


Basis fashions (FMs) and huge language fashions (LLMs) have been quickly scaling, usually doubling in parameter depend inside months, resulting in important enhancements in language understanding and generative capabilities. This speedy progress comes with steep prices: inference now requires huge reminiscence capability, high-performance GPUs, and substantial vitality consumption. This development is obvious within the open supply house. In 2023, TII-UAE launched Falcon 180B, the most important open mannequin on the time. Meta surpassed that in 2024 with Llama 3.1, a 405B dense mannequin. As of mid-2025, the most important publicly accessible mannequin is DeepSeek (V3 – Instruct variant, R1 – Reasoning variant), a mix of consultants (MoE) structure with 671 billion complete parameters—of which 37 billion are lively per token. These fashions ship state-of-the-art efficiency throughout a variety of duties, together with multi-modal search, code technology, summarization, concept technology, logical reasoning, and even PhD-level downside fixing. Regardless of their worth, deploying such fashions in real-world purposes stays largely impractical due to their measurement, value, and infrastructure necessities.
We frequently depend on the intelligence of huge fashions for mission-critical purposes corresponding to customer-facing assistants, medical analysis, or enterprise brokers, the place hallucinations can result in severe penalties. Nonetheless, deploying fashions with over 100 billion parameters at scale is technically difficult—these fashions require important GPU assets and reminiscence bandwidth, making it tough to spin up or scale down situations rapidly in response to fluctuating person demand. In consequence, scaling to 1000’s of customers rapidly turns into cost-prohibitive, as a result of the high-performance infrastructure necessities make the return on funding (ROI) tough to justify. Put up-training quantization (PTQ) presents a sensible different; by changing 16- or 32-bit weights and activations into lower-precision 8- or 4-bit integers after coaching, PTQ can shrink mannequin measurement by 2–8 instances, scale back reminiscence bandwidth necessities, and pace up matrix operations, all with out the necessity for retraining, making it appropriate for deploying massive fashions extra effectively. For instance, the bottom DeepSeek-V3 mannequin requires an ml.p5e.48xlarge occasion (with 1128 GB H100 GPU reminiscence) for inference, whereas its quantized variant (QuixiAI/DeepSeek-V3-0324-AWQ) can run on smaller situations corresponding to ml.p5.48xlarge (with 640 GB H100 GPU reminiscence) and even ml.p4de.24xlarge (with 640 GB A100 GPU reminiscence). This effectivity is achieved by making use of low-bit quantization to much less influential weight channels, whereas preserving or rescaling the channels which have the best influence on activation responses, and conserving activations in full precision—dramatically lowering peak reminiscence utilization.
Quantized fashions are made potential by contributions from the developer group—together with tasks like Unsloth AI and QuixiAI (formerly: Cognitive Computations)—that make investments important time and assets into optimizing LLMs for environment friendly inference. These quantized fashions will be seamlessly deployed on Amazon SageMaker AI utilizing just a few traces of code. Amazon SageMaker Inference gives a completely managed service for internet hosting machine studying, deep studying, and huge language or imaginative and prescient fashions at scale in a cheap and production-ready method. On this publish, we discover why quantization issues—the way it permits lower-cost inference, helps deployment on resource-constrained {hardware}, and reduces each the monetary and environmental influence of recent LLMs, whereas preserving most of their authentic efficiency. We additionally take a deep dive into the rules behind PTQ and reveal the best way to quantize the mannequin of your selection and deploy it on Amazon SageMaker.
The steps are:
- Select mannequin
- Select WxAy method (WxAy right here implies weights and activations, which will likely be mentioned in depth later on this publish)
- Select algorithm (AWQ, GPTQ, SmoothQuant, and so forth)
- Quantize
- Deploy and inference
As an instance this workflow and assist visualize the method, we’ve included the next circulate diagram.
Conditions
To run the instance notebooks, you want an AWS account with an AWS Identification and Entry Administration (IAM) function with permissions to handle assets created. For extra data, see Create an AWS account.
If that is your first time working with Amazon SageMaker Studio, you first have to create a SageMaker area.
By default, the mannequin runs in a shared AWS managed digital personal cloud (VPC) with web entry. To reinforce safety and management entry, you must explicitly configure a personal VPC with applicable safety teams and IAM insurance policies primarily based in your necessities.
Amazon SageMaker AI gives enterprise-grade safety features to assist hold your knowledge and purposes safe and personal. We don’t share your knowledge with mannequin suppliers, offering you full management over your knowledge. This is applicable to all fashions—each proprietary and publicly accessible, together with DeepSeek-R1 on SageMaker. For extra data, see Configure safety in Amazon SageMaker AI.
As a finest follow, it’s at all times beneficial to deploy your LLM’s endpoints inside your VPC and behind a personal subnet with out web gateways and ideally with no egress. Ingress from the web also needs to be blocked to reduce safety dangers.
On this publish, we use LiteLLM Python SDK to standardize and summary entry to Amazon SageMaker real-time endpoints and LLMPerf instrument for analysis of efficiency of our quantized fashions. See Set up within the LLMPerf GitHub repo for setup directions.
Weights and activation methods (WₓAᵧ)
As the dimensions of LLMs continues to develop, deploying them effectively turns into much less about uncooked efficiency and extra about discovering the precise steadiness between pace, value, and accuracy. In real-world eventualities, quantization begins with three core concerns:
- The scale of the mannequin you must host
- The associated fee or goal {hardware} accessible for inference
- The suitable trade-off between accuracy and inference pace
Understanding how these components form quantization decisions is essential to creating LLMs viable in manufacturing environments. We’ll discover how post-training quantization methods like AWQ and generative pre-trained transformers quantization (GPTQ) assist navigate these constraints and make state-of-the-art fashions deployable at scale.
Weights and activation: A deep dive
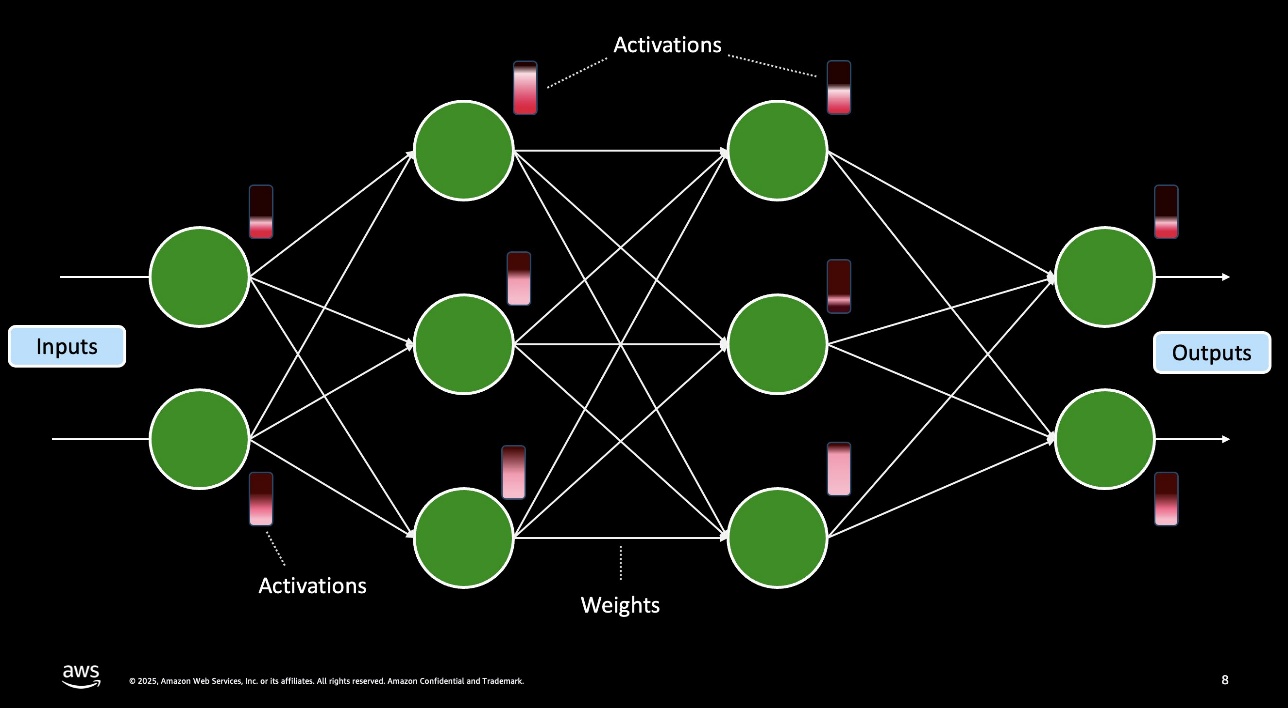
In neural networks, weights are the static, realized parameters saved within the mannequin—consider them because the mounted coefficients that form how inputs are mixed—whereas activations are the dynamic values produced at every layer while you run knowledge by the community, representing the response of every neuron to its inputs. The previous determine illustrates weights and activations in a mannequin circulate. We seize their respective precisions with the shorthand WₓAᵧ, the place Wₓ is the bit-width for weights (for instance, 4-bit or 8-bit) and Aᵧ is the bit-width for activations (for instance, 8-bit or 16-bit). For instance, W4A16 means weights are saved as 4-bit integers (usually with per-channel, symmetric or uneven scaling) whereas activations stay in 16-bit floating level. This notation tells you which ones components of the mannequin are compressed and by how a lot, serving to you steadiness reminiscence use, compute pace, and accuracy.
