


Tabular information (structured info saved in rows and columns) is on the coronary heart of most real-world machine studying issues, from medical information to monetary transactions. Over time, fashions based mostly on determination bushes have been developed, resembling: random forest, XG increaseand cat increaseis now the default choice for these duties. Their strengths lie in dealing with combined information sorts, capturing advanced function interactions, and offering sturdy efficiency with out heavy preprocessing. Whereas deep studying has reworked fields resembling pc imaginative and prescient and pure language processing, it has traditionally struggled to constantly outperform these tree-based approaches on tabular datasets.
That long-standing pattern is now being known as into query. A more moderen method, TabPFNintroduces one other technique to method tabular issues, one which utterly avoids conventional dataset-specific coaching. Moderately than studying from scratch every time, it depends on a pre-trained mannequin to make predictions instantly, successfully shifting a lot of the training course of to inference time. On this article, we take a better take a look at this concept and take a look at it by evaluating TabPFN to established tree-based fashions resembling Random Forest and CatBoost on a pattern dataset and evaluating its efficiency when it comes to accuracy, coaching time, and inference velocity.
What’s TabPFN?
TabPFN is Plate basis mannequin It’s designed to course of structured information in a totally totally different means than conventional machine studying. Moderately than coaching a brand new mannequin for every dataset, TabPFN Pre-trained on tens of millions of artificial tabular duties Generated from causal processes. This can allow you to be taught normal methods for fixing supervised studying issues. Given a dataset, it leverages what it has already discovered to make predictions instantly, with out the iterative coaching of tree-based fashions. Basically, apply the next format: studying in context That is much like how large-scale language fashions work for textual content.
The newest model, TabPFN-2.5, considerably extends this concept by supporting bigger and extra advanced datasets whereas additionally bettering efficiency. What’s proven is Outperforms tuned tree-based fashions resembling XGBoost and CatBoost It improves efficiency on commonplace benchmarks and is similar to highly effective ensemble techniques like AutoGluon. On the similar time, the necessity for hyperparameter tuning and guide work is diminished. To make it sensible in real-world deployments, TabPFN distillation methodThat prediction can then be reworked right into a smaller mannequin, resembling a neural community or tree ensemble, permitting for a lot sooner inference whereas retaining a lot of the accuracy.

