


Migrating a textual content agent to a voice assistant is more and more vital as a result of customers count on quicker, extra pure interactions. As an alternative of typing, clients need to communicate and perceive in actual time. Industries like finance, healthcare, schooling, social media, and retail are exploring options with Amazon Nova 2 Sonic to allow pure, real-time speech interactions at scale.
On this put up, we discover what it takes emigrate a standard textual content agent right into a conversational voice assistant utilizing Amazon Nova 2 Sonic. We evaluate textual content and voice agent necessities, spotlight design priorities for various use circumstances, break down agent structure, and tackle widespread considerations like instruments and sub-agents for reuse and system immediate adaptation. This put up helps you navigate the migration course of and keep away from widespread pitfalls.
You too can discover a Skill within the Nova pattern repo that works with AI IDEs like Kiro and Claude Code to robotically convert your textual content agent right into a voice agent.
Textual content brokers and voice brokers aren’t the identical downside
Whereas migrating from a textual content agent to a voice assistant would possibly look like including a voice interface whereas conserving the enterprise logic unchanged, it’s vital to grasp the variations from the next views.
| Side | Textual content agent | Voice agent |
| Consumer enter | Typed textual content: person reads, scrolls, copy-pastes at personal tempo | Spoken audio stream: actual time, can interrupt (barge-in), pauses matter |
| Response model | Paragraphs, lists, tables, hyperlinks: wealthy formatting, all data delivered without delay | Brief spoken phrases, one factor at a time: “Need me to proceed?” with affirmation loops |
| Latency price range | Mid-latency tolerance: typing indicator masks wait time | Extremely-low latency required: silence seems like one thing is damaged |
| Flip-taking | Strict request → response: person varieties, hits enter, waits | Fluid, overlapping, interruptible: voice exercise detection (VAD) + flip detection, barge-in required |
| Transport | HTTP / REST / Server-Despatched Occasions: stateless request-response | Bidirectional streaming: persistent connection, real-time audio in each instructions |
To higher navigate these challenges, let’s break down the important thing variations between textual content brokers and voice assistants and the way these variations influence design and implementation.
Response design
A textual content agent is constructed to ship paragraphs that customers can learn at their very own tempo. Scrolling again, copying content material, and following hyperlinks as wanted. A voice agent operates in a essentially totally different medium. Responses have to be conversational, concise, and thoroughly structured for listening reasonably than studying.Think about a banking agent that returns account info:
Textual content agent response:
Voice agent response:
“You may have three accounts. Your checking account ends in 4521 with a steadiness of three thousand 2 hundred forty-five {dollars}. Need me to undergo the others or would you want particulars on this one?”.
The voice agent breaks info into digestible chunks and asks for affirmation earlier than persevering with. It makes use of an autonomous dialog model, proactively guiding the person reasonably than dumping every part without delay.
Latency price range
Textual content customers have mid-latency tolerance. They see a typing indicator and wait. Voice customers discover delays nearly instantly. Silence in a voice dialog seems like the road went lifeless. This adjustments how brokers have to be architected:
| Issue | Textual content agent | Voice agent |
| Acceptable response time | Mid-latency tolerance: a number of seconds wait with a loading indicator is suitable. | Low-latency tolerance: dialog ought to be within the tons of of milliseconds, with first audio ASAP; delays of some seconds, particularly throughout device calls, really feel unresponsive. |
| Software name tolerance | A number of sequential calls OK | Every name provides noticeable silence |
| Streaming | Good to have | Important |
| Asynchronized device dealing with | Good to have | Important to have |
Amazon Nova 2 Sonic helps asynchronous device calling, so the dialog continues naturally whereas instruments run within the background. It retains accepting enter, can run a number of instruments in parallel, and gracefully adapts if the person adjustments their request mid-process, delivering all outcomes whereas specializing in what’s nonetheless related.
Flip-taking and interruption
Textual content conversations are inherently turn-based. The person varieties, hits enter, waits for a response. Voice conversations are fluid. Customers interrupt (barge-in), pause mid-sentence, and count on the agent to deal with overlapping speech naturally.Native speech-to-speech fashions like Amazon Nova 2 Sonic deal with this internally with built-in voice exercise detection (VAD) and switch detection. Nova 2 Sonic manages dialog context with out requiring the complete historical past to be despatched on every flip.
Migration from an architectural view
With these variations in thoughts, let’s break down the migration from an architectural perspective by dividing the system into three main parts and analyzing how every evolves.A conceptual design of a textual content agent consists of three parts:
- A consumer utility (corresponding to internet, cell, or IoT interfaces).
- A textual content orchestrator that manages the system immediate, instruments, and dialog context.