W4A16 (or W4A16_symmetric)
W4A16 refers to 4-bit precision for weights and 16-bit for activations, utilizing a symmetric quantization for weights. Symmetric quantization means the quantizer’s vary is centered round zero (absolutely the minimal and most of the burden distribution are set to be equal in magnitude). Utilizing 4-bit integer weights yields an 8-times discount in weight reminiscence in comparison with FP32 (or 4 instances in comparison with FP16), which could be very engaging for deployment. Nonetheless, with solely 16 quantization ranges (−8 to +7 for a 4-bit signed integer, in a symmetric scheme), the mannequin is susceptible to quantization error. If the burden distribution isn’t completely zero-centered (for instance, if weights have a slight bias or just a few massive outliers), a symmetric quantizer may waste vary on one facet and never have sufficient decision the place the majority of values lie. Research have discovered {that a} naive 4-bit symmetric quantization of LLM weights can incur a noticeable accuracy drop and is mostly inferior to utilizing an uneven scheme at this low bit-width. The symmetric W4A16 method is especially a baseline; with out further methods (like AWQ’s scaling or GPTQ’s error compensation), 4-bit weight quantization wants cautious dealing with to keep away from severe degradation.
W4A16_asymmetric
Utilizing 4-bit weights with an uneven quantization improves upon the symmetric case by introducing a zero-point offset. Uneven quantization maps the minimal weight to the bottom representable integer and the utmost weight to the very best integer, relatively than forcing the vary to be symmetric round zero. This enables the small 4-bit scale to cowl the precise vary of weight values extra successfully. In follow, 4-bit weight quantization with uneven scaling considerably outperforms the symmetric method when it comes to mannequin accuracy. By higher using all 16 ranges of the quantizer (particularly when the burden distribution has a non-zero imply or outstanding outliers on one facet), the uneven W4A16 scheme can scale back the quantization error. Trendy PTQ strategies for 4-bit LLMs nearly at all times incorporate some type of uneven or per-channel scaling because of this. For instance, one method is group-wise quantization the place every group of weights (for instance, every output channel) will get its personal min-max vary—successfully an uneven quantization per group—which has been recognized as a sweet-spot when mixed with 4-bit weights. W4A16 with uneven quantization is the popular technique for pushing weights to ultra-low precision, as a result of it yields higher perplexity and accuracy retention than a symmetric 4-bit mapping.
W8A8
This denotes absolutely quantizing each weights and activations to 8-bit integers. INT8 quantization is a well-understood, broadly adopted PTQ method that often incurs minimal accuracy loss in lots of networks, as a result of 256 distinct ranges (per quantization vary) are often adequate to seize the wanted precision. For LLMs, weight quantization to 8-bit is comparatively easy—research has shown that replacing 16-bit weights with INT8 usually causes negligible change in perplexity. Activation quantization to 8-bit, nonetheless, is more difficult for transformers due to the presence of outliers—occasional very massive activation values in sure layers. These outliers can power a quantizer to have an especially massive vary, making most values use solely a tiny fraction of the 8-bit ranges (leading to precision loss). To handle this, methods like SmoothQuant redistribute a few of the quantization problem from activations to weights—primarily cutting down outlier activation channels and scaling up the corresponding weight channels (a mathematically equal transformation) in order that activations have a tighter vary that matches effectively in 8 bits. With such calibrations, LLMs will be quantized to W8A8 with little or no efficiency drop. The good thing about W8A8 is that it permits end-to-end integer inference—each weights and activations are integers—which present {hardware} can exploit for quicker matrix multiplication. Absolutely INT8 fashions usually run quicker than blended precision fashions, as a result of they’ll use optimized INT8 arithmetic all through.
W8A16
W8A16 makes use of 8-bit quantization for weights whereas conserving activations in 16-bit precision (usually FP16). It may be seen as a weight-only quantization state of affairs. The reminiscence financial savings from compressing weights to INT8 are important (a 2 instances discount in comparison with FP16, and 4 instances in comparison with FP32) and, as famous, INT8 weights often don’t harm accuracy in LLMs. As a result of activations stay in excessive precision, the mannequin’s computation outcomes are almost as correct as the unique—the primary supply of error is the minor quantization noise in weights. Weight-only INT8 quantization is thus a really secure selection that yields substantial reminiscence discount with nearly no mannequin high quality loss.
Many sensible deployments begin with weight-only INT8 PTQ as a baseline. This method is particularly helpful while you need to scale back mannequin measurement to suit on a tool inside a given reminiscence price range with out doing advanced calibration for activations. When it comes to pace, utilizing INT8 weights reduces reminiscence bandwidth necessities (benefiting memory-bound inference eventualities) and may barely enhance throughput, nonetheless the activations are nonetheless 16-bit, and the compute models may not be absolutely using integer math for accumulation. If the {hardware} converts INT8 weights to 16-bit on the fly to multiply by FP16 activations, the pace achieve could be restricted by that conversion. For memory-bound workloads (frequent with LLMs at small batch sizes), INT8 weights present a noticeable speed-up as a result of the bottleneck is commonly fetching weights from reminiscence. For compute-bound eventualities (corresponding to very massive batch throughput), weight-only quantization alone yields much less profit—in these instances, you could possibly quantize activations (shifting to W8A8) to make use of quick INT8×INT8 matrix multiplication absolutely. In abstract, W8A16 is simple to implement quantization scheme that dramatically cuts mannequin measurement with minimal threat, whereas W8A8 is the subsequent step to maximise inference pace at the price of a extra concerned calibration course of.
Abstract
The next desk gives a high-level overview of the WₓAᵧ paradigm.
| Method | Weight format | Activation format | Main goal and real-world use case |
| W4A16 symmetric | 4-bit signed integers (per-tensor, zero-centered) | FP16 |
Baseline analysis and prototyping. Fast approach to take a look at ultra-low weight precision; helps gauge if 4-bit quantization is possible earlier than shifting to extra optimized schemes. |
| W4A16 uneven | 4-bit signed integers (per-channel minimal and most) | FP16 |
Reminiscence-constrained inference. Perfect when you need to squeeze a big mannequin into very tight gadget reminiscence whereas tolerating minor calibration overhead. |
| W8A8 | 8-bit signed integers (per-tensor or per-channel) | INT8 | Excessive-throughput, latency-sensitive deployment. Makes use of full INT8 pipelines on fashionable GPUs and CPUs or NPUs for optimum pace in batch or real-time inference. |
| W8A16 | 8-bit signed integers (per-tensor) | FP16 |
Simple weight-only compression. Cuts mannequin measurement in half with negligible accuracy loss; nice first step on GPUs or servers while you prioritize reminiscence financial savings over peak compute pace. |
Inference acceleration by PTQ methods
As outlined earlier, LLMs with excessive parameter counts are extraordinarily resource-intensive at inference. Within the following sections, we discover how PTQ reduces these necessities, enabling cheaper and performant inference. As an illustration, a Llama 3 70B parameter mannequin at FP16 precision doesn’t match right into a single A100 80 GB GPU and requires no less than two A100 80 GB GPUs for affordable inference at scale, making deployment each pricey and impractical for a lot of use instances. To handle this problem, PTQ converts a educated mannequin’s weights (and typically activations) from high-precision floats (for instance, 16- or 32-bit) to lower-bit integers (for instance, 8-bit or 4-bit) after coaching. This compression can shrink mannequin measurement by 2–8 instances, enabling the mannequin to slot in reminiscence and lowering reminiscence bandwidth calls for, which in flip can pace up inference.
