


Discover totally different metrics for artificial time collection analysis with hands-on code examples
This weblog put up is jupyter notebook on GitHub is a part of TSGM, a library for time series generative modeling.
In the present day we’ll be speaking about evaluating artificial time collection datasets (datasets which are artificially created to signify real-world information). Suppose we now have an artificial dataset D* that’s meant to signify an actual dataset D. It is very important quantitatively consider how good these artificial information are. Is D* an excellent illustration of D? Are these information secure? Are these information precious for downstream issues? On this tutorial, you’ll quantitatively and qualitatively assess the standard of artificial time collection information. Describes the strategy used to take action.
First, contemplate the next two instances. [1] Describe attainable makes use of for artificial information.
Situation 1. A company needs to rent an exterior agent to investigate delicate information or analysis statistical strategies for a specific drawback. Precise information sharing could be sophisticated by privateness and industrial considerations. Artificial counterparts present a handy answer to this drawback.
Situation 2. Organizations need to prepare fashions on comparatively small datasets. Nevertheless, this dataset shouldn’t be enough to acquire the specified high quality of modeling. Such restricted datasets could be expanded with artificial information. This artificial information should be just like actual information and is meant to enhance mannequin efficiency or, in some instances, to assist in mannequin reliability testing.
General, this tutorial presents and explains the next metrics:
- Precise information similarity (Sc. 1 and a pair of);
- distance metric,
- identification index,
- Most common discrepancy rating
2. Prediction consistency (Sc. 1);
3. Downstream effectiveness (Sc. 2);
4. Privateness (Sc. 1);
5. Range (Sc. 1 and Sc. 2);
6. Equity (Sc. 1 and Sc.2);
7. Visible comparability (Sc. 1 and a pair of).
In TSGM, all metrics are neatly organized in tsgm.metrics.Discover out extra at our comprehensive documentation.
Subsequent, let’s set up tsgm and begin the coding instance.
pip set up tsgm
Generate artificial information. Subsequent, import tsgm and cargo the instance dataset. Tensor Xr now incorporates 100 sine or fixed time collection (primarily based on course class yr). Use (Xr, yr) like this: real (= historic = authentic) dataset. Xs incorporates artificial information generated by a variational autoencoder. (Word: We use just one epoch for demonstration. Improve the variety of epochs in real-world functions and verify the coaching convergence.)
import numpy as np
import functools
import sklearn
import tensorflow as tf
from tensorflow import keras
import tsgm
n, n_ts, n_features = 100, 100, 20
vae_latent_dim = 8
# Load information that might be used as actual
Xr, yr = tsgm.utils.gen_sine_vs_const_dataset(n, n_ts, n_features, max_value=2, const=1)
Xr = Xr.astype(np.float32)
yr = keras.utils.to_categorical(yr).astype(np.float32)
ys = yr # use actual labels as artificial labels
# Utilizing actual information generate artificial time collection dataset
scaler = tsgm.utils.TSFeatureWiseScaler()
scaled_data = scaler.fit_transform(Xr)
structure = tsgm.fashions.zoo["cvae_conv5"](n_ts, n_features, vae_latent_dim)
encoder, decoder = structure.encoder, structure.decoder
vae = tsgm.fashions.cvae.cBetaVAE(encoder, decoder, latent_dim=vae_latent_dim, temporal=False)
vae.compile(optimizer=keras.optimizers.Adam())
# Prepare VAE utilizing historic information
vae.match(scaled_data, yr, epochs=1, batch_size=64)
Xs, ys = vae.generate(ys)
d_real = tsgm.dataset.Dataset(Xr, yr)
d_syn = tsgm.dataset.Dataset(Xs, ys)
Similarity to actual information
distance metric
First, it’s helpful to measure the similarity between actual and artificial information. One strategy to doing that is to calculate the gap between the vector of abstract statistics for the artificial information and the precise information.
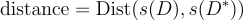
The smaller the gap, the nearer the artificial information is to the fact of the true information. Now let’s outline a set of statistics that may function the premise for our distance metric. The strategies tsgm.metrics.statistics.axis_*_s calculate statistics * in regards to the specified axes.
statistics = [
functools.partial(tsgm.metrics.statistics.axis_max_s, axis=None),
functools.partial(tsgm.metrics.statistics.axis_min_s, axis=None),
functools.partial(tsgm.metrics.statistics.axis_max_s, axis=1),
functools.partial(tsgm.metrics.statistics.axis_min_s, axis=1)]
Subsequent, let’s set up a distance metric. For simplicity, we select the Euclidean commonplace.
