


Do fashions symbolize factual information internally? On this publish, we introduce BizzaroWorld, a mechanistic interpretability research that makes an attempt to find reality recall circuits throughout the Gemma household of fashions utilizing 60 immediate pairs and activation patches throughout 20 information classes. The technical work right here is closely influenced by the work finished by Prakash et al.¹ who thought-about entity monitoring throughout the LLaMa sequence of fashions.
The purpose is to determine the place factual information resides throughout the transformer and whether or not that location is constant throughout mannequin scales. The complete codebase is available here.
Experimental setup
To start with, I wished to know why the logit distinction between a pair of unpolluted and corrupted prompts is a perfect strategy to clear up this drawback. The factual findings appeared much like entity findings reminiscent of Prakash et al. So I targeted on oblique object identification (IoI). This turns into clearer if you current three factual prompts and their clear targets.
- “While you combine pink paint and yellow paint, the result’s this” → “Orange”
- “Who wrote the epic Inferno” -> “Dante”
- “The Roman god Mercury matches the Greek god” → “Hermes”
To reply questions like this, it appeared to me that an LLM would do the next: want To search out entities inside a illustration. So I appeared for a extra detailed reply on how logit distinction and IoI work on this context. The ARENA course² was very useful on this regard. We measured the logit distinction between pairs of unpolluted and corrupted prompts as a result of we discovered that it supplied a transparent scalar sign appropriate for measuring the causal results of patch interventions.
Due to this fact, we designed a reality battery consisting of 60 clear/dangerous immediate pairs throughout 20 totally different classes of information.
Earlier than beginning my patching experiments, I wished to determine the pairs of prompts with the very best sign. These are the obvious logical variations between a clear run and a damaged run, and are helpful for making use of activation patches. So we created our personal metric to measure this. whole swingcompute the web impact of the patch on these pairs of prompts. Here is an instance of what I am speaking about.

My instinct was that the cleanest sign could be to calculate the logit distinction on each side and subtract them. It’s because the right-hand aspect (making use of a clear goal to a corrupted immediate) usually leads to a damaging logit distinction as proven above. So each values add as much as provide you with a pleasant optimistic scalar that you should use to kind all 60 immediate pairs you created.
This labored properly and created a CSV file with all prompts sorted within the following order: whole swing. I known as this the golden immediate pair and used it to create three experimental modes for every subsequent experiment.

And now we’re prepared to start out experimenting.
Separation of Gemma-2B parts
LLM is a large construction. You must be ruthlessly remoted to know what is going on on the place. Neel Nanda’s TransformerLens³ helped us do exactly that. I wished to hook into the remaining streams earlier than and after all of the totally different items of the puzzle, all related parts throughout all layers (consideration head and MLP sublayers). And that is precisely what I did. I ran 4 experiments and steadily refined the mannequin.
- Experiment 1 = Patch utility at ultimate token place
- Experiment 2 = Patch earlier than and after every sublayer
- Experiment 3 = Patching at entity token location
- Experiment 4 = Apply patch earlier than every consideration head
The numbers generated in these experiments highlighted the next clear findings: There are three ranges of reality replica circuitry throughout the Gemma mannequin household..
Section 1 — Storage (Layers 0-14, entity token location): Details are encoded as directions throughout the residual stream of entity tokens. The residual stream is causally dominant right here, contributing 40 instances the eye output and 18 instances the MLP output. 86.7% of the highest 15 immediate pairs emitted conserved indicators at layers 13-15, with a mean worst layer of 16.3 throughout all experimental modes (Pearson r between mannequin confidence and injury rating = -0.83).
Section 2 — Routing (Distributed Consideration Head): The indicators journey from the entity token place collectively by means of the eye head to the ultimate predicted place. There was no single individual in cost, however secondary individuals have been disproportionately energetic. For instance, it was energetic in 40% of the immediate pairs throughout experimental mode A. Nonetheless, the injury to particular person heads (ΔLD = -0.68) is negligible in comparison with the injury to the whole residual stream (ΔLD = -11.47).