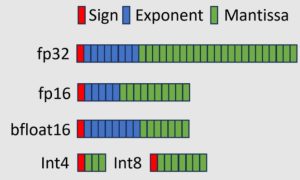
Crucially, PTQ requires no further coaching—in contrast to quantization-aware coaching (QAT), which includes quantization into the fine-tuning course of. PTQ avoids the prohibitive retraining value related to billion-parameter fashions. The problem is to quantize the mannequin rigorously to reduce any drop in accuracy or enhance in perplexity. Trendy PTQ methods attempt to retain mannequin efficiency whereas dramatically bettering deployment effectivity.
Put up-training quantization algorithms
Quantizing a complete mannequin on to 4-bit or 8-bit precision may appear easy, however doing so naïvely usually ends in substantial accuracy degradation—significantly underneath lower-bit configurations. To beat this, specialised PTQ algorithms have been developed that intelligently compress mannequin parameters whereas preserving constancy. On this publish, we concentrate on two broadly adopted and well-researched PTQ methods, every taking a definite method to high-accuracy compression:
- Activation-aware weights quantization (AWQ)
- Generative pre-trained transformers quantization (GPTQ)
Activation conscious weights quantization
AWQ is a PTQ method that targets weight-only quantization at very low bit widths (usually 4-bit) whereas conserving activations in increased precision, corresponding to FP16. The core idea is that not all weights contribute equally to a mannequin’s output; a small subset of salient weights disproportionately influences predictions. By figuring out and preserving roughly 1% of those vital weight channels—these related to the most important activation values—AWQ can dramatically shut the hole between 4-bit quantized fashions and their authentic FP16 counterparts when it comes to perplexity. In contrast to conventional strategies that rank significance primarily based on weight magnitude alone, AWQ makes use of activation distributions to search out which weights really matter. Early outcomes confirmed that leaving the highest 1% of channels in increased precision was sufficient to keep up efficiency—however this introduces {hardware} inefficiencies resulting from mixed-precision execution. To get round this, AWQ introduces a chic workaround of per-channel scaling.
Throughout quantization, AWQ amplifies the weights of activation-salient channels to scale back relative quantization error and folds the inverse scaling into the mannequin, so no specific rescaling is required throughout inference. This adjustment eliminates the overhead of mixed-precision computation whereas conserving inference purely low-bit. Importantly, AWQ achieves this with out retraining—it makes use of a small calibration dataset to estimate activation statistics and derive scaling components analytically. The strategy avoids overfitting to calibration knowledge, making certain robust generalization throughout duties. In follow, AWQ delivers near-FP16 efficiency even at 4-bit precision, displaying far smaller degradation than conventional post-training strategies like RTN (round-to-nearest). Whereas there’s nonetheless a marginal enhance in perplexity in comparison with full-precision fashions, the trade-off is commonly negligible given the three–4 instances discount in reminiscence footprint and bandwidth. This effectivity permits deployment of very massive fashions—as much as 70 billion parameters—on a single high-end GPU corresponding to an A100 or H100. Briefly, AWQ demonstrates that with cautious, activation-aware scaling, precision will be centered the place it issues most, attaining low-bit quantization with minimal influence on mannequin high quality.
Generative pre-trained transformers quantization (GPTQ)
GPTQ is one other PTQ technique that takes an error-compensation-driven method to compressing massive language fashions. GPTQ operates layer by layer, aiming to protect every layer’s output as carefully as potential to that of the unique full-precision mannequin. It follows a grasping, sequential quantization technique: at every step, a single weight or a small group of weights is quantized, whereas the remaining unquantized weights are adjusted to compensate for the error launched. This retains the output of every layer tightly aligned with the unique. The method is knowledgeable by approximate second-order statistics, particularly an approximation of the Hessian matrix, which estimates how delicate the output is to adjustments in every weight. This optimization process is usually known as optimum mind quantization, the place GPTQ rigorously quantizes weights in an order that minimizes cumulative output error.
Regardless of its sophistication, GPTQ stays a one-shot PTQ technique—it doesn’t require retraining or iterative fine-tuning. It makes use of a small calibration dataset to run ahead passes, amassing activation statistics and estimating Hessians, however avoids any weight updates past the grasping compensation logic. The result’s an impressively environment friendly compression method: GPTQ can quantize fashions to three–4 bits per weight with minimal accuracy loss, even for large fashions. For instance, the strategy demonstrated compressing a 175 billion-parameter GPT mannequin to three–4 bits in underneath 4 GPU-hours, with negligible enhance in perplexity, enabling single-GPU inference for the primary time at this scale. Whereas GPTQ delivers excessive accuracy, its reliance on calibration knowledge has led some researchers to notice gentle overfitting results, particularly for out-of-distribution inputs. Nonetheless, GPTQ has turn out to be a go-to baseline in LLM quantization due to its robust steadiness of constancy and effectivity, aided by mathematical optimizations corresponding to quick Cholesky-based Hessian updates that make it sensible even for fashions with tens or a whole lot of billions of parameters.
Utilizing Amazon SageMaker AI for inference optimization and mannequin quantization
On this part, we cowl the best way to implement quantization utilizing Amazon SageMaker AI. We stroll by a codebase that you should use to rapidly quantize a mannequin utilizing both the GPTQ or AWQ technique on SageMaker coaching jobs backed by a number of GPU situations. The code makes use of the open supply vllm-project/llm-compressor bundle to quantize dense LLM weights from FP32 to INT4.
All code for this course of is out there within the amazon-sagemaker-generativeai GitHub repository. The llm-compressor venture gives a streamlined library for mannequin optimization. It helps a number of algorithms—GPTQ, AWQ, and SmoothQuant—for changing full- or half-precision fashions into lower-precision codecs. Quantization takes place in three steps, described within the following sections. The complete implementation is out there in post_training_sagemaker_quantizer.py, with arguments supplied for easy execution.
Step 1: Load mannequin utilizing HuggingFace transformers
Load the mannequin weights with out attaching them to an accelerator. The llm-compressor library robotically detects accessible {hardware} and offloads weights to the accelerator as wanted. As a result of it performs quantization layer by layer, your entire mannequin doesn’t want to slot in accelerator reminiscence without delay.
Step 2: Choose and cargo the calibration dataset
A calibration dataset is used throughout PTQ to estimate activation ranges and statistical distributions in a pretrained LLM with out retraining. Instruments like llm-compressor use this small, consultant dataset to run ahead passes and acquire statistics corresponding to minimal and most values or percentiles. These statistics information the quantization of weights and activations to scale back precision whereas preserving mannequin accuracy. You should utilize any tokenized dataset that displays the mannequin’s anticipated enter distribution for calibration.
Step 3: Run PTQ on the candidate mannequin
The oneshot technique in llm-compressor performs a single-pass (no iterative retraining) PTQ utilizing a specified recipe, making use of each weight and activation quantization (and optionally sparsity) in a single cross.
num_calibration_samplesdefines what number of enter sequences (for instance, 512) are used to simulate mannequin conduct, gathering the activation statistics essential for calibrating quantization ranges.max_seq_lengthunits the utmost token size (for instance, 2048) for these calibration samples, so activations mirror the worst-case sequence context, making certain quantization stays correct throughout enter lengths.
Collectively, these hyperparameters management the representativeness and protection of calibration, straight impacting quantization constancy.
The modifier courses (GPTQModifier, AWQModifier) settle for a schema parameter that defines the bit-width for each weights and activations. By means of this parameter, you possibly can specify codecs corresponding to W8A8 (8-bit weights and activations) or W4A16 (4-bit weights with 16-bit activations), providing you with fine-grained management over precision trade-offs throughout mannequin layers.
Structure sample for quantization on Amazon SageMaker AI
All the workflow, proven within the following determine, is carried out within the post_training_sagemaker_quantizer.py script and will be executed as a SageMaker coaching job on an occasion with NVIDIA GPU assist (corresponding to ml.g5.2xlarge) for accelerated quantization.
This course of doesn’t contain coaching or fine-tuning the mannequin. The coaching job is used solely to run PTQ with GPU acceleration.