discrepancy_func = lambda x, y: np.linalg.norm(x - y)
To place all this collectively, we make the most of the tsgm.metrics.DistanceMetric object.
dist_metric = tsgm.metrics.DistanceMetric(
statistics=statistics, discrepancy=discrepancy_func
)
print(dist_metric(d_real, d_syn))
MMD metrics
One other strategy includes evaluating the artificial information distribution to the precise information distribution.On this context, using most imply distinction (MMD) [3] You will see that it helpful. MMD acts as a nonparametric two-sample take a look at to find out whether or not samples are drawn from the identical distribution. By means of empirical observations, we recognized his MMD metric to be a very helpful technique for evaluating the similarity of actual information.
mmd_metric = tsgm.metrics.MMDMetric()
print(mmd_metric(Xr, Xs))
identification index
On this strategy, a mannequin is skilled to tell apart between actual and artificial information. In TSGM, you’ll find that tsgm.metrics.DiscriminativeMetric is a great tool for this function. This metric facilitates analysis of how successfully a mannequin can distinguish between actual and artificial datasets and supplies an extra perspective on information similarity.
# use LSTM classification mannequin from TSGM zoo.
mannequin = tsgm.fashions.zoo["clf_cl_n"](
seq_len=Xr.form[1], feat_dim=Xr.form[2], output_dim=1).mannequin
mannequin.compile(
tf.keras.optimizers.Adam(),
tf.keras.losses.CategoricalCrossentropy(from_logits=False)
)
# use TSGM metric to measure the rating
discr_metric = tsgm.metrics.DiscriminativeMetric()
print(
discr_metric(
d_hist=Xr, d_syn=Xs, mannequin=mannequin,
test_size=0.2, random_seed=42, n_epochs=10
)
)
consistency metric
Subsequent, transfer on to consistency metrics.the mind-set is identical Situation 1 It is written above. Right here we give attention to assessing the consistency of a set of downstream fashions. In additional element, contemplate a set of fashions ℳ and an evaluator E: ℳ × 𝒟 → ℝ.
To judge the consistency of ℳ in D and D*, we measure p(m₁ 〜 m₂| m₁, m₂ ∈ ℳ, D, D*). Right here, m₁ ~ m₂ means m₁ matches m₂. For D, D* is healthier than m₂ and vice versa. ” To estimate this likelihood, we have to repair the finite set ℳ, consider the mannequin utilizing actual information, and consider the mannequin individually utilizing artificial information.
In TSGM, step one is to outline a set of raters. For this function, we make the most of a set of LSTM fashions spanning one to a few LSTM blocks.
class EvaluatorConvLSTM():
'''
NB an oversimplified classifier, for instructional functions solely.
'''
def __init__(self, mannequin):
self._model = mannequin
def consider(self, D: tsgm.dataset.Dataset, D_test: tsgm.dataset.Dataset) -> float:
X_train, y_train = D.Xy
X_test, y_test = D_test.Xy
self._model.match(X_train, y_train)
y_pred = np.argmax(self._model.predict(X_test), 1)
print(self._model.predict(X_test).form)
y_test = np.argmax(y_test, 1)
return sklearn.metrics.accuracy_score(y_pred, y_test)
# Outline a set of fashions
seq_len, feat_dim, n_classes = *Xr.form[1:], 2
fashions = [tsgm.models.zoo["clf_cl_n"](seq_len, feat_dim, n_classes, n_conv_lstm_blocks=i) for i in vary(1, 4)]
for m in fashions:
m.mannequin.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
evaluators = [EvaluatorConvLSTM(m.model) for m in models]
# Make the most of the set of evaluators with ConsistencyMetric from tsgm
consistency_metric = tsgm.metrics.ConsistencyMetric(evaluators=evaluators)
print(consistency_metric(d_real, d_syn, d_real))
downstream efficiency
Let’s now check out how the generated information can contribute to enhancing predictive efficiency in particular downstream issues. We contemplate two totally different approaches to evaluating downstream efficiency.
1. Increase actual information with artificial information.
This strategy could show helpful when information are restricted. By supplementing actual information with generated counterparts, we intention to counterpoint the coaching set and enhance mannequin efficiency. Take a look at our weblog put up on information augmentation. here [2].
