


As we speak, we’re excited to announce the potential to fine-tune Code Llama fashions by Meta utilizing Amazon SageMaker JumpStart. The Code Llama household of enormous language fashions (LLMs) is a set of pre-trained and fine-tuned code technology fashions ranging in scale from 7 billion to 70 billion parameters. Fantastic-tuned Code Llama fashions present higher accuracy and explainability over the bottom Code Llama fashions, as evident on its testing in opposition to HumanEval and MBPP datasets. You may fine-tune and deploy Code Llama fashions with SageMaker JumpStart utilizing the Amazon SageMaker Studio UI with a number of clicks or utilizing the SageMaker Python SDK. Fantastic-tuning of Llama fashions relies on the scripts offered within the llama-recipes GitHub repo from Meta utilizing PyTorch FSDP, PEFT/LoRA, and Int8 quantization methods.
On this publish, we stroll by means of the right way to fine-tune Code Llama pre-trained fashions by way of SageMaker JumpStart by means of a one-click UI and SDK expertise obtainable within the following GitHub repository.
What’s SageMaker JumpStart
With SageMaker JumpStart, machine studying (ML) practitioners can select from a broad collection of publicly obtainable basis fashions. ML practitioners can deploy basis fashions to devoted Amazon SageMaker cases from a community remoted setting and customise fashions utilizing SageMaker for mannequin coaching and deployment.
What’s Code Llama
Code Llama is a code-specialized model of Llama 2 that was created by additional coaching Llama 2 on its code-specific datasets and sampling extra knowledge from that very same dataset for longer. Code Llama options enhanced coding capabilities. It might probably generate code and pure language about code, from each code and pure language prompts (for instance, “Write me a operate that outputs the Fibonacci sequence”). You can even use it for code completion and debugging. It helps most of the hottest programming languages used immediately, together with Python, C++, Java, PHP, Typescript (JavaScript), C#, Bash, and extra.
Why fine-tune Code Llama fashions
Meta printed Code Llama efficiency benchmarks on HumanEval and MBPP for widespread coding languages akin to Python, Java, and JavaScript. The efficiency of Code Llama Python fashions on HumanEval demonstrated various efficiency throughout totally different coding languages and duties starting from 38% on 7B Python mannequin to 57% on 70B Python fashions. As well as, fine-tuned Code Llama fashions on SQL programming language have proven higher outcomes, as evident in SQL analysis benchmarks. These printed benchmarks spotlight the potential advantages of fine-tuning Code Llama fashions, enabling higher efficiency, customization, and adaptation to particular coding domains and duties.
No-code fine-tuning by way of the SageMaker Studio UI
To start out fine-tuning your Llama fashions utilizing SageMaker Studio, full the next steps:
- On the SageMaker Studio console, select JumpStart within the navigation pane.
You can see listings of over 350 fashions starting from open supply and proprietary fashions.
- Seek for Code Llama fashions.
When you don’t see Code Llama fashions, you’ll be able to replace your SageMaker Studio model by shutting down and restarting. For extra details about model updates, check with Shut down and Replace Studio Apps. You can even discover different mannequin variants by selecting Discover all Code Era Fashions or trying to find Code Llama within the search field.