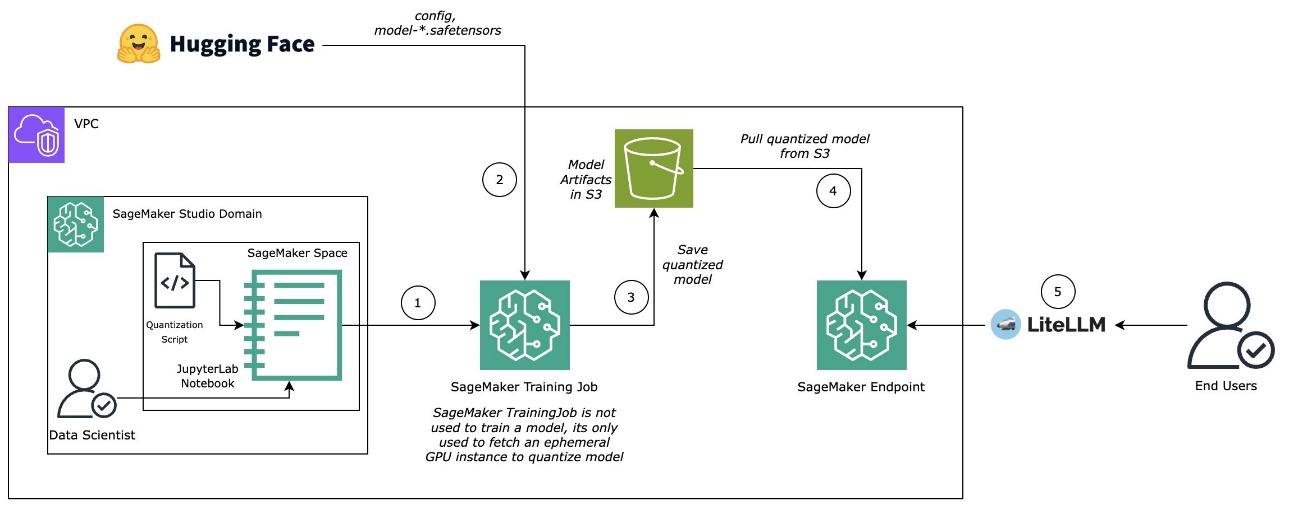
After a mannequin is quantized, it is going to be saved to Amazon Easy Storage Service (Amazon S3) straight as an output from the SageMaker coaching job. We’ll uncompress the mannequin and host it as a SageMaker real-time endpoint utilizing a Amazon SageMaker AI massive mannequin inference (LMI) container, powered by vLLM. To search out the newest photos, see AWS Deep Learning Framework Support Policy for LMI containers (see SageMaker section).
You now have a SageMaker real-time endpoint serving your quantized mannequin and prepared for inference. You possibly can question it utilizing the SageMaker Python SDK or litellm, relying in your integration wants.
Mannequin efficiency
We are going to use an ml.g5.2xlarge occasion for Llama-3.1-8B and Qwen-2.5-VL-7B fashions and ml.p4d.24xlarge occasion for Llama-3.1-70B mannequin and an LMI container v15 with vLLM backend as a serving framework.
The next is a code snippet from the deployment configuration:
This efficiency analysis’s main aim is to point out the relative efficiency of mannequin variations on totally different {hardware}. The mixtures aren’t absolutely optimized and shouldn’t be seen as peak mannequin efficiency on an occasion kind. At all times make certain to check utilizing your knowledge, site visitors, and I/O sequence size. The next is efficiency benchmark script:
Efficiency metrics
To know the influence of PTQ optimization methods, we concentrate on 5 key inference efficiency metrics—every providing a unique lens on system effectivity and person expertise:
- GPU reminiscence utilization: Signifies the proportion of complete GPU reminiscence actively used throughout inference. Greater reminiscence utilization suggests extra of the mannequin or enter knowledge is loaded into GPU reminiscence, which might enhance throughput—however extreme utilization may result in reminiscence bottlenecks or out-of-memory errors.
- Finish-to-end latency: Measures the whole time taken from enter submission to last output. That is vital for purposes the place responsiveness is essential, corresponding to real-time programs or user-facing interfaces.
- Time to first token (TTFT): Captures the delay between enter submission and the technology of the primary token. Decrease TTFT is particularly necessary for streaming or interactive workloads, the place perceived responsiveness issues greater than complete latency.
- Inter-token latency (ITL): Tracks the common time between successive token outputs. A decrease ITL ends in smoother, faster-seeming responses, significantly in long-form textual content technology.
- Throughput: Measures the variety of tokens generated per second throughout all concurrent requests. Greater throughput signifies higher system effectivity and scalability, enabling quicker processing of huge workloads or extra simultaneous person periods.
Collectively, these metrics present a holistic view of inference conduct—balancing uncooked effectivity with real-world usability. Within the subsequent sections of this publish, we consider three candidate fashions—every various in measurement and structure—to validate inference efficiency metrics after quantization utilizing AWQ and GPTQ algorithms throughout totally different WₓAᵧ methods. The chosen fashions embrace:
- Llama-3.1-8B-Instruct: An 8-billion parameter dense decoder-only transformer mannequin optimized for instruction following. Revealed by Meta, it belongs to the LLaMA (Massive Language Mannequin Meta AI) household and is well-suited for general-purpose pure language processing (NLP) duties.
- Llama-3.3-70B-Instruct: A 70-billion parameter mannequin additionally from Meta’s LLaMA collection, this bigger variant presents considerably improved reasoning and factual grounding capabilities, making it best for high-performance enterprise use instances.
- Qwen2.5-VL-7B-Instruct: A 7-billion parameter vision-language mannequin developed by Alibaba’s Institute for Clever Computing. It helps each textual content and picture inputs, combining a transformer-based textual content spine with a visible encoder, making it appropriate for multimodal purposes.
Be aware that every mannequin was examined on a unique occasion kind: Llama-3.1-8B on ml.g5.2xlarge, Llama-3.3-70B on ml.p4dn.24xlarge, and Qwen2.5-VL-7B on ml.g6e.4xlarge.
