


Understanding what is going on on in an audio clip could be a troublesome downside at first look. Transcribing spoken phrases is simple. A very competent system should additionally acknowledge who’s talking, detect their emotional state, interpret background sounds, analyze musical content material, and reply time-based questions corresponding to “What did the speaker say on the finish of two minutes?” To sort out all of this, we would have liked to piece collectively a number of specialised programs.
Launched by OpenMOSS Staff, MOSI.AI and Shanghai Innovation Institute moss audio: An open supply speech understanding mannequin designed to combine all these options inside a single underlying mannequin.
How MOSS-Audio really works
MOSS-Audio assist Speech understanding, environmental sound understanding, music understanding, audio captioning, time-aware QA, and complicated reasoning on actual world audio. Its function set is split into a number of completely different areas. Speech and content material comprehension It precisely acknowledges and transcribes audio content material and helps each word-level and sentence-level timestamp adjustment. Evaluation of audio system, feelings, and occasions Determine speaker traits, analyze emotional state based mostly on tone, timbre, and context, and detect key acoustic occasions in audio. Extracting scenes and sound cues Extract significant indicators from background sounds, environmental noise, and non-speech indicators to deduce scene context and ambiance. understanding music Analyze musical kinds, emotional progressions, and instrumentation. Audio query solutions and summaries Deal with questions and summaries throughout speeches, podcasts, conferences, and interviews. Lastly, advanced reasoning Carry out multi-hop inference on audio content material by leveraging each chain-of-thought coaching and reinforcement studying.
In reality, a single MOSS-Audio mannequin can do the entire above with out having to change between varied devoted programs.
4 mannequin variations
The crew launched 4 variants at launch. MOSS-Audio-4B-Instruction, MOSS-Audio-4B-Considering, MOSS-Audio-8B-Instructionand MOSS-Audio-8B-Considering. When deciding which one to make use of, it is value understanding the naming conventions. of give directions Variants are optimized to observe direct directions and are perfect for manufacturing pipelines that require predictable and structured output. of thought The variant supplies extra highly effective chain-of-thought reasoning capabilities and is appropriate for duties that require multi-hop reasoning. The 4B mannequin makes use of: Quen 3-4B Used because the LLM spine, the 8B mannequin is Quen 3-8Bthe whole mannequin dimension is roughly 4.6B and eight.6B parameters, respectively.
Structure: Three parts working collectively
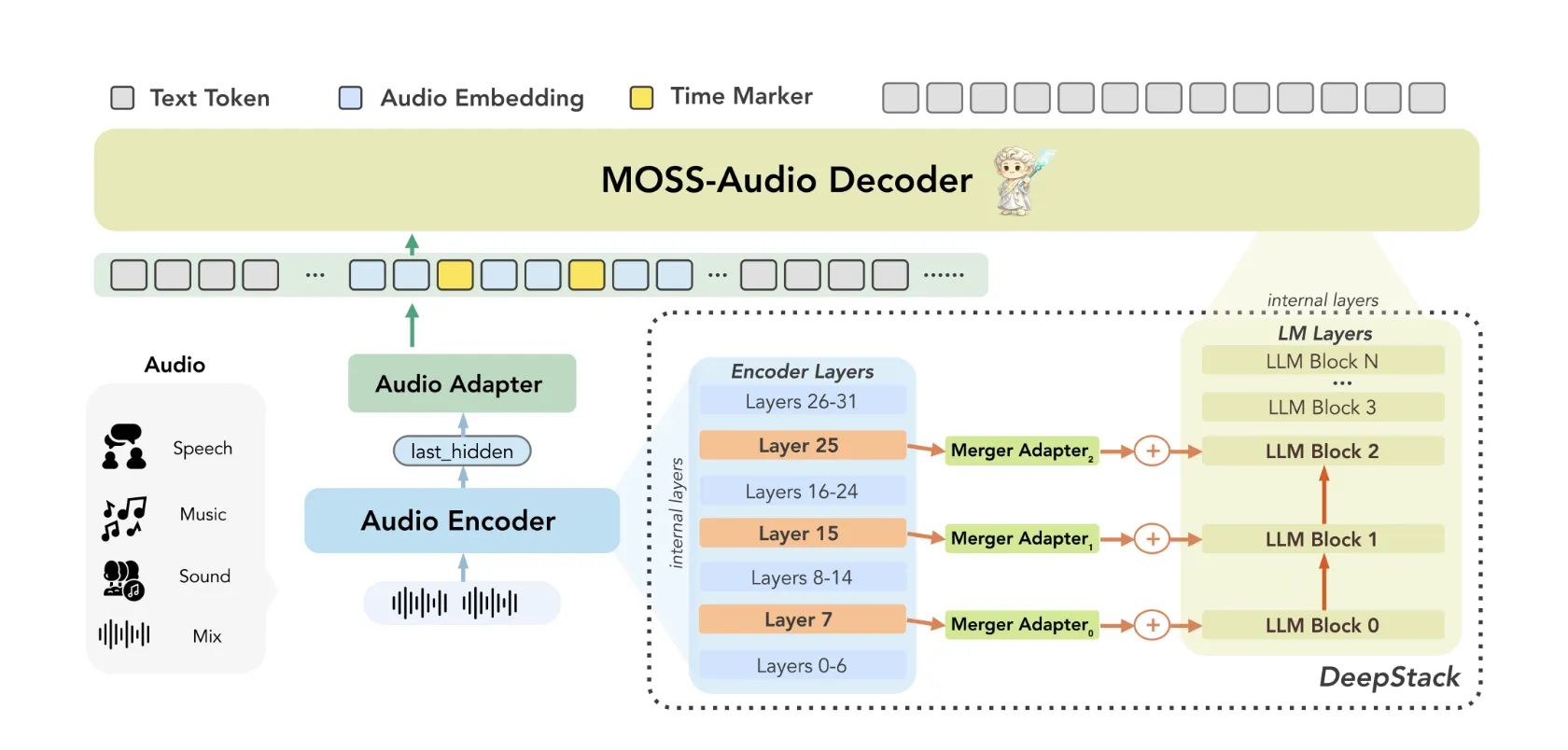
MOSS-Audio is Modular design with three parts: audio encoder, modality adapter, and enormous language mannequin. Uncooked audio is encoded first. MOSS audio encoder To steady time illustration in 12.5Hz. These representations are projected into the embedding area of the language mannequin via adapters and at last consumed by the LLM for autoregressive textual content era.