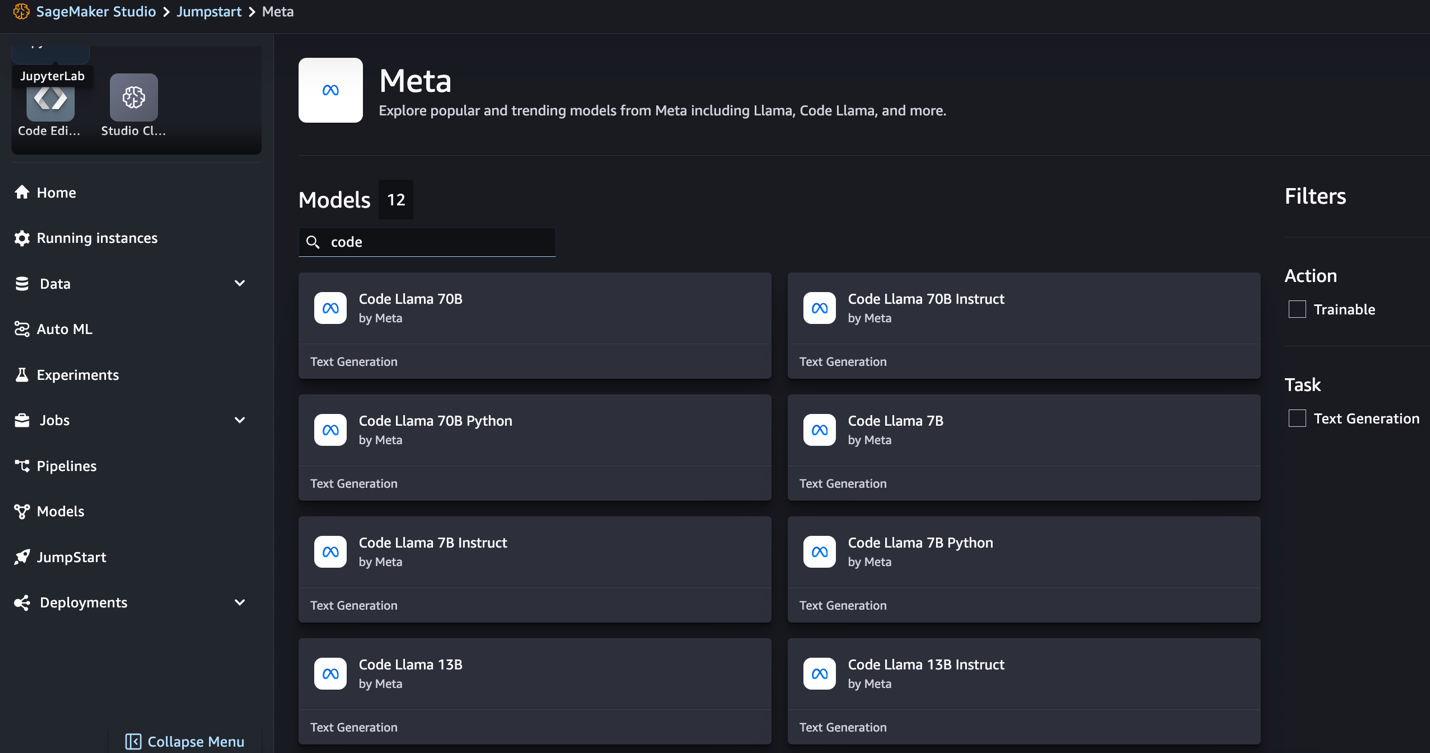
SageMaker JumpStart presently helps instruction fine-tuning for Code Llama fashions. The next screenshot exhibits the fine-tuning web page for the Code Llama 2 70B mannequin.
- For Coaching dataset location, you’ll be able to level to the Amazon Easy Storage Service (Amazon S3) bucket containing the coaching and validation datasets for fine-tuning.
- Set your deployment configuration, hyperparameters, and safety settings for fine-tuning.
- Select Practice to start out the fine-tuning job on a SageMaker ML occasion.