2. The generated information is used just for coaching downstream fashions.
This strategy is beneficial in situations the place the precise information is missing and personal. Right here, the downstream mannequin is skilled solely on the generated information after which evaluated on actual information.
downstream_model = tsgm.fashions.zoo["clf_cl_n"](seq_len, feat_dim, n_classes, n_conv_lstm_blocks=1).mannequin
downstream_model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
evaluator = EvaluatorConvLSTM(downstream_model)
downstream_perf_metric = tsgm.metrics.DownstreamPerformanceMetric(evaluator)
print(downstream_perf_metric(d_real, d_syn, d_real))
This end result reveals an enchancment in accuracy by augmenting with artificial information in comparison with a mannequin skilled on coaching information solely.
Privateness: Membership Inference Assault Metrics
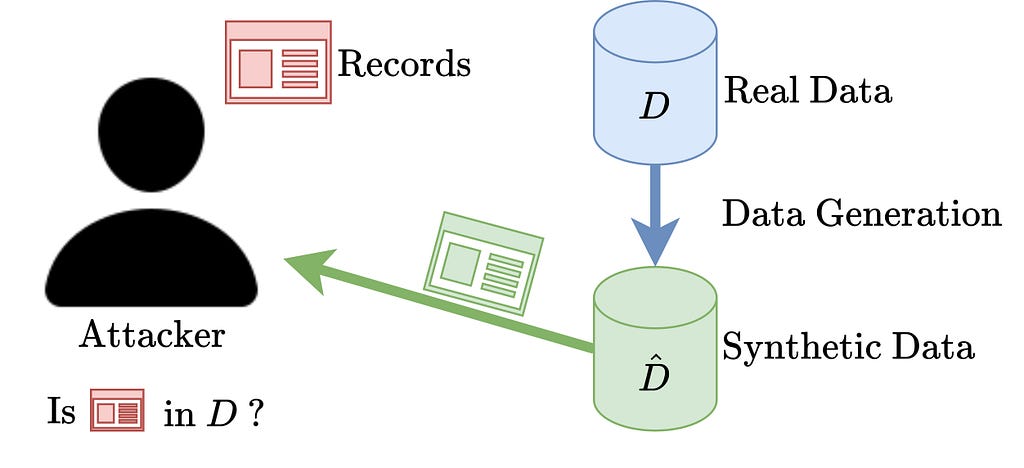
One strategy to measuring the privateness of artificial information is to measure its susceptibility to membership inference assaults. The steps of a membership inference assault are visually illustrated within the diagram above. This is an thought: Think about that an attacker has entry to artificial information and particular information samples (which can or might not be current within the authentic dataset). The aim is to **infer** whether or not this pattern exists within the precise information.
‘tsgm.metrics.PrivacyMembershipInferenceMetric’ makes use of artificial information to measure susceptibility to membership inference assaults. The step-by-step analysis process is printed beneath.
1. Splitting information. Break up the historic information right into a coaching set and a holdout set (denoted as Dₜ and Dₕ).
2. Coaching generative fashions. Prepare a generative mannequin on Dₜ and generate an artificial dataset D*.
3. Coaching a one-class classification (OCC) mannequin. Prepare a one-class classification (OCC) mannequin on artificial information D* and consider it on Dₜ and Dₕ.
4. Goal rating calculation. Use 1 minus the accuracy of the OCC mannequin because the goal rating.
This analysis course of supplies perception into potential vulnerabilities to membership inference assaults leveraging artificial information.
Subsequent, let’s introduce the attacker mannequin. For demonstration functions, we outline her SVM classifier for one class.
class FlattenTSOneClassSVM:
def __init__(self, clf):
self._clf = clf
def match(self, X):
X_fl = X.reshape(X.form[0], -1)
self._clf.match(X_fl)
def predict(self, X):
X_fl = X.reshape(X.form[0], -1)
return self._clf.predict(X_fl)
attacker = FlattenTSOneClassSVM(sklearn.svm.OneClassSVM())
privacy_metric = tsgm.metrics.PrivacyMembershipInferenceMetric(
attacker=attacker
)
Subsequent, let’s outline a take a look at set and measure privateness metrics.
X_test, y_test = tsgm.utils.gen_sine_vs_const_dataset(10, 100, 20, max_value=2, const=1)
d_test = tsgm.dataset.Dataset(X_test, keras.utils.to_categorical(y_test))
# 1 signifies excessive privateness and 0 -- low privateness.
privacy_metric(d_real, d_syn, d_test)
Range
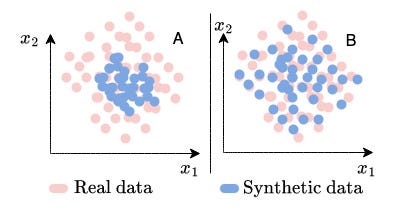
Utilizing this metric, our aim is to quantify the range of artificial information. Take into account the picture beneath. Crimson dots signify actual information and blue dots signify artificial information. Which possibility produces a greater artificial dataset? The one on the precise appears extra advantageous, however why? The reply lies in its versatility, which may make it extra versatile and helpful. However range alone shouldn’t be sufficient. It is very important contemplate different metrics in parallel, reminiscent of distance and downstream efficiency. In our exploration, we use entropy for example the idea.