Reasonably than counting on an off-the-shelf audio entrance finish, the analysis crew educated the encoder from scratch. Their reasoning is {that a} devoted encoder supplies extra strong speech illustration, tighter temporal alignment, and better scalability throughout the acoustic area.
Two architectural improvements inside MOSS-Audio are value understanding in additional element.
DeepStack cross-layer function injection: A typical weak spot of audio fashions is that relying solely on top-layer options of the encoder tends to lose low-level acoustic info corresponding to prosody, transient occasions, and native time-frequency construction. MOSS-Audio takes care of this. deep stack– Impressed by the cross-layer injection module between encoder and language mannequin: Along with the ultimate layer output of the encoder, options from the preliminary and intermediate layers are chosen, independently projected, and injected into the preliminary layer of the language mannequin. This preserves multi-grained info starting from low-level acoustic particulars to high-level semantic abstractions, serving to the mannequin protect rhythm, timbre, transients, and background construction that can not be totally captured in a single high-level illustration.
expressions which can be aware of time: Time is a crucial consider audio, and textual content fashions aren’t outfitted to deal with it naturally. MOSS-Audio addresses this within the following approach. Insert time marker Technique throughout pre-training: Express time tokens are inserted between audio body representations at mounted time intervals to point temporal place. This enables fashions to study “what occurred when” inside a unified textual content era framework, naturally supporting timestamp ASR, occasion localization, time-based QA, and long-duration audio retrospectives. No separate localization head or post-processing pipeline is required.
benchmark efficiency
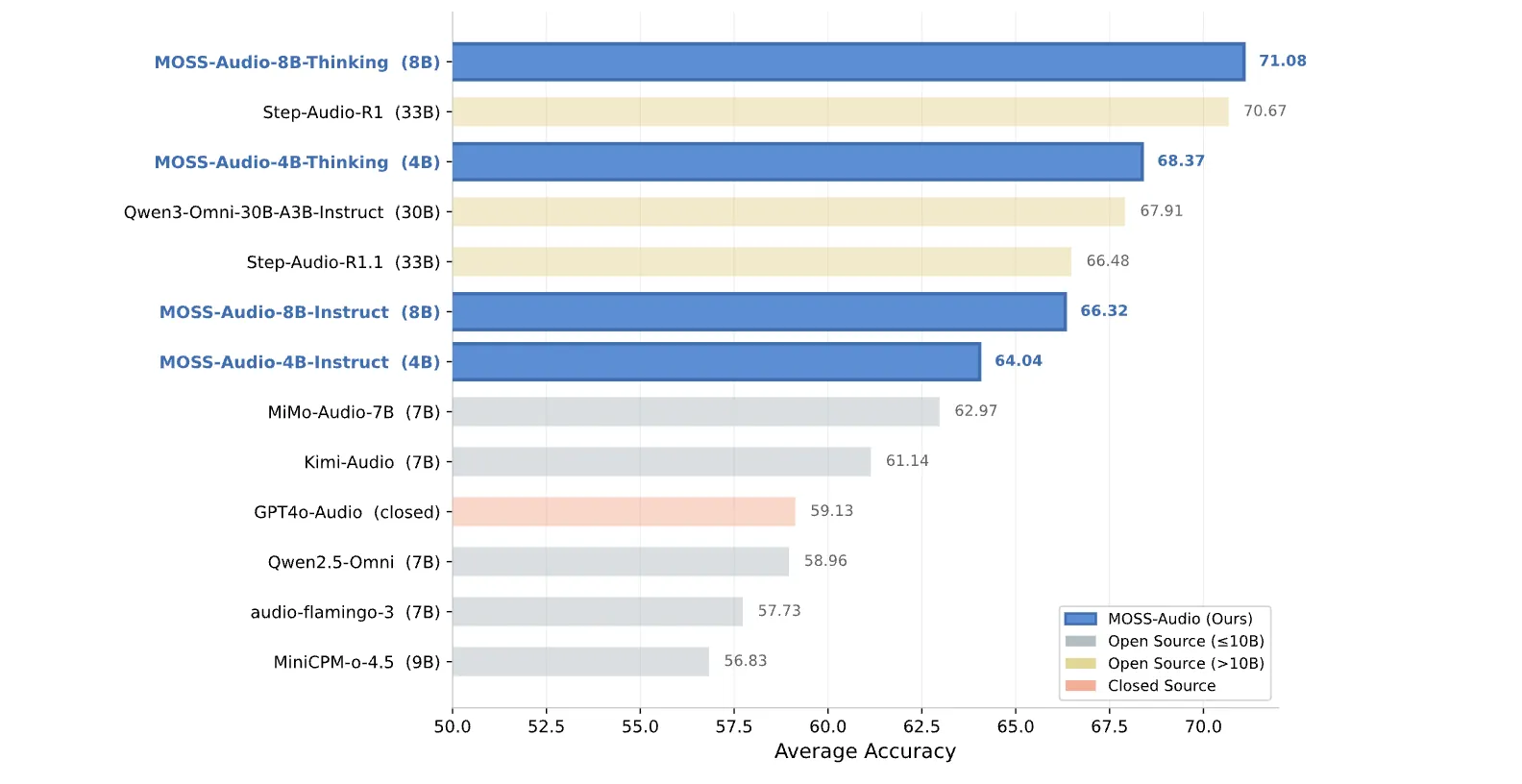
Numbers are highly effective. As for common audio understanding, MOSS-Audio-8B-Considering achieves a mean accuracy of 71.08 Throughout the 4 benchmarks — 77.33 at MMAU, 64.92 on MMAU-Professional, 66.53 in MMARand 75.52 at MMSUoutperforms most open supply fashions. This additionally contains bigger fashions. 33B’s Step-Audio-R1 rating is 70.67, and 30B’s Qwen3-Omni-30B-A3B-Instruct is 67.91. To elucidate additional, on the identical common, Kim-Audio (7B) has a rating of 61.14 and MiMo-Audio-7B has a rating of 62.97. The 4B Considering variant has a rating of 68.37. Which means our small mannequin with thought chain coaching outperforms all of our bigger open supply instruction-only rivals.