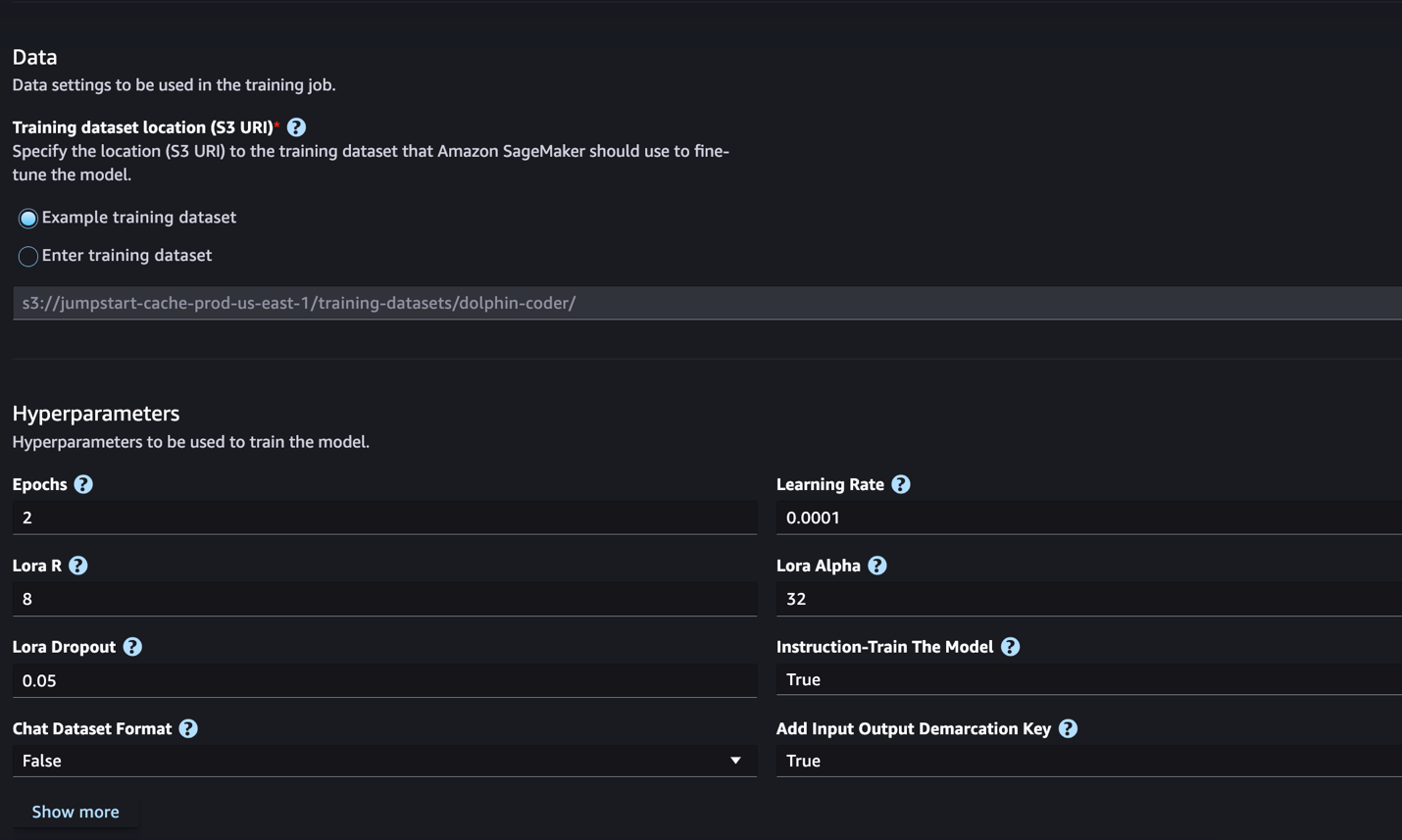
We focus on the dataset format you want put together for instruction fine-tuning within the subsequent part.
- After the mannequin is fine-tuned, you’ll be able to deploy it utilizing the mannequin web page on SageMaker JumpStart.
The choice to deploy the fine-tuned mannequin will seem when fine-tuning is completed, as proven within the following screenshot.