Section 3 — Learn (layers 15-17, ultimate token place): Solutions are obtained, not calculated. The latter block is a pass-through. That’s, the sign is already encoded and easily learn out. This discovering was constant throughout all three experimental modes and 20 information classes.
Giant three-phase circuit: Gemma-12B-IT
I wished generalizable outcomes, so my subsequent step was to see if this sample additionally held true for a bigger mannequin, Gemma-12B-IT. I might have favored to have examined it on a bigger Gemma mannequin, reminiscent of Gemma-31B or Gemma-27B, however I used to be constrained by the college’s HPC disk area constraints, which I’ll focus on later. However, we have been capable of replicate your entire suite of 12B fashions, together with all experimental modes A, B, and C.
We discovered some attention-grabbing outcomes, however first, let’s assessment the place and the way these two architectures differ.
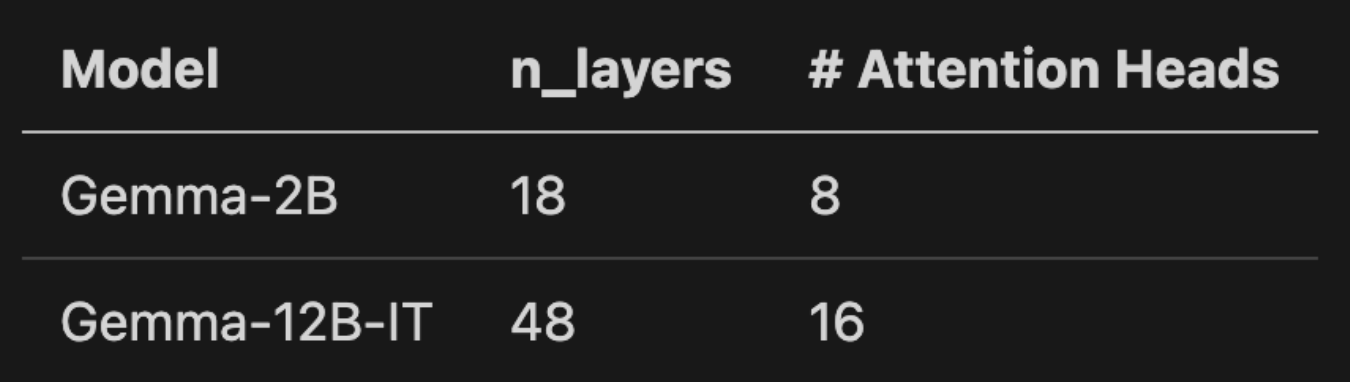
Along with these architectural variations, every thing else is identical between the 2 fashions, such because the tokenizer used⁴. Nonetheless, we noticed fairly a distinction in Gemma-12B-IT relating to the habits of the tokenizer that impacts the collection of immediate pairs.
As talked about above for rating the 60 immediate pairs, after we ran the primary triage cross, this huge Gemma mannequin eliminated three golden immediate pairs, despite the fact that they each used the identical tokenizer.
This exclusion happens as a result of the mannequin maps particular person tokens to a token ID array in the course of the ahead cross. For these paths to work, the form of the array should match all different shapes. If they do not match, matrix multiplication will not work. I noticed this once I ran this course of on Gemma-2B. We noticed some unusual habits there, such because the bodily unit “hertz” being mapped to 2 tokens⁵. Very unintuitive. I anticipated 60 prompts to cross by means of Gemma-12B-IT with none issues, however right here I used to be mistaken. This impact was clearly extra pronounced once I performed my first experiments with LLaMa-70B⁶. I am going to speak extra about this sooner or later work part beneath, however this shocked me.
In consequence, cross-model mechanistic comparisons are partially constrained by tokenizer-induced dataset drift, and reported variations ought to be interpreted with that in thoughts.
Due to this fact, earlier than designing a reality battery for such an experiment, you must run the information on all fashions beneath check. This may instantly report any tokenizer drift and can help you exchange affected immediate pairs earlier than beginning your experiment.
After noticing these anomalies, we carried out experiments 1–4 for all experimental modes A, B, and C.
It seems that this three-phase circuit has been replicated on a big scale. Storage is shifted to layers 0-27, wiring stays distributed with out a noticeably dominant head, and reads are concentrated within the ultimate layer, structurally equivalent to Gemma-2B and scaled proportionally.
