


Massive-scale language fashions (LLMs) depend on reinforcement studying strategies to boost response era capabilities. One necessary facet of growth is reward modeling. This helps in coaching the mannequin and adjusts the mannequin to human expectations. Reward fashions consider responses primarily based on human choice, however present approaches typically endure from subjectivity and limitations in follow in accuracy. This will result in suboptimal efficiency, as fashions might prioritize stream ency over precision. Improved reward modeling utilizing verifiable correctness indicators may also help to extend the reliability of LLMs in real-world functions.
A serious problem in present reward modeling programs is to depend on human preferences which are subjective and liable to bias in nature. These fashions favor redundant responses or responses with engaging stylistic components, fairly than modifying redundant solutions. The dearth of systematic verification mechanisms in conventional reward fashions limits their potential to make sure correctness and makes them susceptible to misinformation. Moreover, constraints following directions are sometimes ignored, resulting in outputs that can’t meet the precise consumer necessities. To deal with these points, you will need to enhance the robustness and reliability of AI-generated responses.
Conventional reward fashions give attention to preference-based reinforcement studying, equivalent to reinforcement studying by way of human suggestions (RLHF). RLHF enhances mannequin alignment however doesn’t incorporate structured accuracy verification. Some present fashions try to judge responses primarily based on coherence and stream ency, however lack a sturdy mechanism to confirm de facto accuracy or compliance with directions. Different approaches equivalent to rule-based validation have been investigated, however haven’t been broadly built-in on account of computational challenges. These limitations spotlight the necessity for reward modeling programs that make sure the output of high-quality linguistic fashions, mixed with human choice verifiable.
Introducing by researchers from Tsinghua College Agent Reward Modeling (ARM)a brand new reward system that integrates conventional preference-based reward fashions with verifiable accuracy indicators. This technique features a named reward agent Reward agentcombines human choice indicators with accuracy verification to extend reward reliability. With this technique, LLM generates user-favorite responses and is just about correct. By integrating fact-verification and assessments following instruction, ARM provides a extra strong reward modeling framework that reduces subjective bias and improves mannequin alignment.
Reward agent The system consists of three core modules. router Analyze consumer directions to find out which validation brokers to activate primarily based on activity necessities. Verification Agent We consider the solutions on two necessary elements: de facto accuracy and adherence to exhausting constraints. Factuality Agent makes use of each parametric information and exterior sources to cross-check data to make sure that responses are correctly shaped and successfully grounded. An instruction-following agent ensures compliance with size, format, and content material constraints by parsing a selected instruction and verifying responses to predefined guidelines. The ultimate module, Juryintegrating correct indicators and precedence scores to calculate the general reward rating, balancing subjective human suggestions and goal verification. This structure permits the system to dynamically choose essentially the most applicable analysis standards for a wide range of duties, making certain flexibility and accuracy.
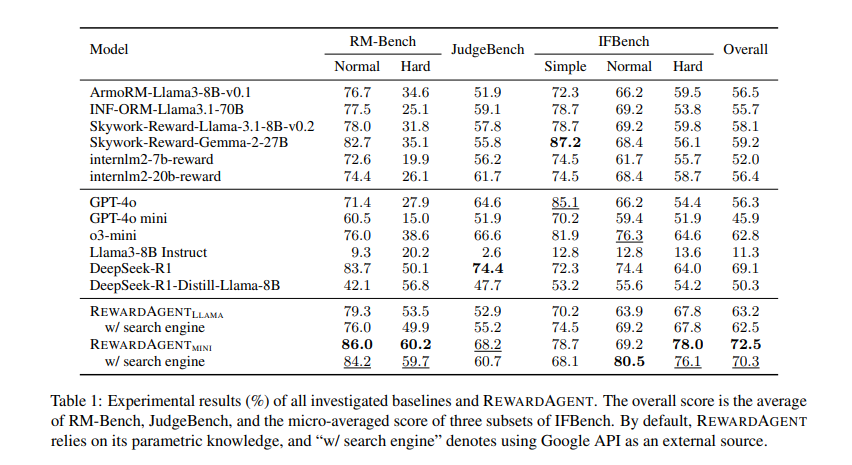
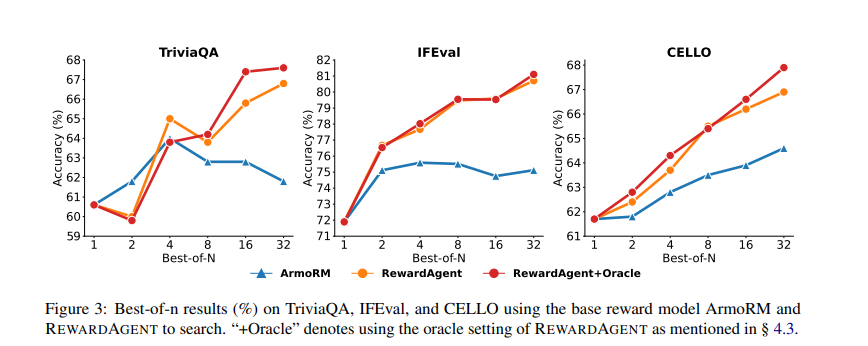
Intensive experiments have demonstrated this Reward agent It is considerably outperformed the normal reward mannequin. It was rated with the next benchmarks: RM Bench, Decide Bench, and ifbenchachieves glorious efficiency when choosing responses which are just about and conform to constraints. in RM Benchthe mannequin achieved a 76.0% Accuracy scores and utilizing serps 79.3% Evaluating with 71.4% From the normal reward mannequin. The system was additional utilized in the actual world Greatest-of-n Search Improved accuracy of response choice on duties, a number of datasets. Triviaqa, Ifeval, and Cello. Above Triviaqa, Reward agent Accuracy achieved 68%surpasses Base Reward Mannequin ARMORM. Moreover, the mannequin was used to assemble the popular pairs Direct Desire Optimization (DPO) Coachingif the LLMS skilled with Regidagent-jenerated Desire Pairs was higher than the one skilled with conventional annotations. Particularly, fashions skilled on this method are proven Bettering duties that observe fact-based questions and steeringdemonstrates its effectiveness in enhancing LLM alignment.
This examine addresses necessary limitations of reward modeling by integrating accuracy verification with human choice scoring. Reward agent It improves the reliability of the reward mannequin and allows LLM responses which are extra correct and supportive of instruction. This strategy paves the best way for additional analysis to include extra verifiable accuracy indicators, finally contributing to the event of extra dependable and competent AI programs. Future work will increase the scope of validation brokers to cowl extra complicated dimensions of accuracy and be sure that reward modeling will proceed to evolve with growing demand for AI-driven functions.
Check out paper and github page. All credit for this examine shall be despatched to researchers on this undertaking. Additionally, please be happy to observe us Twitter And do not forget to hitch us 80k+ ml subreddit.
🚨 Really helpful Reads – LG AI Analysis releases NEXUS: Superior Techniques that combine Agent AI Techniques and Knowledge Compliance Requirements to deal with authorized considerations in AI datasets
Nikhil is an intern marketing consultant at MarktechPost. He pursues an built-in twin diploma in supplies at Haragpur, Indian Institute of Know-how. Nikhil is an AI/ML fanatic and always researches functions in fields equivalent to biomaterials and biomedicine. With a robust background in materials science, he creates alternatives to discover and contribute to new developments.

{kind=link}