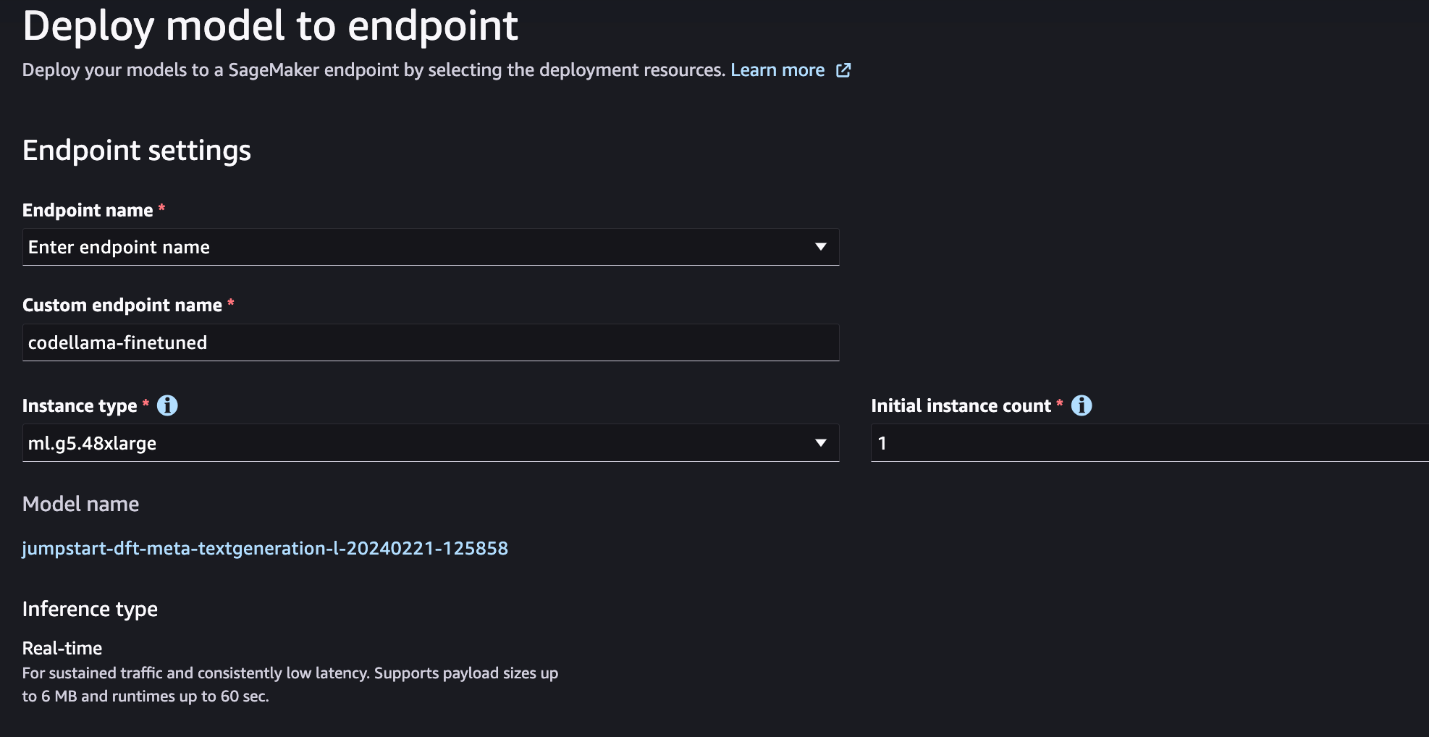
Fantastic-tune by way of the SageMaker Python SDK
On this part, we display the right way to fine-tune Code LIama fashions utilizing the SageMaker Python SDK on an instruction-formatted dataset. Particularly, the mannequin is fine-tuned for a set of pure language processing (NLP) duties described utilizing directions. This helps enhance the mannequin’s efficiency for unseen duties with zero-shot prompts.
Full the next steps to finish your fine-tuning job. You may get all the fine-tuning code from the GitHub repository.
First, let’s take a look at the dataset format required for the instruction fine-tuning. The coaching knowledge must be formatted in a JSON traces (.jsonl) format, the place every line is a dictionary representing an information pattern. All coaching knowledge should be in a single folder. Nonetheless, it may be saved in a number of .jsonl recordsdata. The next is a pattern in JSON traces format:
The coaching folder can comprise a template.json file describing the enter and output codecs. The next is an instance template:
To match the template, every pattern within the JSON traces recordsdata should embrace system_prompt, query, and response fields. On this demonstration, we use the Dolphin Coder dataset from Hugging Face.