Listed below are some diagrams illustrating this.
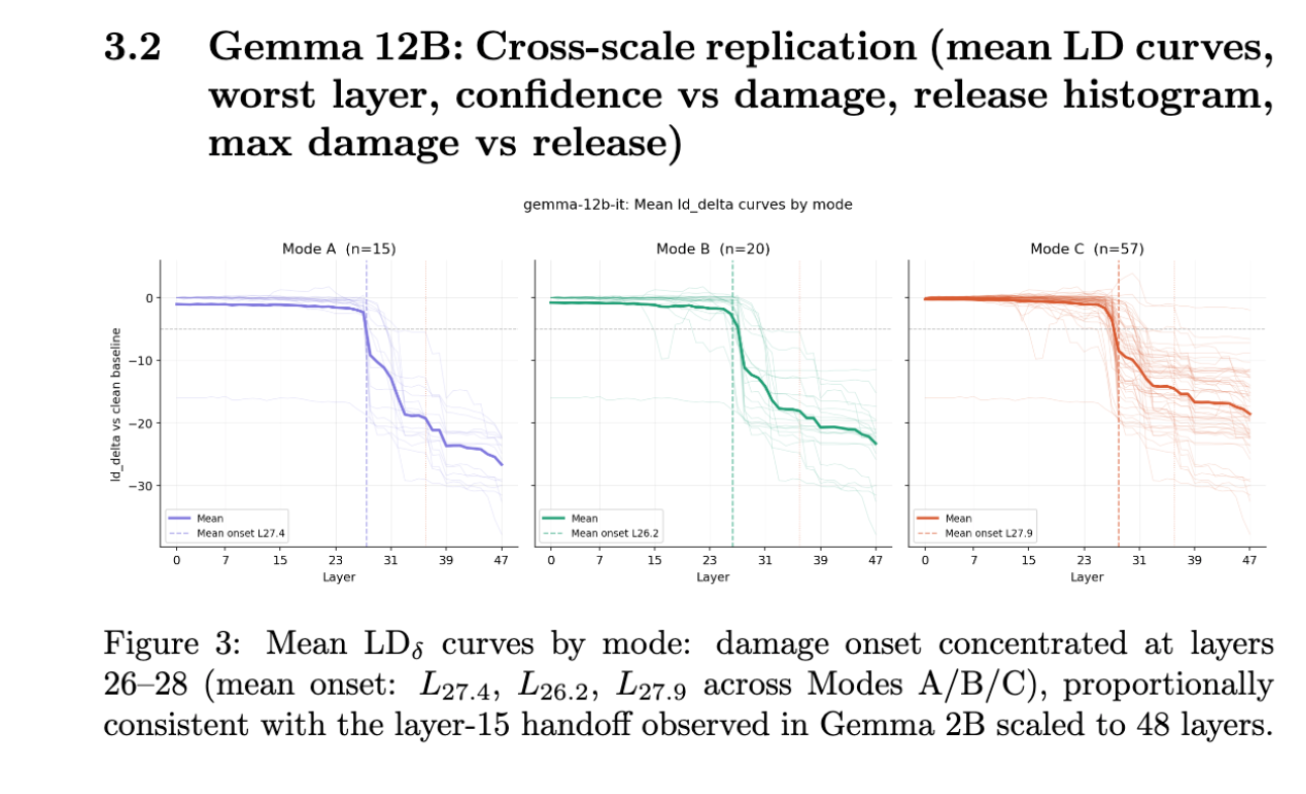
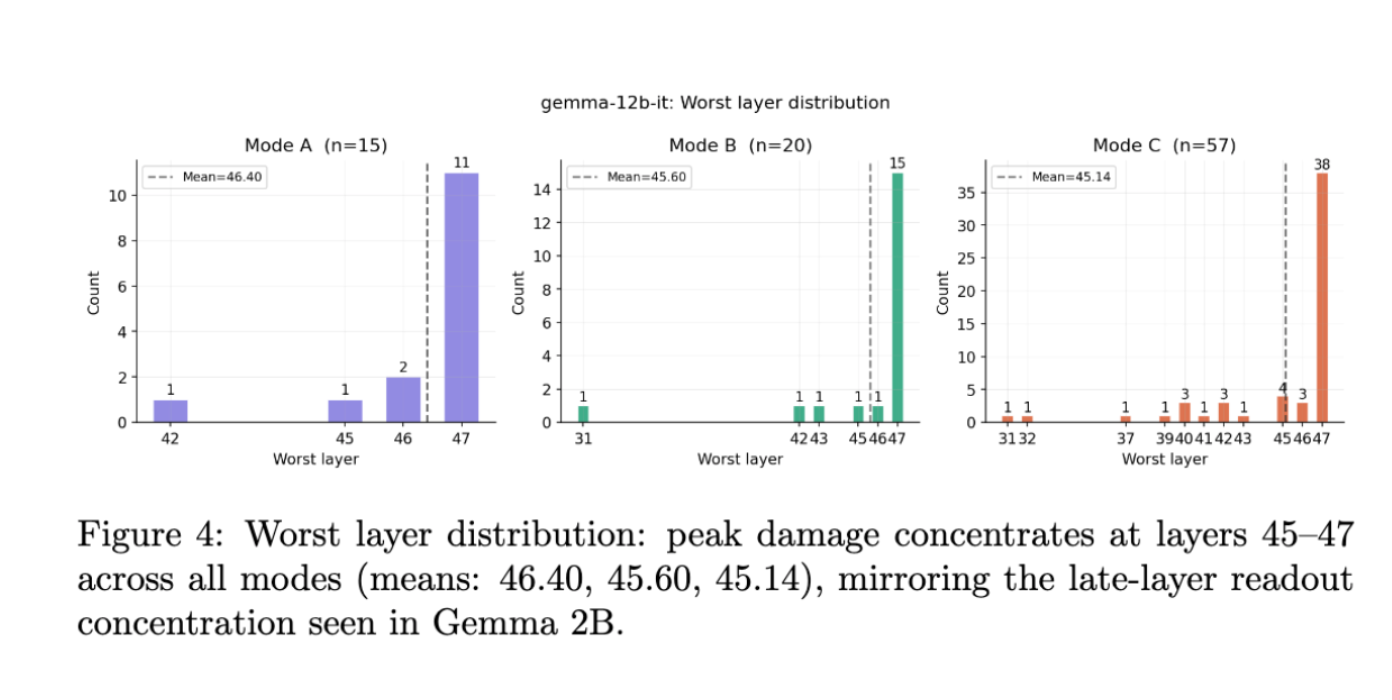
Every class of information confirmed a singular sample of habits, which was in keeping with my speculation.
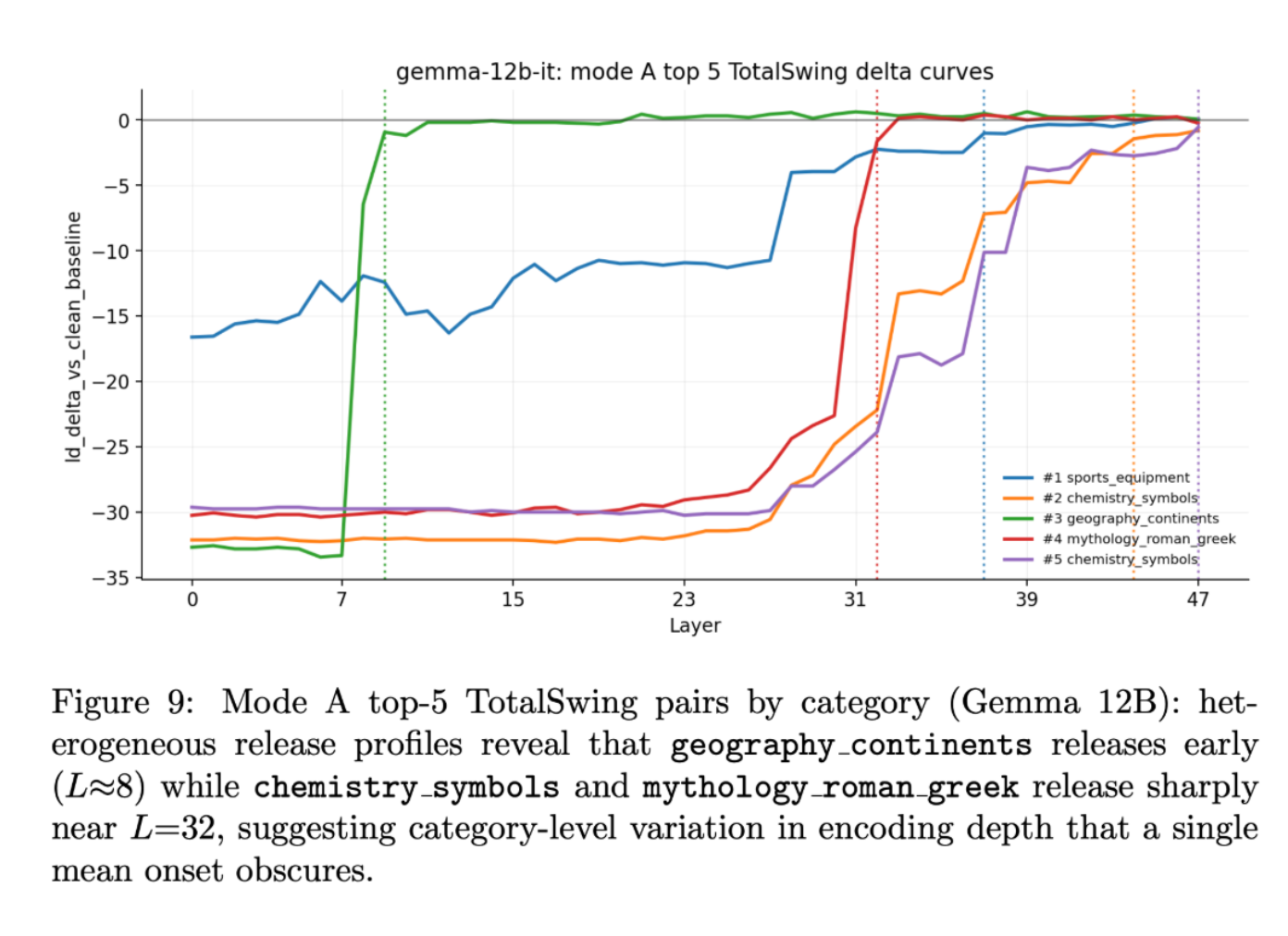
One other attention-grabbing factor I noticed was that the impact of the eye head on the Gemma-12B-IT appeared much more scattered and blunted than what I noticed on the Gemma-2B. This discovering is highlighted by the common ld_delta heatmap of the heads of curiosity for the 2 fashions above.
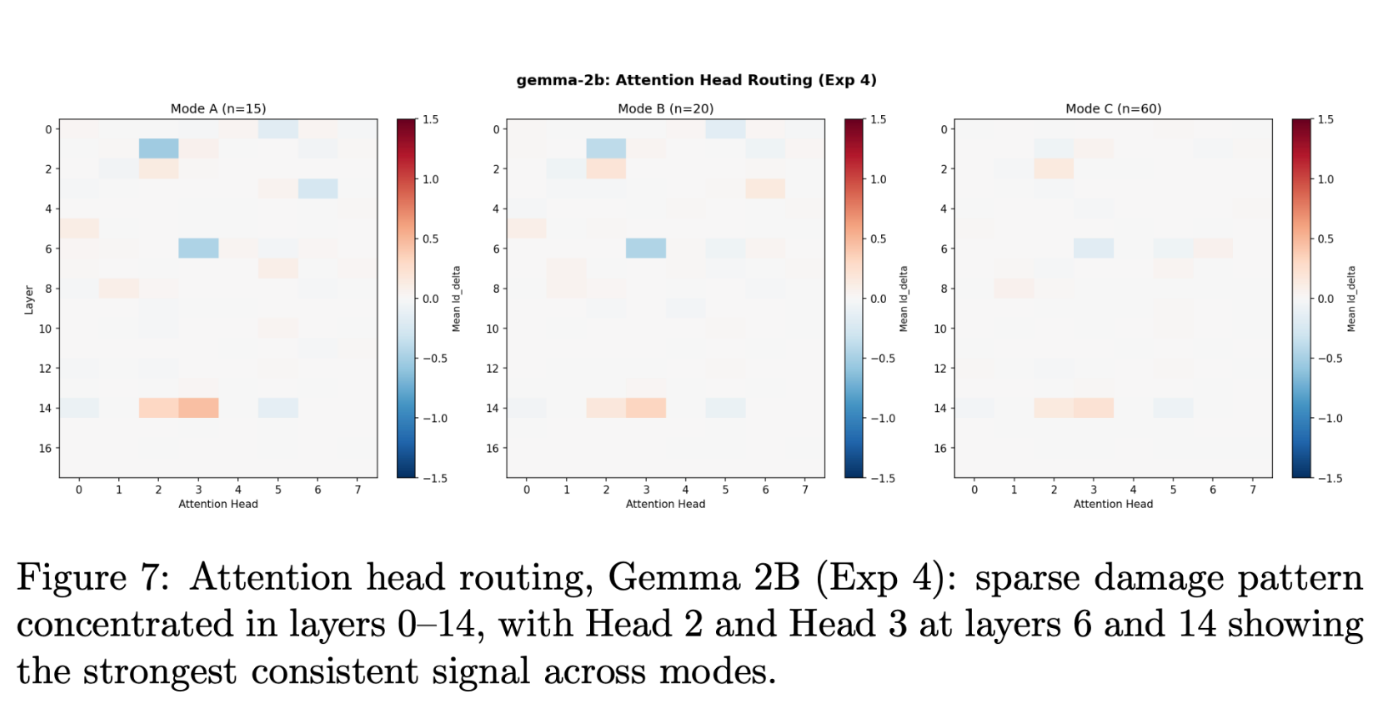
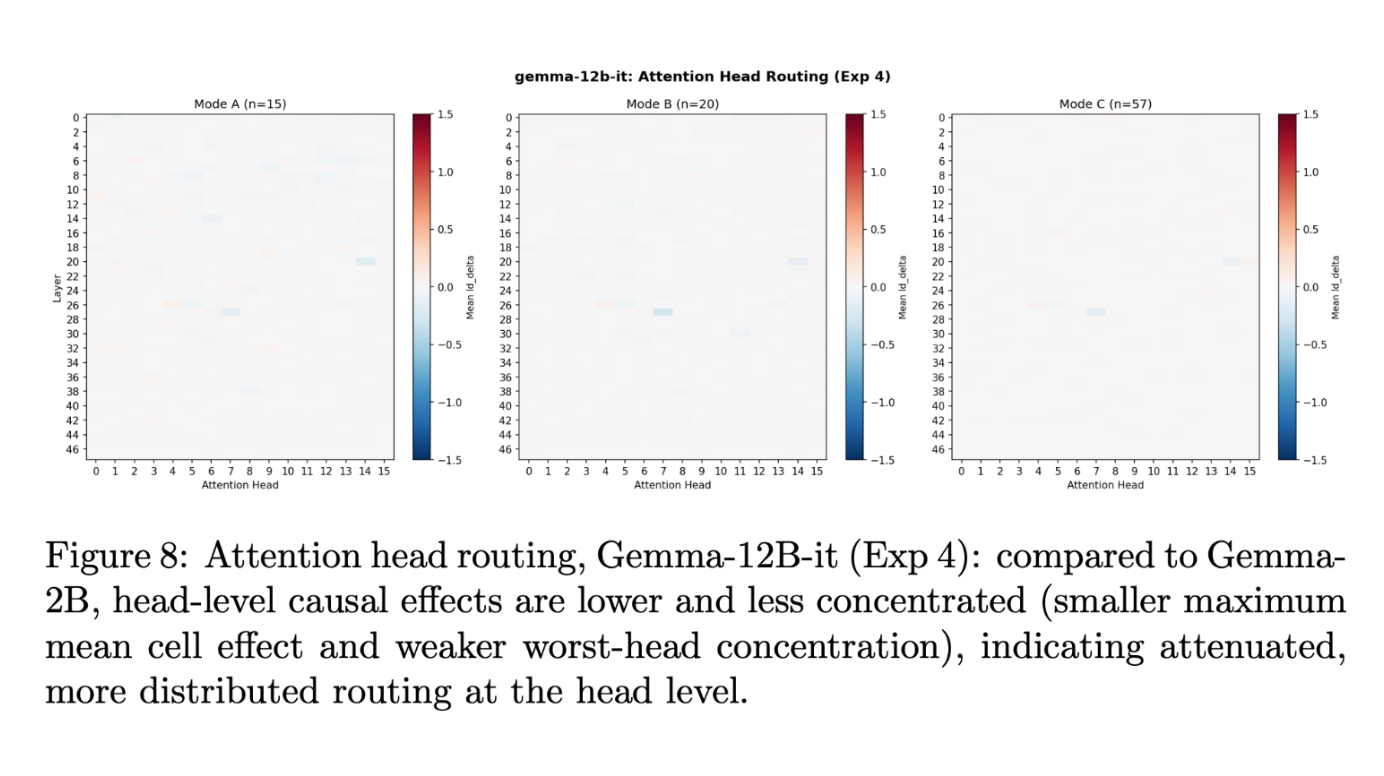
For Gemma-12B-IT, the warmth map is nearly utterly empty aside from small coloured cells round layers 20 and 28⁷. As soon as once more, the magnitude of the logit distinction values is way bigger for the residual stream than for these sublayer parts.