GPU reminiscence utilization
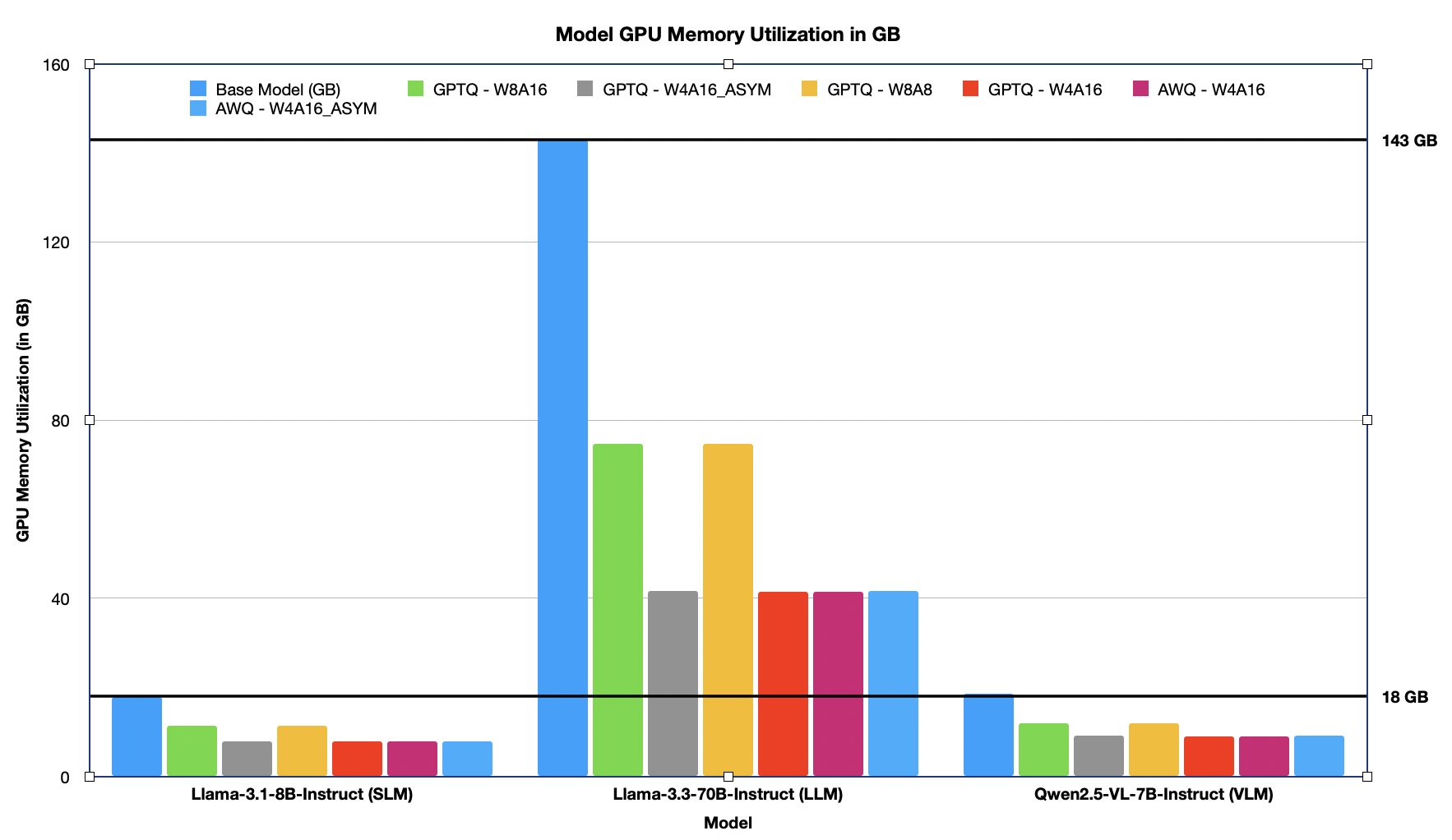
GPU reminiscence utilization displays how a lot gadget reminiscence is consumed throughout mannequin execution and straight impacts deployability, batch measurement, and {hardware} choice. Decrease reminiscence utilization permits working bigger fashions on smaller GPUs or serving extra concurrent requests on the identical {hardware}. Quantization improves compute effectivity and considerably reduces the reminiscence footprint of LLMs. By changing high-precision weights (for instance, FP16 or FP32) into lower-bit codecs corresponding to INT8 or FP8, each AWQ and GPTQ methods allow fashions to eat considerably much less GPU reminiscence throughout inference. That is vital for deploying massive fashions on memory-constrained {hardware} or rising batch sizes for increased throughput. Within the following desk and chart, we listing and visualize the GPU reminiscence utilization (in GB) throughout the fashions underneath a number of quantization configurations. The proportion discount is in contrast in opposition to the bottom (unquantized) mannequin measurement, highlighting the reminiscence financial savings achieved with every WₓAᵧ technique, which ranges from ~30%–70% much less GPU reminiscence utilization after PTQ.
| Mannequin title | Uncooked (GB) | AWQ | GPTQ | ||||
| W4A16_ASYM | W4A16 | W4A16 | W8A8 | W4A16_ASYM | W8A16 | ||
| (GB in reminiscence and % lower from uncooked) | |||||||
| Llama-3.1-8B-Instruct (SLM) | 17.9 | 7.9 GB – 56.02% | 7.8 GB – 56.13% | 7.8 GB – 56.13 % | 11.3 GB – 37.05% | 7.9 GB – 56.02% | 11.3 GB – 37.05% |
| Llama-3.3-70B-Instruct (LLM) | 142.9 | 41.7 GB – 70.82% | 41.4 GB – 71.03% | 41.4 GB – 71.03 % | 74.7 GB – 47.76% | 41.7 GB – 70.82% | 74.7 GB – 47.76% |
| Qwen2.5-VL-7B-Instruct (VLM) | 18.5 | 9.1 GB – 50.94% | 9.0 GB – 51.26% | 9.0 GB – 51.26% | 12.0 GB – 34.98% | 9.1 GB – 50.94% | 12.0 GB – 34.98% |
The determine beneath illustrates the GPU reminiscence footprint (in GB) of the mannequin in its uncooked (unquantized) type in comparison with its quantized variants. Quantization ends in ~30%–70% discount in GPU reminiscence consumption, considerably reducing the general reminiscence footprint.
Finish-to-end latency
Finish-to-end latency measures the whole time taken from the second a immediate is obtained to the supply of the ultimate output token. It’s a vital metric for evaluating user-perceived responsiveness and general system efficiency, particularly in real-time or interactive purposes.
Within the following desk, we report end-to-end latency in seconds throughout various concurrency ranges (C=1 to C=128) for three fashions of various measurement and modality (Llama-3.1-8B, Llama-3.3-70B, and Qwen2.5-VL-7B) underneath totally different quantization methods.
| Mannequin title | C=1 | C=8 | C=16 | C=32 | C=64 | C=128 |
| Llama-3.1-8B | 8.65 | 10.68 | 12.19 | 14.76 | 28.31 | 56.67 |
| Llama-3.1-8B-AWQ-W4A16_ASYM | 3.33 | 4.67 | 5.41 | 8.1 | 18.29 | 35.83 |
| Llama-3.1-8B-AWQ-W4A16 | 3.34 | 4.67 | 5.37 | 8.02 | 18.05 | 35.32 |
| Llama-3.1-8B-GPTQ-W4A16 | 3.53 | 4.65 | 5.35 | 8 | 18.07 | 35.35 |
| Llama-3.1-8B-GPTQ-W4A16_ASYM | 3.36 | 4.69 | 5.41 | 8.09 | 18.28 | 35.69 |
| Llama-3.1-8B-GPTQ-W8A8 | 5.47 | 6.65 | 7.37 | 10.17 | 19.73 | 38.83 |
| Llama-3.1-8B-GPTQ-W8A16 | 5.03 | 6.36 | 7.15 | 10.88 | 20.83 | 40.76 |
| Llama-3.3-70B | 4.56 | 5.59 | 6.22 | 7.26 | 13.94 | 27.67 |
| Llama-3.3-70B-AWQ-W4A16_ASYM | 3.95 | 4.13 | 4.44 | 5.44 | 10.79 | 20.85 |
| Llama-3.3-70B-AWQ-W4A16 | 3.76 | 3.47 | 4.05 | 4.83 | 9.84 | 19.23 |
| Llama-3.3-70B-GPTQ-W4A16 | 3.51 | 3.43 | 4.09 | 5.72 | 10.69 | 21.59 |
| Llama-3.3-70B-GPTQ-W4A16_ASYM | 3.6 | 4.12 | 4.51 | 5.71 | 11.36 | 21.8 |
| Llama-3.3-70B-GPTQ-W8A8 | 3.85 | 4.31 | 4.88 | 5.61 | 10.95 | 21.29 |
| Llama-3.3-70B-GPTQ-W8A16 | 4.31 | 4.48 | 4.61 | 5.8 | 11.11 | 21.86 |
| Qwen2.5-VL-7B-Instruct (VLM) | 5.28 | 5.89 | 6.12 | 7.56 | 8.77 | 13.17 |
| Qwen2.5-VL-7B-AWQ-W4A16_ASYM | 2.14 | 2.56 | 2.77 | 3.39 | 5.13 | 9.22 |
| Qwen2.5-VL-7B-AWQ-W4A16 | 2.12 | 2.56 | 2.71 | 3.48 | 4.9 | 8.94 |
| Qwen2.5-VL-7B-GPTQ-W4A16 | 2.13 | 2.54 | 2.75 | 3.59 | 5.11 | 9.66 |
| Qwen2.5-VL-7B-GPTQ-W4A16_ASYM | 2.14 | 2.56 | 2.83 | 3.52 | 5.09 | 9.51 |
| Qwen2.5-VL-7B-GPTQ-W8A8 | 3.62 | 4.02 | 4.19 | 4.75 | 5.91 | 9.71 |
| Qwen2.5-VL-7B-GPTQ-W8A16 | 3.38 | 3.85 | 4.04 | 4.7 | 6.12 | 10.93 |
The next graphs displaying finish to finish latency for various concurrency ranges for various fashions.