After you put together the dataset and add it to the S3 bucket, you can begin fine-tuning utilizing the next code:
You may deploy the fine-tuned mannequin straight from the estimator, as proven within the following code. For particulars, see the pocket book within the GitHub repository.
Fantastic-tuning methods
Language fashions akin to Llama are greater than 10 GB and even 100 GB in dimension. Fantastic-tuning such giant fashions requires cases with considerably excessive CUDA reminiscence. Moreover, coaching these fashions will be very sluggish as a result of dimension of the mannequin. Due to this fact, for environment friendly fine-tuning, we use the next optimizations:
- Low-Rank Adaptation (LoRA) – This can be a kind of parameter environment friendly fine-tuning (PEFT) for environment friendly fine-tuning of enormous fashions. With this methodology, you freeze the entire mannequin and solely add a small set of adjustable parameters or layers into the mannequin. As an example, as an alternative of coaching all 7 billion parameters for Llama 2 7B, you’ll be able to fine-tune lower than 1% of the parameters. This helps in important discount of the reminiscence requirement since you solely have to retailer gradients, optimizer states, and different training-related data for only one% of the parameters. Moreover, this helps in discount of coaching time in addition to the price. For extra particulars on this methodology, check with LoRA: Low-Rank Adaptation of Large Language Models.
- Int8 quantization – Even with optimizations akin to LoRA, fashions akin to Llama 70B are nonetheless too large to coach. To lower the reminiscence footprint throughout coaching, you should utilize Int8 quantization throughout coaching. Quantization sometimes reduces the precision of floating level knowledge sorts. Though this decreases the reminiscence required to retailer mannequin weights, it degrades the efficiency as a consequence of lack of data. Int8 quantization makes use of solely 1 / 4 precision however doesn’t incur degradation of efficiency as a result of it doesn’t merely drop the bits. It rounds the information from one kind to the one other. To study Int8 quantization, check with LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale.
- Absolutely Sharded Knowledge Parallel (FSDP) – This can be a kind of data-parallel coaching algorithm that shards the mannequin’s parameters throughout knowledge parallel employees and may optionally offload a part of the coaching computation to the CPUs. Though the parameters are sharded throughout totally different GPUs, computation of every microbatch is native to the GPU employee. It shards parameters extra uniformly and achieves optimized efficiency by way of communication and computation overlapping throughout coaching.
The next desk summarizes the small print of every mannequin with totally different settings.
| Mannequin | Default Setting | LORA + FSDP | LORA + No FSDP | Int8 Quantization + LORA + No FSDP |
| Code Llama 2 7B | LORA + FSDP | Sure | Sure | Sure |
| Code Llama 2 13B | LORA + FSDP | Sure | Sure | Sure |
| Code Llama 2 34B | INT8 + LORA + NO FSDP | No | No | Sure |
| Code Llama 2 70B | INT8 + LORA + NO FSDP | No | No | Sure |
Fantastic-tuning of Llama fashions relies on scripts offered by the next GitHub repo.
Supported hyperparameters for coaching
Code Llama 2 fine-tuning helps plenty of hyperparameters, every of which might affect the reminiscence requirement, coaching velocity, and efficiency of the fine-tuned mannequin:
- epoch – The variety of passes that the fine-tuning algorithm takes by means of the coaching dataset. Have to be an integer better than 1. Default is 5.
- learning_rate – The speed at which the mannequin weights are up to date after working by means of every batch of coaching examples. Have to be a optimistic float better than 0. Default is 1e-4.
- instruction_tuned – Whether or not to instruction-train the mannequin or not. Have to be
TrueorFalse. Default isFalse. - per_device_train_batch_size – The batch dimension per GPU core/CPU for coaching. Have to be a optimistic integer. Default is 4.
- per_device_eval_batch_size – The batch dimension per GPU core/CPU for analysis. Have to be a optimistic integer. Default is 1.