- The device integrations that connect with your programs, corresponding to APIs, databases, workflows, Retrieval Augmented Era (RAG) pipelines, or sub-agents.
When migrating this structure to a voice agent, these parts stay the identical, however every requires totally different adjustments to help voice-specific logic.
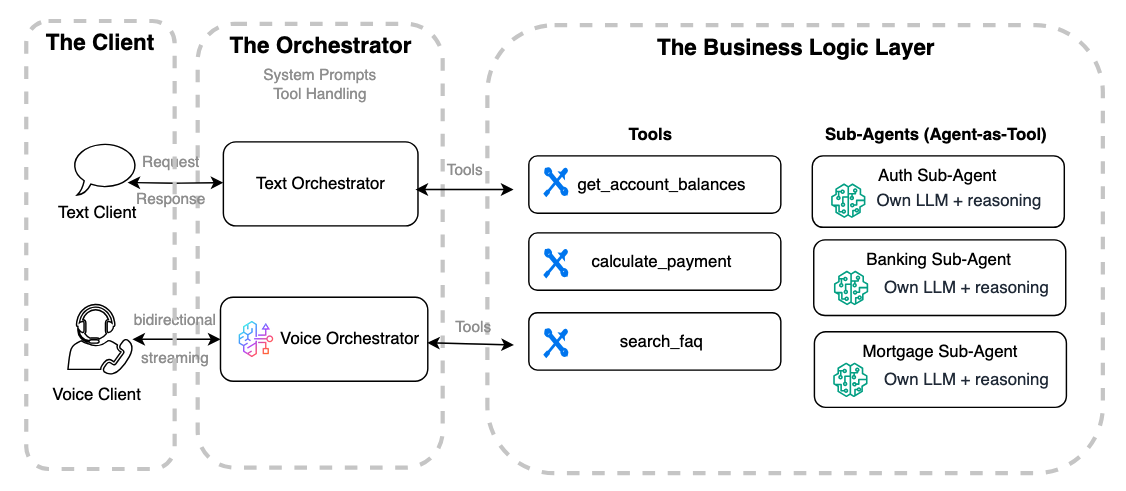
The consumer utility
Agent shoppers are sometimes carried out in programming languages and programs used for internet browsers, cell apps, or IoT units, relying on the deployment context.A voice agent consumer requires a persistent bidirectional connection (corresponding to WebSocket or WebRTC) and handles audio encoding/decoding, consumer occasions, barge-in logic, noise management, and transcription show. That is considerably extra advanced than a textual content consumer, which usually communicates with the agent by a stateless REST or one-way HTTPS streaming interface.
In consequence, this part normally requires refactoring or a full rewrite. For instance, a PoC constructed with a Streamlit frontend would possible should be rebuilt utilizing a JavaScript framework like React to help bidirectional connections.
For a light-weight voice agent internet consumer utility in REACT utilizing WebSocket, check with this sample.
The orchestrator
An agent orchestrator is the central hub when constructing textual content or voice brokers. It manages the system immediate, selects and routes instruments or sub-agents, and maintains dialog context to maintain interactions coherent and aligned with the agent’s function. In textual content brokers, the orchestrator handles requests and responses between the consumer and the reasoning mannequin whereas integrating instruments to set off enterprise logic. Voice orchestrators comply with the identical rules however add audio streaming, Voice Exercise Detection (VAD), Automated Speech Recognition (ASR), reasoning, and Textual content-to-Speech (TTS). Amazon Nova 2 Sonic presents a bidirectional streaming interface that mixes these options, so customers can migrate reasoning prompts and gear triggers from textual content brokers for a smoother transition to voice.
One key distinction from a standard text-agent structure is that Amazon Nova 2 Sonic can settle for each textual content and audio inputs in the identical mannequin interface. This implies Sonic can instantly change the standalone textual content reasoning mannequin sometimes utilized in a textual content orchestrator. As an alternative of chaining separate ASR → LLM → TTS parts, Sonic unifies speech recognition, reasoning, device use, and speech synthesis right into a single bidirectional mannequin. With this, groups can reuse current prompts and instruments whereas streamlining the structure, decreasing latency, and eradicating the necessity to handle a separate textual content reasoning mannequin within the voice stack.
The next code snippets present a pattern textual content agent constructed with Strands Agents utilizing Amazon Nova 2 Lite as the massive language mannequin (LLM). It has outlined instruments and a pattern utilizing Strands BidiAgent and Nova 2 Sonic to create a voice agent orchestrator out there by WebSocket. You’ll discover that the coding model for each textual content and voice brokers in Strands is extremely comparable. Whereas the pattern makes use of Strands, the identical strategy applies to textual content brokers constructed with different frameworks corresponding to LangChain, LangGraph, or CrewAI, as a result of the important thing inputs required from the textual content orchestrator are the system immediate and gear definitions.