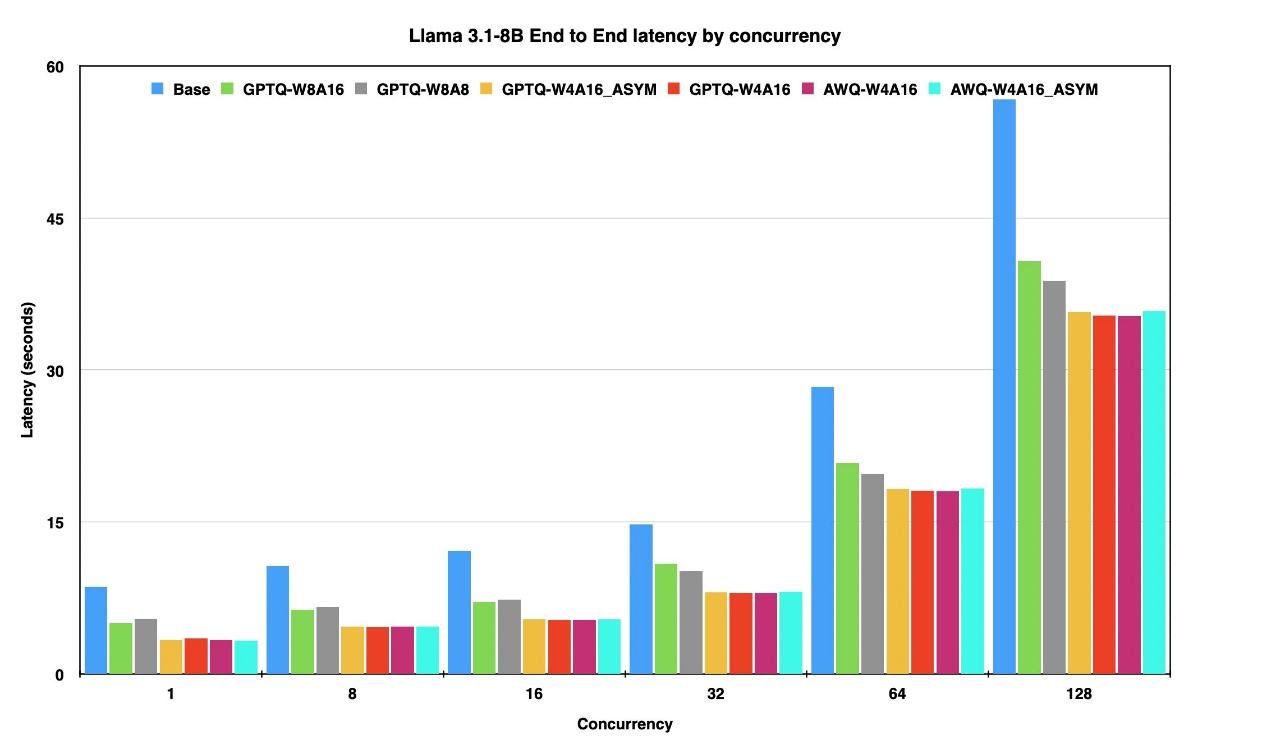
The determine above presents the end-to-end latency of the Llama 3-8B mannequin in its uncooked (unquantized) type and its quantized variants throughout concurrency ranges starting from 1 to 128 on the identical occasion.
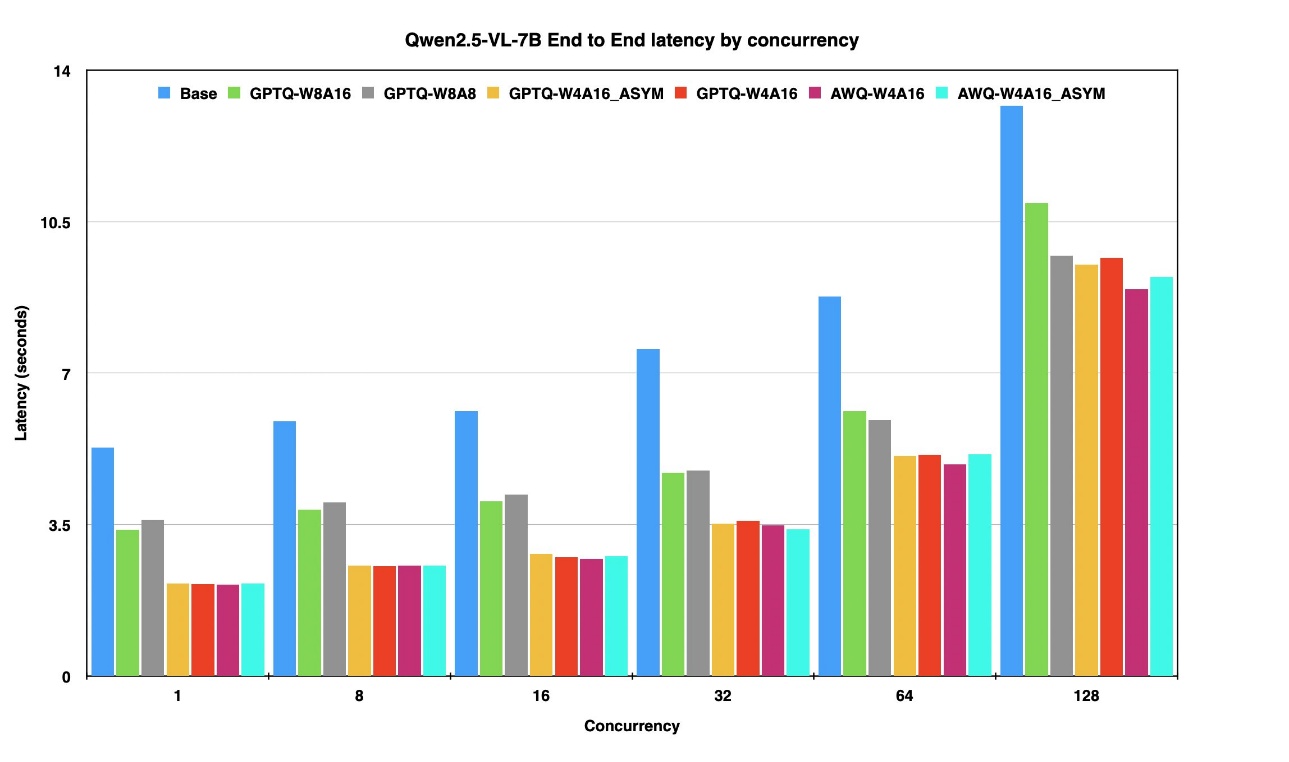
The determine above presents the end-to-end latency of the Qwen 2.7-7B mannequin in its uncooked (unquantized) type and its quantized variants throughout concurrency ranges starting from 1 to 128 on the identical occasion.
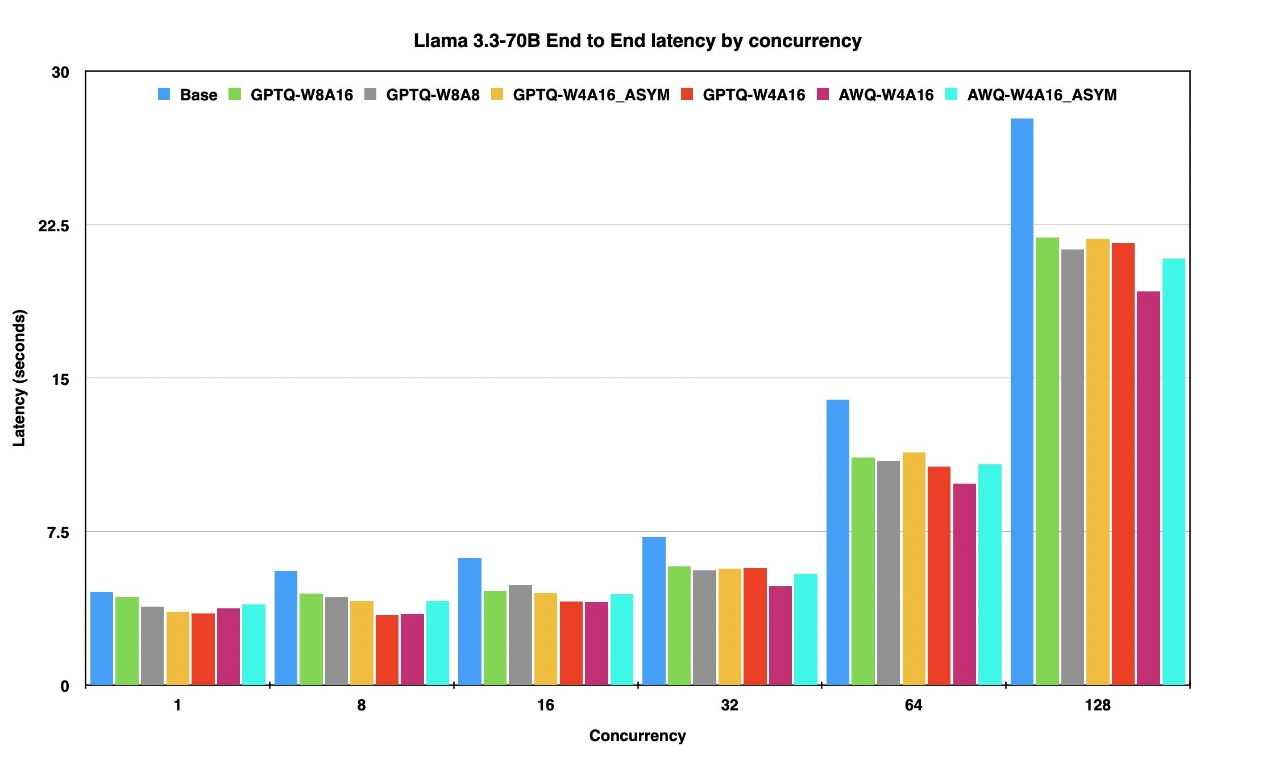
The determine above presents the end-to-end latency of the Llama 3-70B mannequin in its uncooked (unquantized) type and its quantized variants throughout concurrency ranges starting from 1 to 128 on the identical occasion.
