right tokenization is essential when utilizing generative AI for structured output. Nonetheless, underneath the hood, tokenization can have an effect on mannequin coaching. For instance, you’ll be able to tweak your mannequin to transform textual content to her JSON. As a part of the fine-tuning course of, we offer the mannequin with an instance of a text-to-her JSON pair and tokenize it. What’s going to this tokenization appear like?

Should you learn “[[“astwosquarebracketsthetokenizerwillconvertthemintooneIDThisistreatedbythetokenclassifierasacompletelydifferentclassthanasinglesquarebracketThismakesthewholelogicthatthemodelneedstolearnmorecomplex(egrememberingthenumberofclosingparentheses)Similarlyaddingaspacebeforeawordcanchangetheword’stokenizationandclassIDForexample:[[」を2つの角括弧として読み取ると、トークナイザーはそれらを1つのIDに変換します。これは、トークン分類子によって1つの角括弧とは完全に異なるクラスとして扱われます。これにより、モデルが学習する必要があるロジック全体がより複雑になります(たとえば、閉じる括弧の数を記憶するなど)。同様に、単語の前にスペースを追加すると、単語のトークン化とクラスIDが変更される可能性があります。例えば:[[“astwosquarebracketsthetokenizerconvertsthemintoasingleIDwhichwillbetreatedasacompletelydistinctclassfromthesinglebracketbythetokenclassifierThismakestheentirelogicthatthemodelmustlearn—morecomplicated(forexamplerememberinghowmanybracketstoclose)SimilarlyaddingaspacebeforewordsmaychangetheirtokenizationandtheirclassIDForinstance:

Once more, the weights related to every of those IDs should be realized individually for barely completely different circumstances, which complicates the logic that the mannequin must study.
To simplify studying, add areas earlier than phrases and letters so that every idea and punctuation mark persistently interprets into the identical token.

Inputting samples at intervals throughout fine-tuning simplifies the patterns that the mannequin must study and improves the mannequin’s accuracy. Throughout prediction, the mannequin outputs her JSON with areas. This may be eliminated earlier than parsing.
abstract
Generative AI offers a invaluable method for translating into formatted languages. By leveraging information of the output construction, you’ll be able to restrict the era course of to get rid of sure kinds of errors and guarantee queryability and parsability of the information construction.
Moreover, these codecs could use punctuation marks or key phrases to point particular meanings. Constant tokenization of those key phrases can considerably scale back the complexity of the patterns that the mannequin must study, thereby growing accuracy whereas lowering the required mannequin dimension and coaching time. You possibly can improve it.
Structured generative AI can successfully rework pure language into any structured format. These transformations allow info extraction and question era from textual content, making them highly effective instruments for a lot of purposes.

{kind=link}