Disk quota points, future experiments, and conclusions
By means of this experimentation, I found many attention-grabbing strategies that I wish to attempt, reminiscent of path patching (utilizing DCM) and CMAP. We additionally wished to see if operating your entire pipeline with quantization or fine-tuned variants would change this three-stage reality replica circuit. Nonetheless, the 30 GB disk quota constraint was a bottleneck. The truth is, as prompt above, I had already ready an 8-bit quantized model of LLaMa-70B to handle the exclusion of twenty-two golden immediate pairs on account of tokenizer variations. Inference was working properly, however disk constraints prevented me from extending the method additional, so I put the thought on the again burner.
In my view, extending this work with path patching is a pure subsequent step because it exhibits extra. Path patching, formalized by Goldowsky-Dill et al.⁸, enhances activation patching from node-level to edge-level precision. Normal activation patching measures the general causal impact of a node by changing its output and observing all downstream penalties. As an alternative, path patching isolates particular person edges in a computational graph and divulges precisely which parts talk with which of them.
These findings set up the premise for focused interventions. Realizing the place factual recall exists is a prerequisite for understanding the place to intervene in case of failure. To take these concepts additional, I wish to implement my unique plan and see how the eye heads work collectively utilizing SAE. Sure, the remainder of the streams are doing the heavy lifting, however what does this imply? I want extra particulars.
In abstract, the logical subsequent transfer for this work is cross-architecture replication with LLaMA and different variants⁹. Moreover, the distributed routing discovery in Experiment 4 warrants path patching experiments to ascertain directed causal relationships between parts.
References
- Nikhil Prakash, Tamer Lot Shaham, Tal Hakley, Yonatan Belinkov, David Bowe. Enhancing current mechanisms with fine-tuning: An entity monitoring case research, 2024
- https://github.com/callummcdougall/ARENA_3.0
- https://github.com/TransformerLensOrg/TransformerLens
- Gemma makes use of the SentencePiece tokenizer
- As logically anticipated, one thing like a bodily unit “watt” was one token.
- LLaMa makes use of Tiktoken or SentencePiece tokenizers relying on the mannequin model
- In case you look intently, different cells are additionally highlighted, however they’re much duller in comparison with Gemma-2B.
- Nicholas Goldowski-Dill, Chris MacLeod, Lucas Sato, Aryaman Arora. Localizing mannequin habits by patching paths, 2023.
- It might be notably attention-grabbing to incorporate diffuse language fashions reminiscent of LLaDA-8B right here. It’s because the eye mechanism is basically totally different from normal autoregressive transformers and requires customized hook infrastructure past what TransformerLens presently helps.

{kind=link}