spec_entropy = tsgm.metrics.EntropyMetric()
print(spec_entropy(Xr))
print(spec_entropy(Xs))
equity
The subject of equity intersects with artificial time collection era in two essential methods. First, it is very important assess whether or not artificial information introduce new biases. Second, artificial information supplies a possibility to cut back biases inherent within the authentic information. Defining standardized procedures for checking equity typically proves tough because it will depend on the main points of the downstream drawback. Some instance metrics for measuring equity embrace demographic parity, the anticipated charge parity paradigm, and equality of alternative.
For instance, contemplate equality of alternative. Equality of alternative is used to evaluate whether or not a classifier predicts a most well-liked label (a label that confers a bonus or profit to an individual) and a specific attribute equally for all values of that attribute. It serves as a designed equity metric. [6]. This metric helps guarantee equity and equal remedy throughout numerous attribute values. An important instance of this metric is: [6]: “Suppose Glabdubdrib College accepts a rigorous arithmetic program for each Lilliputians and Brobdingnagians. Lilliputian secondary colleges supply a wealthy curriculum of arithmetic courses, and nearly all of college students Brobdingnagian secondary colleges don’t supply any arithmetic courses and in consequence, far fewer college students are eligible. The popular label “admission” for nationality (Lilliputian or Brobdingnagian) satisfies equality of alternative if the probabilities of being admitted are equal no matter whether or not an individual is an individual or a Brobdingnagian. ”
qualitative evaluation
The next strategies are helpful for qualitatively evaluating information:
a. Extract samples and visualize particular person samples from artificial and actual information.
b. Construct an embedding of the generated samples and visualize it utilizing, for instance, TSNE. Let’s take (b) for instance with TSGM.
tsgm.utils.visualize_tsne_unlabeled(Xr, Xs, perplexity=10, markersize=20, alpha=0.5)

Quote
This weblog put up is a part of the TSGM undertaking, which creates instruments to reinforce time collection pipelines by augmentation and artificial information era. In the event you discover it helpful, please contemplate looking the repository and citing papers on TSGM.
@article{
nikitin2023tsgm,
title={TSGM: A Versatile Framework for Generative Modeling of Artificial Time Sequence},
creator={Nikitin, Alexander and Iannucci, Letizia and Kaski, Samuel},
journal={arXiv preprint arXiv:2305.11567},
12 months={2023}
}
conclusion
In conclusion, we now have thought of totally different analysis strategies for artificial time collection information and supplied a complete overview of various situations. To implement these strategies successfully, it’s helpful to think about the situations described. In the end, selecting the best metric will rely on the downstream drawback, the appliance space, and the authorized rules governing the info used. The totally different set of metrics supplied is meant that will help you create a complete analysis pipeline tailor-made to your particular drawback.
References:
[1] Nikitin, A., Iannucci, L., Kaski, S., 2023. TSGM: A versatile framework for generative modeling of artificial time collection. arXiv preprint arXiv:2305.11567. alxiv link.
[2] Time collection growth, posts for information science, https://medium.com/towards-data-science/time-series-augmentations-16237134b29b.
[3] Gretton, A., Borgwardt, KM, Rasch, MJ, Schölkopf, B. and Smola, A., 2012. His 2 pattern take a look at of the kernel. Machine Studying Analysis Journal, 13(1), pp. 723-773. JMLR link.
[4] Wen, Q., Solar, L., Yang, F., Track, X., Gao, J., Wang, X., and Xu, H., 2020. Time collection information augmentation for deep studying: A survey. arXiv preprint arXiv:2002.12478. alxiv link.
[5] Wattenberg, M., Viégas, F., Hardt, M., 2016. Assault discrimination with smarter machine studying. Google Analysis, 17. Google research link.
[6] Machine Studying Glossary: Equity. Google developer weblog.
Google developer blog link.
All photographs are by the creator except in any other case famous. For extra materials on artificial time collection era, see: TSGM on GitHuband Subscribe to media posts.
“Assessing Artificial Time Sequence” was initially printed on “In the direction of Information Science on Medium” and individuals are persevering with the dialog by highlighting and responding to this story.

{kind=link}