


In right now’s world, clip It is without doubt one of the most essential multimodal fundamental fashions. Mix visible and textual content alerts right into a shared function area utilizing a easy contrastive studying loss on giant image-text pairs. As an acquirer, CLIP helps many duties equivalent to zero-shot classification, detection, segmentation, and picture textual content search. Moreover, as a function extractor, it has change into mainstream in nearly all cross-modal illustration duties, equivalent to picture understanding, video understanding, and text-to-image/video era. Its power primarily lies in its capacity to affiliate photos with pure language and seize human information, as it’s skilled on large-scale internet information with detailed textual content descriptions, not like imaginative and prescient encoders. as Massive-scale language mannequin (LLM) Language is evolving quickly, and the boundaries of language understanding and manufacturing are consistently being pushed. LLM’s robust textual content abilities assist CLIP higher deal with lengthy and sophisticated captions, a weak point of the unique CLIP. LLMs even have intensive information of enormous textual content datasets, making coaching simpler. LLMs have robust comprehension abilities, however the best way they produce textual content hides their skills, making their output unclear.
Present developments have prolonged CLIP to deal with different modalities, rising its affect on this subject. like a brand new mannequin llama 3 By leveraging LLM’s open world information, it has been used to increase CLIP’s caption size and enhance efficiency. Nonetheless, incorporating LLM into CLIP is cumbersome as a consequence of textual content encoder limitations. In a number of experiments, by straight integrating, we get LLM into the clip It will result in decreased efficiency. Due to this fact, there are specific challenges that have to be overcome in an effort to discover the potential advantages of incorporating LLM into CLIP.
Tongji College and Microsoft Company Researchers performed an in depth investigation, LLM2CLIP An method to reinforce visible illustration studying by integrating large-scale language fashions (LLMs). This technique takes the straightforward steps of changing the unique CLIP textual content encoder and makes use of LLM’s intensive information to reinforce the CLIP visible encoder. We determine the important thing obstacles related to this revolutionary thought and suggest cost-effective fine-tuning methods to beat them. This technique radically replaces the unique CLIP textual content encoder. We acknowledge the challenges of this method and recommend inexpensive methods to fine-tune the mannequin to handle them.
of LLM2CLIP This technique successfully improved the CLIP mannequin by integrating large-scale language fashions (LLMs) equivalent to: llama. Initially, LLM struggled as a textual content encoder for CLIP as a result of it couldn’t clearly distinguish between picture captions. To deal with this, the researchers launched a caption distinction fine-tuning approach, which considerably improved the LLM’s capacity to separate captions. This tweak has resulted in important efficiency enhancements over current state-of-the-art fashions. The LLM2CLIP framework mixed an improved LLM with a pre-trained CLIP visible encoder to create a robust cross-modal mannequin. Though this technique used a big LLM, it maintained computational effectivity with minimal further price.
The experiments primarily targeted on fine-tuning the mannequin to enhance picture and textual content matching utilizing datasets equivalent to: CC-3M. For fine-tuning LLM2CLIP, three The dataset measurement was examined as follows: small (CC-3M), medium (CC-3M and CC-12M), and massive (CC-3M, CC-12M, YFCC-15M, and Recaption-1B). Coaching with augmented captions improved efficiency, however utilizing a language mannequin not skilled on CLIP led to worse efficiency. Fashions skilled on LLM2CLIP carry out higher than normal CLIP and EVA on duties equivalent to image-to-text conversion and text-to-image retrieval, integrating giant language and image-text fashions. The advantages of doing so had been highlighted.
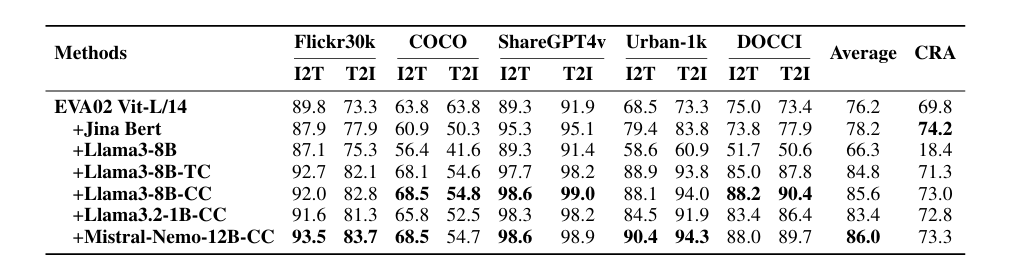
This technique straight improved the earlier efficiency. SOTA EVA02 Depends upon the mannequin 16.5% It handles each lengthy and quick sentence retrieval duties and transforms CLIP fashions skilled solely on English information into state-of-the-art cross-language fashions. After integrating multimodal coaching with a mannequin like mule 1.5outperforms CLIP on nearly all benchmarks, displaying a major general efficiency enchancment.

In conclusion, the proposed technique permits LLM to assist CLIP coaching. You possibly can modify the LLM to right the constraints of CLIP by adjusting parameters equivalent to information distribution, size, and class. This permits the LLM to behave as a extra complete instructor for a wide range of duties. Within the proposed work, the LLM gradient was frozen throughout fine-tuning to keep up a big batch measurement for CLIP coaching. Future work will permit LLM2CLIP to be skilled from scratch on datasets equivalent to: Laion-2Band and Abstract-1B For higher outcomes and efficiency. This end result can be utilized as a baseline for future analysis in CLIP coaching and its broader functions.
Please examine paper, codeand Models with hugging faces. All credit score for this research goes to the researchers of this venture. Remember to observe us Twitter and please be a part of us telegram channel and LinkedIn groupsHmm. In the event you like what we do, you may love Newsletter.. Remember to affix us 55,000+ ML subreddits.
[FREE AI WEBINAR] Implementing intelligent document processing with GenAI in financial services and real estate transactions
Divyesh is a consulting intern at Marktechpost. He’s pursuing a bachelor’s diploma in agricultural and meals engineering from the Indian Institute of Know-how, Kharagpur. He’s an information science and machine studying fanatic who desires to combine these cutting-edge applied sciences into the agricultural sector to unravel challenges.

{kind=link}