Time to first token
TTFT measures the delay between immediate submission and the technology of the primary token. This metric performs an important function in shaping perceived responsiveness—particularly in chat-based, streaming, or interactive purposes the place preliminary suggestions time is vital. Within the following desk, we examine TTFT in seconds for 3 fashions of various measurement and modality—Llama-3.1-8B, Llama-3.3-70B, and Qwen2.5-VL-7B—underneath totally different quantization methods. As concurrency will increase (from C=1 to C=128), the outcomes spotlight how quantization methods like AWQ and GPTQ assist keep low startup latency, making certain a smoother and quicker expertise even underneath excessive load.
| Mannequin title | C=1 | C=8 | C=16 | C=32 | C=64 | C=128 |
| Llama-3.1-8B | 0.27 | 1.44 | 6.51 | 11.37 | 24.96 | 53.38 |
| Llama-3.1-8B-AWQ-W4A16_ASYM | 0.17 | 0.62 | 3 | 6.21 | 16.17 | 33.74 |
| Llama-3.1-8B-AWQ-W4A16 | 0.18 | 0.62 | 2.99 | 6.15 | 15.96 | 33.26 |
| Llama-3.1-8B-GPTQ-W4A16 | 0.37 | 0.63 | 2.94 | 6.14 | 15.97 | 33.29 |
| Llama-3.1-8B-GPTQ-W4A16_ASYM | 0.19 | 0.63 | 3 | 6.21 | 16.16 | 33.6 |
| Llama-3.1-8B-GPTQ-W8A8 | 0.17 | 0.86 | 4.09 | 7.86 | 17.44 | 36.57 |
| Llama-3.1-8B-GPTQ-W8A16 | 0.21 | 0.9 | 3.97 | 8.42 | 18.44 | 38.39 |
| Llama-3.3-70B | 0.16 | 0.19 | 0.19 | 0.21 | 6.87 | 20.52 |
| Llama-3.3-70B-AWQ-W4A16_ASYM | 0.17 | 0.18 | 0.16 | 0.21 | 5.34 | 15.46 |
| Llama-3.3-70B-AWQ-W4A16 | 0.15 | 0.17 | 0.16 | 0.2 | 4.88 | 14.28 |
| Llama-3.3-70B-GPTQ-W4A16 | 0.15 | 0.17 | 0.15 | 0.2 | 5.28 | 16.01 |
| Llama-3.3-70B-GPTQ-W4A16_ASYM | 0.16 | 0.17 | 0.17 | 0.2 | 5.61 | 16.17 |
| Llama-3.3-70B-GPTQ-W8A8 | 0.14 | 0.15 | 0.15 | 0.18 | 5.37 | 15.8 |
| Llama-3.3-70B-GPTQ-W8A16 | 0.1 | 0.17 | 0.15 | 0.19 | 5.47 | 16.22 |
| Qwen2.5-VL-7B-Instruct (VLM) | 0.042 | 0.056 | 0.058 | 0.081 | 0.074 | 0.122 |
| Qwen2.5-VL-7B-AWQ-W4A16_ASYM | 0.03 | 0.046 | 0.038 | 0.042 | 0.053 | 0.08 |
| Qwen2.5-VL-7B-AWQ-W4A16 | 0.037 | 0.046 | 0.037 | 0.043 | 0.052 | 0.08 |
| Qwen2.5-VL-7B-GPTQ-W4A16 | 0.037 | 0.047 | 0.036 | 0.043 | 0.053 | 0.08 |
| Qwen2.5-VL-7B-GPTQ-W4A16_ASYM | 0.038 | 0.048 | 0.038 | 0.042 | 0.053 | 0.082 |
| Qwen2.5-VL-7B-GPTQ-W8A8 | 0.035 | 0.041 | 0.042 | 0.046 | 0.055 | 0.081 |
| Qwen2.5-VL-7B-GPTQ-W8A16 | 0.042 | 0.048 | 0.046 | 0.052 | 0.062 | 0.093 |
Inter-token latency
ITL measures the common time delay between the technology of successive tokens. It straight impacts the smoothness and pace of streamed outputs—significantly necessary in purposes involving long-form textual content technology or voice synthesis, the place delays between phrases or sentences can degrade person expertise. Within the following desk, we analyze ITL in seconds throughout three fashions of various measurement and modality—Llama-3.1-8B, Llama-3.3-70B, and Qwen2.5-VL-7B—underneath totally different quantization schemes. As concurrency scales up, the outcomes illustrate how quantization methods like AWQ and GPTQ assist keep low per-token latency, making certain fluid technology even underneath excessive parallel hundreds.
| Mannequin title | C=1 | C=8 | C=16 | C=32 | C=64 | C=128 |
| Llama-3.1-8B | 0.035 | 0.041 | 0.047 | 0.057 | 0.111 | 0.223 |
| Llama-3.1-8B-AWQ-W4A16_ASYM | 0.013 | 0.018 | 0.021 | 0.031 | 0.072 | 0.141 |
| Llama-3.1-8B-AWQ-W4A16 | 0.013 | 0.018 | 0.02 | 0.031 | 0.071 | 0.139 |
| Llama-3.1-8B-GPTQ-W4A16 | 0.014 | 0.018 | 0.02 | 0.031 | 0.071 | 0.139 |
| Llama-3.1-8B-GPTQ-W4A16_ASYM | 0.013 | 0.018 | 0.021 | 0.031 | 0.072 | 0.14 |
| Llama-3.1-8B-GPTQ-W8A8 | 0.02 | 0.026 | 0.028 | 0.039 | 0.077 | 0.153 |
| Llama-3.1-8B-GPTQ-W8A16 | 0.02 | 0.024 | 0.027 | 0.042 | 0.081 | 0.16 |
| Llama-3.3-70B | 0.019 | 0.024 | 0.025 | 0.03 | 0.065 | 0.12 |
| Llama-3.3-70B-AWQ-W4A16_ASYM | 0.018 | 0.021 | 0.021 | 0.029 | 0.076 | 0.163 |
| Llama-3.3-70B-AWQ-W4A16 | 0.017 | 0.021 | 0.022 | 0.029 | 0.081 | 0.201 |
| Llama-3.3-70B-GPTQ-W4A16 | 0.014 | 0.018 | 0.019 | 0.028 | 0.068 | 0.152 |
| Llama-3.3-70B-GPTQ-W4A16_ASYM | 0.017 | 0.02 | 0.021 | 0.028 | 0.067 | 0.159 |
| Llama-3.3-70B-GPTQ-W8A8 | 0.016 | 0.02 | 0.022 | 0.026 | 0.058 | 0.131 |
| Llama-3.3-70B-GPTQ-W8A16 | 0.017 | 0.02 | 0.021 | 0.025 | 0.056 | 0.122 |
| Qwen2.5-VL-7B-Instruct (VLM) | 0.021 | 0.023 | 0.023 | 0.029 | 0.034 | 0.051 |
| Qwen2.5-VL-7B-AWQ-W4A16_ASYM | 0.008 | 0.01 | 0.01 | 0.013 | 0.02 | 0.038 |
| Qwen2.5-VL-7B-AWQ-W4A16 | 0.008 | 0.01 | 0.01 | 0.014 | 0.02 | 0.038 |
| Qwen2.5-VL-7B-GPTQ-W4A16 | 0.008 | 0.01 | 0.01 | 0.013 | 0.02 | 0.038 |
| Qwen2.5-VL-7B-GPTQ-W4A16_ASYM | 0.008 | 0.01 | 0.011 | 0.014 | 0.02 | 0.038 |
| Qwen2.5-VL-7B-GPTQ-W8A8 | 0.014 | 0.015 | 0.016 | 0.018 | 0.023 | 0.039 |
| Qwen2.5-VL-7B-GPTQ-W8A16 | 0.013 | 0.015 | 0.015 | 0.018 | 0.024 | 0.044 |
Throughput
Throughput measures the variety of tokens generated per second and is a key indicator of how effectively a mannequin can scale underneath load. Greater throughput straight permits quicker batch processing and helps extra concurrent person periods. Within the following desk, we current throughput outcomes for Llama-3.1-8B, Llama-3.3-70B, and Qwen2.5-VL-7B throughout various concurrency ranges and quantization methods. Quantized fashions keep—and in lots of instances enhance—throughput, because of diminished reminiscence bandwidth and compute necessities. The substantial reminiscence financial savings from quantization permits a number of mannequin employees to be deployed on a single GPU, significantly on high-memory situations. This multi-worker setup additional amplifies complete system throughput at increased concurrency ranges, making quantization a extremely efficient technique for maximizing utilization in manufacturing environments.