Earlier than operating the samples within the following sections, set up Python and the required dependencies, together with strands-agents and Boto3, and ensure your IAM setup has the required permissions for the required companies.
from strands import Agent, device
from strands.fashions import BedrockModel
# ---- Mock instruments will likely be utilized in each textual content and voice brokers ----
@device
def authenticate_customer(account_id: str, date_of_birth: str) -> str:
"""Confirm buyer id and return an auth token."""
# In actual implementation, name your auth service / API
if account_id == "123456":
return "AUTH_TOKEN_ABC123"
return "Authentication failed"
@device
def get_account_balance(auth_token: str) -> str:
"""Return the client’s present account steadiness."""
if auth_token == "AUTH_TOKEN_ABC123":
return "Your present checking account steadiness is $5,420."
return "Unauthorized request"
@device
def get_recent_transactions(auth_token: str) -> str:
"""Return latest transactions."""
if auth_token == "AUTH_TOKEN_ABC123":
return "Latest transactions: $45 groceries, $120 utilities, $18 espresso."
return "Unauthorized request" Utilizing Strands Brokers, you may create a textual content agent orchestrator with Nova 2 Lite as proven within the following pattern:
# ---- Nova 2 Lite mannequin ----
mannequin = BedrockModel(model_id="amazon.nova-2-lite-v1:0")
# ---- Banking assistant textual content agent ----
bank_agent = Agent(
mannequin=mannequin,
system_prompt="""You're a banking assistant. Reply person questions on account balances, latest transactions precisely. At all times validate person id earlier than offering delicate info.
""",
instruments=[authenticate_customer, get_account_balance, get_recent_transactions],
) Utilizing the Strands BidiAgent, you may construct a voice agent orchestrator in an analogous coding model with the Nova 2 Sonic mannequin and reuse the identical instruments:
# voice_orchestrator.py — BidiAgent with sub-agents as instruments
from strands.experimental.bidi.agent import BidiAgent
from strands.experimental.bidi.fashions.nova_sonic import BidiNovaSonicModel
# ---- Nova 2 Sonic mannequin ----
mannequin = BidiNovaSonicModel(
area="us-east-1",
model_id="amazon.nova-2-sonic-v1:0",
provider_config={"audio": {"voice": "tiffany", "input_sample_rate": 16000, "output_sample_rate": 16000}},
)
# ---- Banking assistant voice agent ----
agent = BidiAgent(
mannequin=mannequin,
system_prompt=""" You're a banking assistant. Converse naturally and reply questions on account balances, latest transactions. Affirm the client’s id earlier than sharing delicate particulars. Use brief, clear responses and acknowledge when retrieving knowledge.
""",
instruments=[authenticate_customer, get_account_balance, get_recent_transactions],
)
await agent.run(inputs=[ws_input], outputs=[ws_output]) The system immediate is the muse for each textual content and voice brokers. It defines the agent’s function, tone, and guardrails, guaranteeing responses are constant, dependable, and aligned with enterprise objectives and person expectations throughout written and spoken interactions.When shifting from textual content to voice, adapt the system immediate for real-time audio. Preserve it concise and conversational, contemplate latency and multi-turn context, and break advanced steerage into smaller steps.
Textual content immediate (authentic):
“You’re a banking assistant. Reply person questions on account balances, latest transactions precisely. At all times validate person id earlier than offering delicate info.”
Voice-adapted immediate:
“You’re a banking assistant. Converse naturally and reply questions on account balances, latest transactions. Affirm the client’s id earlier than sharing delicate particulars. Use brief, clear responses and acknowledge when retrieving knowledge.”
Notice, that in a voice orchestrator with Nova 2 Sonic, you’re utilizing the Sonic built-in reasoning functionality to handle the system immediate and gear choice and session context. You now not want to supply your individual LLM for reasoning on the orchestrator degree.