above speech captionsEvaluated with the LLM-as-a-Choose methodology throughout 13 detailed dimensions, together with , gender, age, accent, pitch, quantity, pace, texture, readability, fluency, emotion, tone, character, and abstract, MOSS-Audio-Instruct variants led in 11 out of 13 dimensions, with MOSS-Audio-8B-Instruct attaining the best total common rating. 3.7252.
above Automated speech recognition (ASR) MOSS-Audio-8B-Instruct spans 12 evaluation dimensions together with well being standing, code-switching, dialect, singing, and non-speech eventualities. Total CER (Character Error Price) is a minimum of 11.30 Throughout all fashions examined.
Essential factors
- Single mannequin, full audio stack: MOSS-Audio integrates audio transcription, speaker and sentiment evaluation, environmental sound understanding, music evaluation, audio captioning, time-aware QA, and complicated inference right into a single open-source mannequin, eliminating the necessity to chain collectively a number of specialised programs.
- Two architectural improvements drive efficiency: DeepStack Cross-Layer Function Injection preserves multi-grained acoustic info by instantly injecting options from intermediate encoder layers into the preliminary layer of the LLM. Alternatively, the insertion of time markers throughout pre-training offers the mannequin express time consciousness for timestamp-based duties.
- Greatest-in-class benchmark outcomes at environment friendly scale: MOSS-Audio-8B-Considering achieved a mean accuracy of 71.08 on the frequent speech understanding benchmark, outperforming all open supply fashions together with 30B+ programs, however solely the 4B Considering variant outperforming bigger open supply instruction-only rivals.
- Key Timestamp ASR Accuracy: MOSS-Audio-8B-Instruct scores 35.77 AAS on AISHELL-1 and 131.61 AAS on LibriSpeech, dramatically outperforming each Qwen3-Omni-30B-A3B-Instruct (833.66) and closed-source Gemini-3.1-Professional (708.24) in the identical benchmark.
Please verify model weights and lipo. Additionally, be happy to observe us Twitter Remember to hitch us 130,000+ ML subreddits and subscribe our newsletter. hold on! Are you on telegram? You can now also participate by telegram.
Must associate with us to advertise your GitHub repository, Hug Face Web page, product launch, webinar, and so on.?connect with us
The put up OpenMOSS releases MOSS-Audio: An open supply foundational mannequin for speech, sound, music, and time-aware audio inference appeared first on MarkTechPost.

{kind=link}