| Mannequin title | C=1 | C=8 | C=16 | C=32 | C=64 | C=128 |
| Llama-3.1-8B | 33.09 | 27.41 | 24.37 | 20.05 | 10.71 | 5.53 |
| Llama-3.1-8B-AWQ-W4A16_ASYM | 85.03 | 62.14 | 55.25 | 37.27 | 16.44 | 9.06 |
| Llama-3.1-8B-AWQ-W4A16 | 83.21 | 61.86 | 55.31 | 37.69 | 16.59 | 9.19 |
| Llama-3.1-8B-GPTQ-W4A16 | 80.77 | 62.19 | 55.93 | 37.53 | 16.48 | 9.12 |
| Llama-3.1-8B-GPTQ-W4A16_ASYM | 81.85 | 61.75 | 54.74 | 37.32 | 16.4 | 9.13 |
| Llama-3.1-8B-GPTQ-W8A8 | 50.62 | 43.84 | 40.41 | 29.04 | 15.31 | 8.26 |
| Llama-3.1-8B-GPTQ-W8A16 | 55.24 | 46.47 | 41.79 | 27.21 | 14.6 | 7.94 |
| Llama-3.3-70B | 57.93 | 47.89 | 44.73 | 38 | 20.05 | 10.95 |
| Llama-3.3-70B-AWQ-W4A16_ASYM | 60.24 | 53.54 | 51.79 | 39.3 | 20.47 | 11.52 |
| Llama-3.3-70B-AWQ-W4A16 | 64 | 53.79 | 52.4 | 39.4 | 20.79 | 11.5 |
| Llama-3.3-70B-GPTQ-W4A16 | 78.07 | 61.68 | 58.18 | 41.07 | 21.21 | 11.77 |
| Llama-3.3-70B-GPTQ-W4A16_ASYM | 66.34 | 56.47 | 54.3 | 40.64 | 21.37 | 11.76 |
| Llama-3.3-70B-GPTQ-W8A8 | 66.79 | 55.67 | 51.73 | 44.63 | 23.7 | 12.85 |
| Llama-3.3-70B-GPTQ-W8A16 | 67.11 | 57.11 | 55.06 | 45.26 | 24.18 | 13.08 |
| Qwen2.5-VL-7B-Instruct (VLM) | 56.75 | 51.44 | 49.61 | 40.08 | 34.21 | 23.03 |
| Qwen2.5-VL-7B-AWQ-W4A16_ASYM | 140.89 | 117.47 | 107.49 | 86.33 | 58.56 | 30.25 |
| Qwen2.5-VL-7B-AWQ-W4A16 | 137.77 | 116.96 | 106.67 | 83.06 | 57.52 | 29.46 |
| Qwen2.5-VL-7B-GPTQ-W4A16 | 138.46 | 117.14 | 107.25 | 85.38 | 58.19 | 30.19 |
| Qwen2.5-VL-7B-GPTQ-W4A16_ASYM | 139.38 | 117.32 | 104.22 | 82.19 | 58 | 29.64 |
| Qwen2.5-VL-7B-GPTQ-W8A8 | 82.81 | 75.32 | 72.19 | 63.11 | 50.44 | 29.53 |
| Qwen2.5-VL-7B-GPTQ-W8A16 | 88.69 | 78.88 | 74.55 | 64.83 | 48.92 | 26.55 |
Conclusion
Put up-training quantization (PTQ) methods like AWQ and GPTQ have confirmed to be efficient options for deploying basis fashions in manufacturing environments. Our complete testing throughout totally different mannequin sizes and architectures demonstrates that PTQ considerably reduces GPU reminiscence utilization. The advantages are evident throughout all key metrics, with quantized fashions displaying higher throughput and diminished latency in inference time, together with high-concurrency eventualities. These enhancements translate to diminished infrastructure prices, improved person expertise by quicker response instances, and the pliability of deploying bigger fashions on resource-constrained {hardware}. As language fashions proceed to develop in scale and complexity, PTQ presents a dependable method for balancing efficiency necessities with infrastructure constraints, offering a transparent path to environment friendly, cost-effective AI deployment.
On this publish, we demonstrated the best way to streamline LLM quantization utilizing Amazon SageMaker AI and the llm-compressor module. The method of changing a full-precision mannequin to its quantized variant requires only a few easy steps, making it accessible and scalable for manufacturing deployments. By utilizing the managed infrastructure of Amazon SageMaker AI, organizations can seamlessly implement and serve quantized fashions for real-time inference, simplifying the journey from improvement to manufacturing. To discover these quantization methods additional, confer with our GitHub repository.
Particular because of everybody who contributed to this text: Giuseppe Zappia, Dan Ferguson, Frank McQuillan and Kareem Syed-Mohammed.
Concerning the authors
 Pranav Murthy is a Senior Generative AI Information Scientist at AWS, specializing in serving to organizations innovate with Generative AI, Deep Studying, and Machine Studying on Amazon SageMaker AI. Over the previous 10+ years, he has developed and scaled superior laptop imaginative and prescient (CV) and pure language processing (NLP) fashions to sort out high-impact issues—from optimizing international provide chains to enabling real-time video analytics and multilingual search. When he’s not constructing AI options, Pranav enjoys taking part in strategic video games like chess, touring to find new cultures, and mentoring aspiring AI practitioners. Yow will discover Pranav on LinkedIn
Pranav Murthy is a Senior Generative AI Information Scientist at AWS, specializing in serving to organizations innovate with Generative AI, Deep Studying, and Machine Studying on Amazon SageMaker AI. Over the previous 10+ years, he has developed and scaled superior laptop imaginative and prescient (CV) and pure language processing (NLP) fashions to sort out high-impact issues—from optimizing international provide chains to enabling real-time video analytics and multilingual search. When he’s not constructing AI options, Pranav enjoys taking part in strategic video games like chess, touring to find new cultures, and mentoring aspiring AI practitioners. Yow will discover Pranav on LinkedIn
 Dmitry Soldatkin is a Senior AI/ML Options Architect at Amazon Internet Providers (AWS), serving to prospects design and construct AI/ML options. Dmitry’s work covers a variety of ML use instances, with a main curiosity in Generative AI, deep studying, and scaling ML throughout the enterprise. He has helped corporations in lots of industries, together with insurance coverage, monetary providers, utilities, and telecommunications. You possibly can join with Dmitry on LinkedIn.
Dmitry Soldatkin is a Senior AI/ML Options Architect at Amazon Internet Providers (AWS), serving to prospects design and construct AI/ML options. Dmitry’s work covers a variety of ML use instances, with a main curiosity in Generative AI, deep studying, and scaling ML throughout the enterprise. He has helped corporations in lots of industries, together with insurance coverage, monetary providers, utilities, and telecommunications. You possibly can join with Dmitry on LinkedIn.

{kind=link}