- max_train_samples – For debugging functions or faster coaching, truncate the variety of coaching examples to this worth. Worth -1 means utilizing the entire coaching samples. Have to be a optimistic integer or -1. Default is -1.
- max_val_samples – For debugging functions or faster coaching, truncate the variety of validation examples to this worth. Worth -1 means utilizing the entire validation samples. Have to be a optimistic integer or -1. Default is -1.
- max_input_length – Most whole enter sequence size after tokenization. Sequences longer than this can be truncated. If -1,
max_input_lengthis about to the minimal of 1024 and the utmost mannequin size outlined by the tokenizer. If set to a optimistic worth,max_input_lengthis about to the minimal of the offered worth and themodel_max_lengthoutlined by the tokenizer. Have to be a optimistic integer or -1. Default is -1. - validation_split_ratio – If validation channel is
none, the ratio of the train-validation break up from the prepare knowledge should be between 0–1. Default is 0.2. - train_data_split_seed – If validation knowledge just isn’t current, this fixes the random splitting of the enter coaching knowledge to coaching and validation knowledge utilized by the algorithm. Have to be an integer. Default is 0.
- preprocessing_num_workers – The variety of processes to make use of for preprocessing. If
None, the principle course of is used for preprocessing. Default isNone. - lora_r – Lora R. Have to be a optimistic integer. Default is 8.
- lora_alpha – Lora Alpha. Have to be a optimistic integer. Default is 32
- lora_dropout – Lora Dropout. should be a optimistic float between 0 and 1. Default is 0.05.
- int8_quantization – If
True, the mannequin is loaded with 8-bit precision for coaching. Default for 7B and 13B isFalse. Default for 70B isTrue. - enable_fsdp – If True, coaching makes use of FSDP. Default for 7B and 13B is True. Default for 70B is False. Word that
int8_quantizationjust isn’t supported with FSDP.
When selecting the hyperparameters, think about the next:
- Setting
int8_quantization=Truedecreases the reminiscence requirement and results in sooner coaching. - Lowering
per_device_train_batch_sizeandmax_input_lengthreduces the reminiscence requirement and subsequently will be run on smaller cases. Nonetheless, setting very low values could improve the coaching time. - When you’re not utilizing Int8 quantization (
int8_quantization=False), use FSDP (enable_fsdp=True) for sooner and environment friendly coaching.
Supported occasion sorts for coaching
The next desk summarizes the supported occasion sorts for coaching totally different fashions.
| Mannequin | Default Occasion Sort | Supported Occasion Sorts |
| Code Llama 2 7B | ml.g5.12xlarge |
ml.g5.12xlarge, ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| Code Llama 2 13B | ml.g5.12xlarge |
ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| Code Llama 2 70B | ml.g5.48xlarge |
ml.g5.48xlarge ml.p4d.24xlarge |
When selecting the occasion kind, think about the next:
- G5 cases present essentially the most environment friendly coaching among the many occasion sorts supported. Due to this fact, when you have G5 cases obtainable, it is best to use them.
- Coaching time largely relies on the quantity of the variety of GPUs and the CUDA reminiscence obtainable. Due to this fact, coaching on cases with the identical variety of GPUs (for instance, ml.g5.2xlarge and ml.g5.4xlarge) is roughly the identical. Due to this fact, you should utilize the cheaper occasion for coaching (ml.g5.2xlarge).
- When utilizing p3 cases, coaching can be executed with 32-bit precision as a result of bfloat16 just isn’t supported on these cases. Due to this fact, the coaching job will eat double the quantity of CUDA reminiscence when coaching on p3 cases in comparison with g5 cases.
To study the price of coaching per occasion, check with Amazon EC2 G5 Cases.