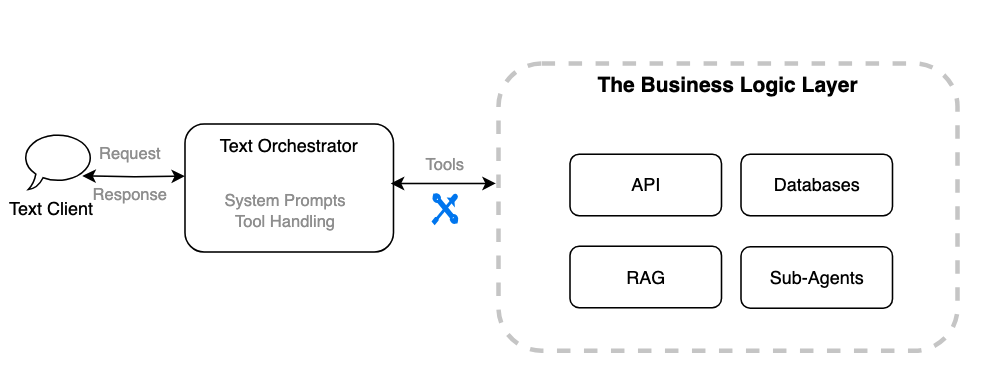
The enterprise logic layer
Software integration is a key facet of connecting an agentic assistant to the enterprise layer, utilizing protocols like Mannequin Context Protocol (MCP), Agent-to-Agent (A2A), and commonplace HTTP. In a text-based agent, the orchestrator sends textual content enter to instruments, like REST APIs, RAG system, or databases and receives textual content responses to generate user-facing replies.
Within the Strands Brokers samples, the identical instruments used for the textual content agent might be reused for the voice agent with no code adjustments. Nonetheless, reusing instruments and sub-agents for voice entails extra than simply implementation particulars.
Should you already use a multi-agent structure, your specialised enterprise logic brokers can usually be reused for voice with some updates. The next diagram exhibits a banking assistant the place a voice orchestrator calls sub-agents for authentication and mortgage inquiries.
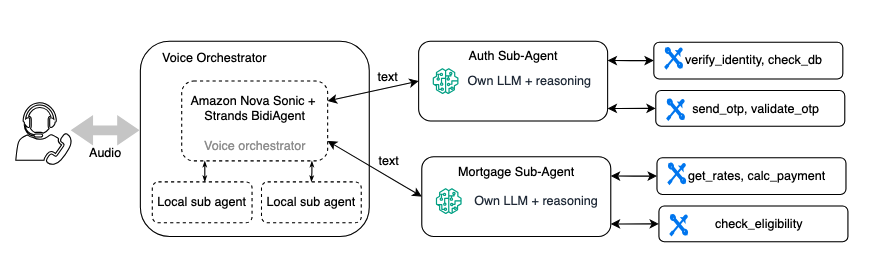
Though these sub-agents don’t require an entire rewrite, they do want tuning for voice:
Shorter responses – a textual content sub-agent would possibly return an in depth paragraph. A voice sub-agent ought to return 1–2 sentences that the orchestrator can communicate naturally. For instance, you replace the sub-agent’s system immediate to say, “Summarize in 1 to 2 concise sentences” as an alternative of “Present a complete reply.”
Latency enchancment – select smaller, quicker fashions for sub-agents (for instance, begins from Nova 2 Lite as an alternative of a bigger mannequin). In a voice dialog, each additional inference hop provides noticeable silence. For Nova 2 Lite, we advocate limiting or keep away from utilizing pondering mode, to scale back latency. For extra info, see the Amazon Nova Developer Information for Amazon Nova 2..
Diminished verbosity in device outcomes – some Sub-agents designed to return giant uncooked payloads, corresponding to JSON with extra knowledge than requested, leaving the orchestrator to filter the response. This isn’t perfect, particularly for voice. Bigger payloads improve latency, can scale back accuracy, and might expose delicate knowledge. Lean, focused responses are essential, notably for latency-sensitive voice experiences.
Use filler messages to maintain conversations pure throughout longer device processing. With Amazon Nova 2 Sonic, you may make asynchronous device calls and customise these interim messages, guaranteeing customers keep engaged whereas the agent completes duties.
Most of those changes contain immediate and configuration adjustments reasonably than architectural modifications. The sub-agent’s instruments, enterprise logic, and deployment stay the identical.Whereas sub-agent architectures present readability, reusability, and portability, and are particularly helpful when migrating a textual content agent to voice. Every sub-agent name provides latency as a result of its personal mannequin of inference and gear calls. In a voice dialog, this may translate to noticeable pauses for sub-agent causes.
Consult with this blog for extra voice agent structure patterns and greatest practices for managing latency.
Conclusion
Migrating a textual content agent to a voice assistant isn’t a wrapper job. The interplay mannequin is essentially totally different, from response design to latency budgets to turn-taking conduct. However with a well-structured multi-agent structure and Amazon Nova 2 Sonic, the enterprise logic layer stays intact.
Begin your migration venture and convert your textual content agent right into a voice assistant with Amazon Nova 2 Sonic. For an entire working instance of a voice agent utilizing Amazon Nova 2 Sonic, see the Amazon Nova 2 Sonic in Strands BidiAgent. Discover extra documentation and sources right here:
Concerning the authors

{kind=link}
{kind=link}