


The explosion within the growth of large-scale language fashions (LLMs) is revolutionary. These subtle fashions have vastly improved our capacity to course of, perceive, and produce human-like textual content. Nonetheless, as the dimensions and complexity of those fashions will increase, important challenges come up, notably by way of computational and environmental prices. The pursuit of effectivity with out sacrificing efficiency has turn into a high concern throughout the AI group.
The central downside is the large demand on computational sources inherent in conventional LLMs. The coaching and operation phases require important energy and reminiscence, leading to excessive prices and important environmental affect. This situation has inspired analysis into various architectures that promise comparable effectiveness at a fraction of the useful resource utilization.
Earlier efforts to scale back useful resource intensiveness of LLMs have revolved round post-training quantization strategies. These strategies intention to scale back the precision of the weights within the mannequin, thereby lowering the computational load. Though these strategies have a job in industrial purposes, they typically contain compromises in balancing effectivity and mannequin efficiency.
Developed by a joint analysis crew between Microsoft Analysis and the College of the Chinese language Academy of Sciences, BitNet b1.58 takes a brand new method that makes use of a ternary parameter with one bit per mannequin weight. This transition from conventional 16-bit floating level values to 1.58-bit illustration is revolutionary and gives one of the best stability between effectivity and efficiency.
The methodology behind BitNet b1.58 is that by using ternary {-1, 0, 1} parameters, the mannequin considerably reduces computational useful resource calls for. This method contains complicated quantization capabilities and optimizations that enable the mannequin to take care of excessive efficiency ranges similar to full-precision LLM whereas considerably lowering latency, reminiscence utilization, throughput, and vitality consumption. It may be achieved.
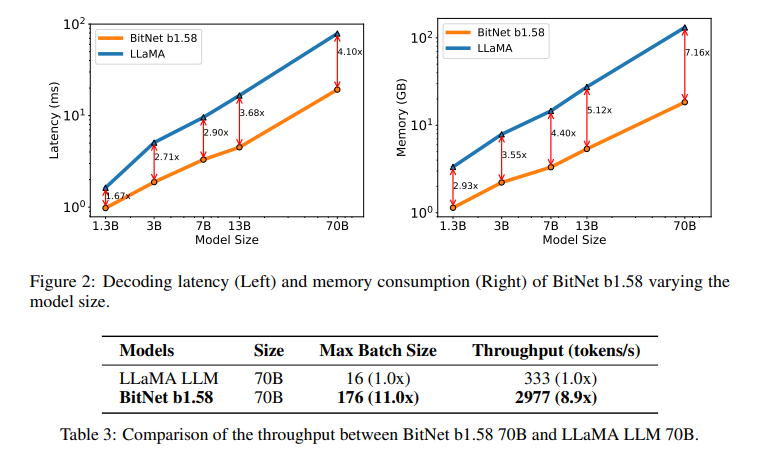
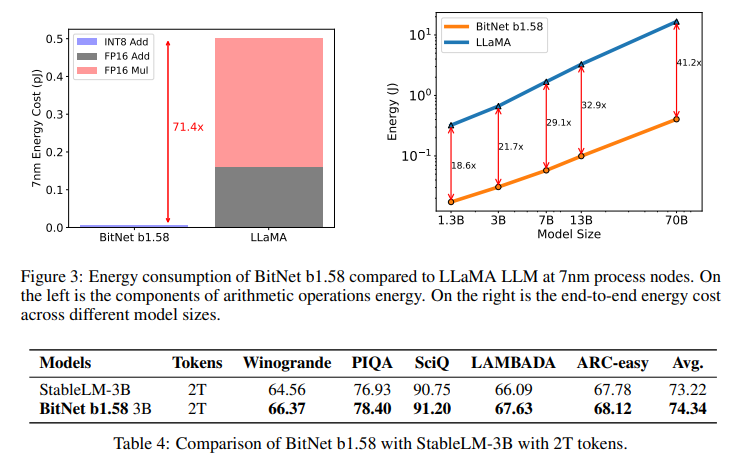
The efficiency of BitNet b1.58 reveals that top effectivity may be achieved with out compromising the standard of the outcomes. Comparative research present that BitNet b1.58 matches, and in some instances exceeds, the efficiency of conventional LLMs throughout a wide range of duties. That is achieved by means of considerably quicker processing speeds and lowered useful resource consumption, demonstrating the mannequin’s potential to redefine the panorama of LLM growth.
In conclusion, this research may be summarized within the following factors.
- With the introduction of BitNet b1.58, we tackle the urgent problem of LLM computational effectivity and supply a brand new resolution that doesn’t sacrifice efficiency.
- By leveraging 1-bit ternary parameters, BitNet b1.58 considerably reduces LLM useful resource necessities and advances sustainable AI growth.
- Comparative evaluation confirms that BitNet b1.58 matches or exceeds conventional LLM efficiency, validating its effectiveness and effectivity.
- This analysis addresses important bottlenecks in AI scalability, paves the best way for future improvements, and has the potential to rework the applying and accessibility of LLMs throughout varied sectors.
Please verify paper. All credit score for this research goes to the researchers of this mission.Remember to comply with us twitter and google news.take part 38,000+ ML SubReddits, 41,000+ Facebook communities, Discord channeland linkedin groupsHmm.
In the event you like what we do, you will love Newsletter..
Remember to affix us telegram channel
You may additionally like Free AI courses….
![]()
Whats up, my identify is Adnan Hassan. I am a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m presently pursuing a twin diploma at Indian Institute of Expertise Kharagpur. I am keen about expertise and wish to create new merchandise that make a distinction.

{kind=link}