Comparability of TabPFN and tree-based fashions
Organising dependencies
pip set up tabpfn-client scikit-learn catboostimport time
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Fashions
from sklearn.ensemble import RandomForestClassifier
from catboost import CatBoostClassifier
from tabpfn_client import TabPFNClassifierA TabPFN API key’s required to run the mannequin. You may get the identical from https://ux.priorlabs.ai/home
import os
from getpass import getpass
os.environ['TABPFN_TOKEN'] = getpass('Enter TABPFN Token: ')Making a dataset
This experiment makes use of scikit-learn’s make_classification to generate an artificial binary classification dataset. The dataset accommodates 5,000 samples and 20 options, of which 10 are informative (truly contributing to the prediction of the goal) and 5 are redundant (derived from the informative options). This setting is beneficial for simulating life like tabular eventualities the place not all options are equally helpful and a few options are noisy or correlated.
Subsequent, consider the mannequin’s efficiency on the unseen information by splitting the info right into a coaching (80%) set and a take a look at (20%) set. Utilizing artificial datasets permits us to have full management over the traits of our information whereas making certain honest and reproducible comparisons between TabPFN and conventional tree-based fashions.
X, y = make_classification(
n_samples=5000,
n_features=20,
n_informative=10,
n_redundant=5,
random_state=42
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)Random Forest Take a look at
Begin with a random forest classifier as a baseline utilizing 200 bushes. Random Forest is a sturdy ensemble methodology that builds a number of determination bushes and aggregates their predictions, making it a robust and dependable selection for tabular information with out requiring intensive tuning.
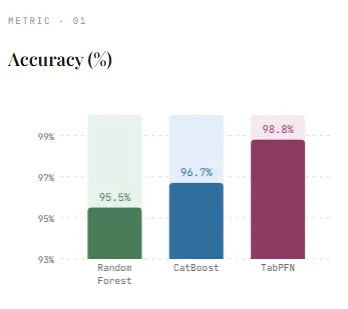
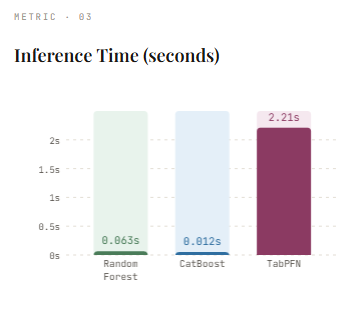
After coaching on the dataset, the mannequin achieves the next accuracy: 95.5%This can be a strong efficiency contemplating the artificial nature of the info. Nonetheless, this takes coaching time 9.56 This displays the price of constructing a whole bunch of bushes. The great factor is that inference is comparatively quick. 0.0627 Prediction takes just a few seconds because it simply passes the info by means of the already constructed tree. This end result serves as a powerful baseline for comparability with extra superior strategies resembling CatBoost and TabPFN.
rf = RandomForestClassifier(n_estimators=200)
begin = time.time()
rf.match(X_train, y_train)
rf_train_time = time.time() - begin
begin = time.time()
rf_preds = rf.predict(X_test)
rf_infer_time = time.time() - begin
rf_acc = accuracy_score(y_test, rf_preds)
print(f"RandomForest → Acc: {rf_acc:.4f}, Practice: {rf_train_time:.2f}s, Infer: {rf_infer_time:.4f}s")Testing CatBoost
Subsequent, prepare the CatBoost classifier, a gradient boosting mannequin designed particularly for tabular information. Construct the tree sequentially, every new tree fixing the errors within the earlier tree. CatBoost is often extra correct in comparison with Random Forest because of this boosting method and its skill to mannequin advanced patterns extra successfully.
On our dataset, CatBoost achieves the next accuracy. 96.7%outperforms random forests, demonstrating its energy as a state-of-the-art tree-based methodology. It additionally makes coaching barely sooner, 8.15 Regardless of utilizing 500 boosting iterations, sec. One among its largest benefits is inference velocity. Predictions are very quick, taking only one second. 0.0119 seconds, making it ideally suited for operational eventualities the place low latency is essential. This makes CatBoost a robust benchmark earlier than evaluating it to newer approaches resembling TabPFN.
cat = CatBoostClassifier(
iterations=500,
depth=6,
learning_rate=0.1,
verbose=0
)
begin = time.time()
cat.match(X_train, y_train)
cat_train_time = time.time() - begin
begin = time.time()
cat_preds = cat.predict(X_test)
cat_infer_time = time.time() - begin
cat_acc = accuracy_score(y_test, cat_preds)
print(f"CatBoost → Acc: {cat_acc:.4f}, Practice: {cat_train_time:.2f}s, Infer: {cat_infer_time:.4f}s")Testing TabPFN
Lastly, we consider TabPFN, which takes a basically totally different method in comparison with conventional fashions. Moderately than studying a dataset from scratch, leverage a pre-trained mannequin and easily situation the coaching information throughout inference. The .match() step primarily entails loading pre-trained weights, so it is extremely quick.
On our dataset, TabPFN achieves the very best accuracy. 98.8%outperforms each Random Forest and CatBoost. The set up time is simply 0.47 It’s considerably sooner than tree-based fashions as a result of no precise coaching is carried out. Nonetheless, this modification comes with trade-offs. Reasoning takes time. 2.21 That is a lot slower than CatBoost or Random Forest. It is because TabPFN processes each coaching and take a look at information collectively throughout prediction, successfully performing a “studying” step throughout inference.
Total, TabPFN reveals vital benefits when it comes to accuracy and setup velocity, but in addition highlights totally different computational trade-offs in comparison with conventional tabular fashions.
tabpfn = TabPFNClassifier()
begin = time.time()
tabpfn.match(X_train, y_train) # masses pretrained mannequin
tabpfn_train_time = time.time() - begin
begin = time.time()
tabpfn_preds = tabpfn.predict(X_test)
tabpfn_infer_time = time.time() - begin
tabpfn_acc = accuracy_score(y_test, tabpfn_preds)
print(f"TabPFN → Acc: {tabpfn_acc:.4f}, Match: {tabpfn_train_time:.2f}s, Infer: {tabpfn_infer_time:.4f}s")end result
All through our experiments, TabPFN offered the strongest total efficiency and achieved the very best accuracy (98.8%) Just about no coaching time required (0.47 seconds) Random Forest (9.56 seconds) and CatBoost (8.15 seconds). This highlights the important thing benefit of eliminating dataset-specific coaching and hyperparameter tuning whereas sustaining higher efficiency than established tree-based strategies. Nonetheless, this benefit comes with a tradeoff—Considerably increased inference latency (2.21 seconds)It is because the mannequin processes each coaching and take a look at information collectively throughout prediction. In distinction, CatBoost and Random Forest present a lot sooner inference and are subsequently higher suited to real-time functions.
From a sensible perspective, TabPFN could be very efficient within the following circumstances: Small to medium tabular dutiesspeedy experimentation, eventualities the place minimizing improvement time is essential. Manufacturing environments, particularly people who require low-latency predictions or course of very giant datasets, require new advances resembling: TabPFN distillation engine Reworking your mannequin right into a compact neural community or tree ensemble will help fill this hole. This considerably will increase inference velocity whereas preserving a lot of the accuracy. Moreover, it helps scaling to tens of millions of rows, making it extra viable for enterprise use circumstances. Total, TabPFN represents a shift in tabular machine studying, changing conventional coaching efforts with a extra versatile, inference-driven method.


Please examine Here is the complete code using notebook. Please be at liberty to observe us too Twitter Do not forget to affix us 130,000+ ML subreddits and subscribe our newsletter. grasp on! Are you on telegram? You can now also participate by telegram.
Must accomplice with us to advertise your GitHub repository, Hug Face Web page, product launch, webinar, and many others.?connect with us
The publish How TabPFN leverages in-context studying to realize superior accuracy on tabular datasets in comparison with Random Forests and CatBoost appeared first on MarkTechPost.

{kind=link}