Analysis
Analysis is a crucial step to evaluate the efficiency of fine-tuned fashions. We current each qualitative and quantitative evaluations to indicate enchancment of fine-tuned fashions over non-fine-tuned ones. In qualitative analysis, we present an instance response from each fine-tuned and non-fine-tuned fashions. In quantitative analysis, we use HumanEval, a check suite developed by OpenAI to generate Python code to check the skills of manufacturing appropriate and correct outcomes. The HumanEval repository is beneath MIT license. We fine-tuned Python variants of all Code LIama fashions over totally different sizes (Code LIama Python 7B, 13B, 34B, and 70B on the Dolphin Coder dataset), and current the analysis ends in the next sections.
Qualitatively analysis
Along with your fine-tuned mannequin deployed, you can begin utilizing the endpoint to generate code. Within the following instance, we current responses from each base and fine-tuned Code LIama 34B Python variants on a check pattern within the Dolphin Coder dataset:
The fine-tuned Code Llama mannequin, along with offering the code for the previous question, generates an in depth rationalization of the strategy and a pseudo code.
Code Llama 34b Python Non-Fantastic-Tuned Response:
Code Llama 34B Python Fantastic-Tuned Response
Floor Fact
Apparently, our fine-tuned model of Code Llama 34B Python gives a dynamic programming-based resolution to the longest palindromic substring, which is totally different from the answer offered within the floor reality from the chosen check instance. Our fine-tuned mannequin causes and explains the dynamic programming-based resolution intimately. Alternatively, the non-fine-tuned mannequin hallucinates potential outputs proper after the print assertion (proven within the left cell) as a result of the output axyzzyx just isn’t the longest palindrome within the given string. When it comes to time complexity, the dynamic programming resolution is mostly higher than the preliminary strategy. The dynamic programming resolution has a time complexity of O(n^2), the place n is the size of the enter string. That is extra environment friendly than the preliminary resolution from the non-fine-tuned mannequin, which additionally had a quadratic time complexity of O(n^2) however with a much less optimized strategy.
This seems promising! Bear in mind, we solely fine-tuned the Code LIama Python variant with 10% of the Dolphin Coder dataset. There may be much more to discover!
Regardless of of thorough directions within the response, we nonetheless want study the correctness of the Python code offered within the resolution. Subsequent, we use an analysis framework referred to as Human Eval to run integration exams on the generated response from Code LIama to systematically study its high quality.
Quantitative analysis with HumanEval
HumanEval is an analysis harness for evaluating an LLM’s problem-solving capabilities on Python-based coding issues, as described within the paper Evaluating Large Language Models Trained on Code. Particularly, it consists of 164 authentic Python-based programming issues that assess a language mannequin’s capacity to generate code primarily based on offered data like operate signature, docstring, physique, and unit exams.
For every Python-based programming query, we ship it to a Code LIama mannequin deployed on a SageMaker endpoint to get okay responses. Subsequent, we run every of the okay responses on the combination exams within the HumanEval repository. If any response of the okay responses passes the combination exams, we rely that check case succeed; in any other case, failed. Then we repeat the method to calculate the ratio of profitable circumstances as the ultimate analysis rating named cross@okay. Following customary apply, we set okay as 1 in our analysis, to solely generate one response per query and check whether or not it passes the combination check.
The next is a pattern code to make use of HumanEval repository. You may entry the dataset and generate a single response utilizing a SageMaker endpoint. For particulars, see the pocket book within the GitHub repository.
The next desk exhibits the enhancements of the fine-tuned Code LIama Python fashions over the non-fine-tuned fashions throughout totally different mannequin sizes. To make sure correctness, we additionally deploy the non-fine-tuned Code LIama fashions in SageMaker endpoints and run by means of Human Eval evaluations. The cross@1 numbers (the primary row within the following desk) match the reported numbers within the Code Llama research paper. The inference parameters are persistently set as "parameters": {"max_new_tokens": 384, "temperature": 0.2}.
As we are able to see from the outcomes, all of the fine-tuned Code LIama Python variants present important enchancment over the non-fine-tuned fashions. Specifically, Code LIama Python 70B outperforms the non-fine-tuned mannequin by roughly 12%.
| . | 7B Python | 13B Python | 34B | 34B Python | 70B Python |
| Pre-trained mannequin efficiency (cross@1) | 38.4 | 43.3 | 48.8 | 53.7 | 57.3 |
| Fantastic-tuned mannequin efficiency (cross@1) | 45.12 | 45.12 | 59.1 | 61.5 | 69.5 |
Now you’ll be able to attempt fine-tuning Code LIama fashions by yourself dataset.
