


This algorithm is named “gradient descent” or “steepest descent” and is an optimization methodology that finds the minimal worth of a operate the place every step is taken within the path of detrimental gradient. This methodology doesn’t assure {that a} international minimal of the operate will probably be discovered, however solely an area minimal.
The dialogue about discovering international minima might be developed in one other article, however right here I’ve proven mathematically how gradients can be utilized for this goal.
Then apply it to your price operate. E it’s n weight wwe’ve got:

To replace all parts W Primarily based on gradient descent, we get:

And in any case nThe th ingredient of the vector 𝑤 Wwe’ve got:

Due to this fact, we theoretical studying algorithm. Logically, this is applicable to a lot of machine studying algorithms as we all know them at the moment, moderately than a hypothetical thought from a cook dinner.
Primarily based on what we’ve got seen up to now, we are able to conclude the demonstration and mathematical proof of the theoretical studying algorithm. Such a construction applies to many studying strategies similar to AdaGrad, Adam, and Stochastic Gradient Descent (SGD).
This methodology is n-Weight worth w the place price operate You’ll get a results of zero or very near it. Nevertheless, it’s assured {that a} native minimal of the price operate will probably be discovered.
There are some extra sturdy strategies, similar to SGD and Adam, generally utilized in deep studying to take care of native minima issues.
Nonetheless, understanding the construction and mathematical proof of a theoretical studying algorithm primarily based on gradient descent will facilitate the understanding of extra advanced algorithms.
References
Carreira Perpinan, MA, Hinton, GA (2005). About contrastive divergent studying. RG Cowell & Z. Ghahramani (eds.), Synthetic Intelligence and Statistics, 2005. (pages 33-41). Fort Lauderdale, FL: Society for Synthetic Intelligence and Statistics.
García Cabello, J. Mathematical Neural Networks. Axiom 2022, 11, 80.
Jeffrey E. Hinton, Simon Osindero, Yee Why Te. Quick studying algorithms for deep perception nets. Neural Computation 18, 1527–1554.Massachusetts Institute of Know-how
LeCun, Y., Bottou, L., & Haffner, P. (1998). Making use of gradient-based studying to doc recognition. IEEE Proceedings, 86(11), 2278–2324.

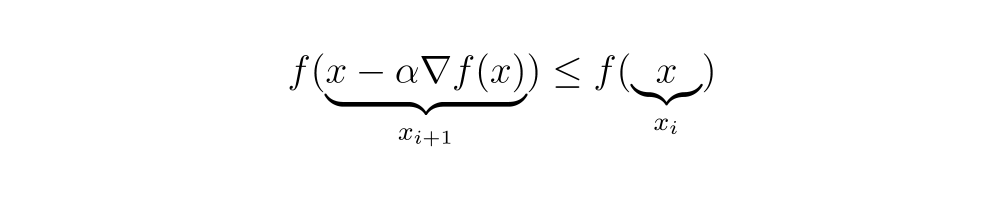{kind=link}