Clear up
When you resolve that you just not need to hold the SageMaker endpoint operating, you’ll be able to delete it utilizing AWS SDK for Python (Boto3), AWS Command Line Interface (AWS CLI), or SageMaker console. For extra data, see Delete Endpoints and Assets. Moreover, you’ll be able to shut down the SageMaker Studio sources which are not required.
Conclusion
On this publish, we mentioned fine-tuning Meta’s Code Llama 2 fashions utilizing SageMaker JumpStart. We confirmed that you should utilize the SageMaker JumpStart console in SageMaker Studio or the SageMaker Python SDK to fine-tune and deploy these fashions. We additionally mentioned the fine-tuning method, occasion sorts, and supported hyperparameters. As well as, we outlined suggestions for optimized coaching primarily based on numerous exams we carried out. As we are able to see from these outcomes of fine-tuning three fashions over two datasets, fine-tuning improves summarization in comparison with non-fine-tuned fashions. As a subsequent step, you’ll be able to attempt fine-tuning these fashions by yourself dataset utilizing the code offered within the GitHub repository to check and benchmark the outcomes in your use circumstances.
Concerning the Authors
 Dr. Xin Huang is a Senior Utilized Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on growing scalable machine studying algorithms. His analysis pursuits are within the space of pure language processing, explainable deep studying on tabular knowledge, and strong evaluation of non-parametric space-time clustering. He has printed many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Sequence A.
Dr. Xin Huang is a Senior Utilized Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on growing scalable machine studying algorithms. His analysis pursuits are within the space of pure language processing, explainable deep studying on tabular knowledge, and strong evaluation of non-parametric space-time clustering. He has printed many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Sequence A.
 Vishaal Yalamanchali is a Startup Options Architect working with early-stage generative AI, robotics, and autonomous car corporations. Vishaal works along with his prospects to ship cutting-edge ML options and is personally fascinated by reinforcement studying, LLM analysis, and code technology. Previous to AWS, Vishaal was an undergraduate at UCI, targeted on bioinformatics and clever programs.
Vishaal Yalamanchali is a Startup Options Architect working with early-stage generative AI, robotics, and autonomous car corporations. Vishaal works along with his prospects to ship cutting-edge ML options and is personally fascinated by reinforcement studying, LLM analysis, and code technology. Previous to AWS, Vishaal was an undergraduate at UCI, targeted on bioinformatics and clever programs.
 Meenakshisundaram Thandavarayan works for AWS as an AI/ ML Specialist. He has a ardour to design, create, and promote human-centered knowledge and analytics experiences. Meena focuses on growing sustainable programs that ship measurable, aggressive benefits for strategic prospects of AWS. Meena is a connector and design thinker, and strives to drive companies to new methods of working by means of innovation, incubation, and democratization.
Meenakshisundaram Thandavarayan works for AWS as an AI/ ML Specialist. He has a ardour to design, create, and promote human-centered knowledge and analytics experiences. Meena focuses on growing sustainable programs that ship measurable, aggressive benefits for strategic prospects of AWS. Meena is a connector and design thinker, and strives to drive companies to new methods of working by means of innovation, incubation, and democratization.
 Dr. Ashish Khetan is a Senior Utilized Scientist with Amazon SageMaker built-in algorithms and helps develop machine studying algorithms. He received his PhD from College of Illinois Urbana-Champaign. He’s an energetic researcher in machine studying and statistical inference, and has printed many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Utilized Scientist with Amazon SageMaker built-in algorithms and helps develop machine studying algorithms. He received his PhD from College of Illinois Urbana-Champaign. He’s an energetic researcher in machine studying and statistical inference, and has printed many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.

{kind=link}