


A layman’s evaluate of the scientific debate on what the longer term holds for the present synthetic intelligence paradigm
A bit over a 12 months in the past, OpenAI launched ChatGPT, taking the world by storm. ChatGPT encompassed a very new solution to work together with computer systems: in a much less inflexible, extra pure language than what we have now gotten used to. Most significantly, it appeared that ChatGPT may do nearly something: it may beat most humans on the SAT exam and access the bar exam. Inside months it was discovered that it can play chess well, and nearly pass the radiology exam, and a few have claimed that it developed theory of mind.
These spectacular talents prompted many to declare that AGI (synthetic normal intelligence — with cognitive talents or par or exceeding people) is across the nook. But others remained skeptical of the rising expertise, declaring that easy memorization and sample matching shouldn’t be conflated with true intelligence.
However how can we actually inform the distinction? To start with of 2023 when these claims had been made, there have been comparatively few scientific research probing the query of intelligence in LLMs. Nevertheless, 2023 has seen a number of very intelligent scientific experiments aiming to distinguish between memorization from a corpus and the applying of real intelligence.
The next article will discover among the most revealing research within the discipline, making the scientific case for the skeptics. It’s meant to be accessible to everybody, with no background required. By the top of it, you must have a fairly stable understanding of the skeptics’ case.
However first a primer on LLMs
On this part, I’ll clarify a couple of fundamental ideas required to grasp LLMs — the expertise behind GPT — with out going into technical particulars. If you’re considerably acquainted with supervised studying and the operation of LLMs — you possibly can skip this half.
LLMs are a basic instance of a paradigm in machine studying, referred to as “supervised studying”. To make use of supervised studying, we should have a dataset consisting of inputs and desired outputs, these are fed to an algorithm (there are various attainable fashions to select from) which tries to search out the relationships between these inputs and outputs. For instance, I’ll have actual property information: an Excel sheet with the variety of rooms, measurement, and placement of homes (enter), in addition to the value at which they bought (outputs). This information is fed to an algorithm that extracts the relationships between the inputs and the outputs — it’s going to discover how the rise within the measurement of the home, or the placement influences the value. Feeding the info to the algorithm to “study” the input-output relationship is known as “coaching”.
After the coaching is finished, we are able to use the mannequin to make predictions on homes for which we would not have the value. The mannequin will use the discovered correlations from the coaching part to output estimated costs. The extent of accuracy of the estimates will depend on many components, most notably the info utilized in coaching.
This “supervised studying” paradigm is extraordinarily versatile to nearly any state of affairs the place we have now lots of information. Fashions can study to:
- Acknowledge objects in a picture (given a set of photographs and the right label for every, e.g. “cat”, “canine” and so forth.)
- Classify an electronic mail as spam (given a dataset of emails which are already marked as spam/not spam)
- Predict the subsequent phrase in a sentence.
LLMs fall into the final class: they’re fed large quantities of textual content (largely discovered on the web), the place every chunk of textual content is damaged into the primary N phrases because the enter, and the N+1 phrase as the specified output. As soon as their coaching is finished, we are able to use them to auto-complete sentences.
Along with a lot of texts from the web, OpenAI used well-crafted conversational texts in its coaching. Coaching the mannequin with these question-answer texts is essential to make it reply as an assistant.
How precisely the prediction works will depend on the precise algorithm used. LLMs use an structure referred to as a “transformer”, whose particulars are usually not vital to us. What’s vital is that LLMs have two “phases”: coaching and prediction; they’re both given texts from which they extract correlations between phrases to foretell the subsequent phrase or are given a textual content to finish. Do be aware that your complete supervised studying paradigm assumes that the info given throughout coaching is just like the info used for prediction. For those who use it to foretell information from a very new origin (e.g., actual property information from one other nation), the accuracy of the predictions will endure.
Now again to intelligence
So did ChatGPT, by coaching to auto-complete sentences, develop intelligence? To reply this query, we should outline “intelligence”. Right here’s one solution to outline it:
Did you get it? For those who didn’t, ChatGPT can clarify:

It definitely seems as if ChatGPT developed intelligence — because it was versatile sufficient to adapt to the brand new “spelling”. Or did it? You, the reader, might have been in a position to adapt to the spelling that you simply haven’t seen earlier than, however ChatGPT was educated on large quantities of information from the web: and this very instance might be discovered on many web sites. When GPT defined this phrase, it merely used related phrases to these present in its coaching, and that doesn’t display flexibility. Wouldn’t it have been in a position to exhibit “IN73LL1G3NC3“, if that phrase didn’t seem in its coaching information?
That’s the crux of the LLM-AGI debate: has GPT (and LLMs usually) developed true, versatile, intelligence or is it solely repeating variations on texts that it has seen earlier than?
How can we separate the 2? Let’s flip to science to discover LLMs' talents and limitations.
The Reversal Curse: LLMs trained on “A is B” fail to learn “B is A”
Suppose I inform you that Olaf Scholz was the ninth Chancellor of Germany, are you able to inform me who the ninth Chancellor of Germany was? Which will appear trivial to you however is way from apparent for LLMs.
On this brilliantly simple paper, researchers queried ChatGPT for the names of fogeys of 1000 celebrities, (for instance: “Who’s Tom Cruise’s mom?”) to which ChatGPT was in a position to reply appropriately 79% of the time (“Mary Lee Pfeiffer” on this case). The researchers then used the questions that GPT answered appropriately, to phrase the other query: “Who’s Mary Lee Pfeiffer's son?”. Whereas the identical information is required to reply each, GPT was profitable in answering solely 33% of those queries.
Why is that? Recall that GPT has no “reminiscence” or “database” — all it might probably do is predict a phrase given a context. Since Mary Lee Pfeiffer is talked about in articles as Tom Cruise’s mom extra typically than he’s talked about as her son — GPT can recall one route and never the different.

To hammer this level, the researchers created a dataset of fabricated info of the construction “<description> is <title>”, e.g., “The primary particular person to stroll on Mars is Tyler Oakridge”. LLMs had been then educated on this dataset and queried concerning the description: “Who’s the primary particular person to stroll on Mars” — the place GPT-3 succeeded with 96% accuracy.
However when requested concerning the title — “Who’s Tyler Oakridge” — GPT scored 0%. This will likely appear shocking at first however is in line with what we learn about supervised studying: GPT can not encode these info into reminiscence and recall them later, it might probably solely predict a phrase given a sequence of phrases. Since in all of the texts, it learn the title adopted the outline, and never the other — it by no means discovered to foretell info concerning the title. Evidently, reminiscence that’s developed solely by means of auto-complete coaching, may be very restricted.
Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Fashions Via Counterfactual Duties
This paper is probably an important paper I’ll discover, aiming on the coronary heart of the distinction between memorization and intelligence. It’s composed of a number of mini-experiments, all using counterfactual duties. Right here’s an instance of a counterfactual job:
Arithmetic is often accomplished in base-10 (utilizing numbers 0–9), nevertheless, different number systems can be used, utilizing solely a subset of those numbers, or further numbers.
A counterfactual job might be fixing arithmetic questions in any base aside from 10: the summary abilities wanted to finish the duty are an identical, however one can find considerably extra examples of the decimal system on the web (and on LLMs coaching units). When GPT-4 was requested easy arithmetic questions (27+62) in base 10 it answered precisely 100% of the questions. Nevertheless, when instructed to make use of base 9 in its calculations, its success dropped to 23%. This exhibits that it did not study summary arithmetic abilities and is certain to examples just like what it has seen.
These counterfactual duties had been created for a number of different domains, as you possibly can see under:

Right here’s one other counterfactual: Python makes use of zero-based numbering; nevertheless, that is solely a conference, and we are able to simply create a programming language that’s one-based. Writing code in a one-based Python variant requires the identical abilities as regular Python and any seasoned programmer would be capable to adapt to the change shortly. Not so for GPT-4: it scored 82% on code technology for Python, however solely 40% when instructed to make use of a 1-based variant. When examined on code interpretation (predicting what a chunk of code would do), it scored 74% for regular Python and 25% for the unusual variant.
However we don’t need to enterprise to completely different Python variations. Even in regular Python, LLMs fail when given unusual coding duties that you simply can not discover on the net, as Filip Pieniewski showed just lately on Gemini.
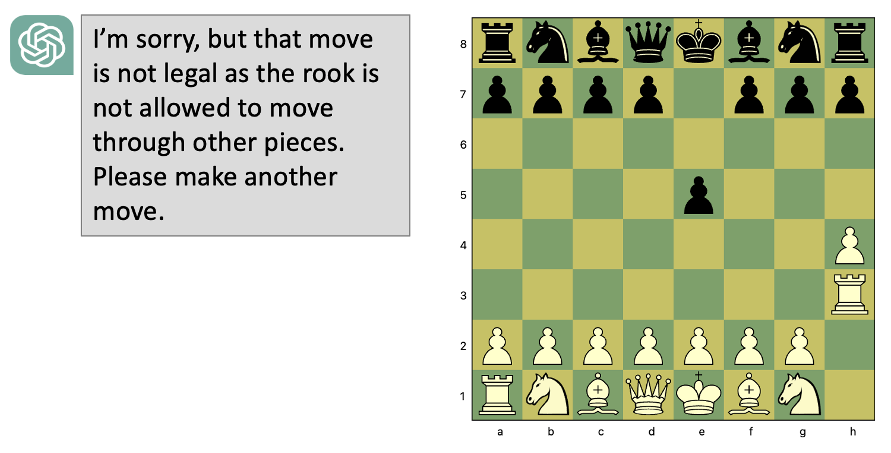
In chess, GPT was requested to judge whether or not a sequence of strikes was authorized or not. For a standard chess sport, it precisely predicted the legality of a transfer 88% of the time. However when the beginning positions of the bishops and knights had been swapped, its guesses on the legality of strikes turned utterly random, whereas even a novice human participant ought to be capable to adapt to those modifications simply.
Actually, Jonas Persson showed that you simply don’t even want to alter the beginning positions. For those who begin taking part in a chess sport with GPT and make very unconventional, however authorized, strikes — it might declare that they’re unlawful as a result of it has by no means seen related strikes. As Persson fantastically remarked:
“When sufficiently superior, pure sample recognition can mimic rule-bound, deductive reasoning. However they’re distinct. Taking part in chess with GPT-4 is to enter a Potemkin village. Sneak away from Essential Road into an alley — do one thing sudden — and also you instantly notice that the impressive-looking homes are all propped up set items.”
This discovering is extremely damning for LLMs as a normal intelligence expertise. Drawback-solving typically entails developing with new guidelines or conceptualizations of an issue: a programmer might write a library that has an modern inner logic, a mathematician might invent a brand new department of math, or an artist might provide you with new inventive types — all of them perceive the restrictions of a present paradigm, after which create guidelines for a brand new one. Much more mundane actions require this flexibility: if the street is blocked, it’s possible you’ll step off the marked path. May GPT accomplish any of those? If it can not persistently observe counterfactual guidelines when explicitly instructed to take action, may it “notice” by itself {that a} resolution for an issue requires a brand new algorithm, a break from the default paradigm? May an engine primarily based on detecting correlations in information be versatile sufficient to reply to novel conditions?
Principle of thoughts (ToM)
Principle of thoughts is the capability to grasp that different folks might have completely different beliefs and needs than one’s personal, a capability that’s absent within the first few years of a kid’s growth. One methodology to check Principle of Thoughts is by presenting a toddler with a field labeled “chocolate”, which in actual fact incorporates pencils. We then present the kid the true content material of the bag and ask them “What would your pal Jeremy assume is within the field?”. If the kid hasn’t developed Principle of Thoughts but, they’ll reply “pencils” — since they can not separate their information of the content material from what one other particular person may assume.

This potential is essential to the understanding of an individual’s motivations, and due to this fact essential within the growth of AGI. Think about you could have a multi-purpose robotic, and also you give it the instruction to “clear the room”. Within the means of cleansing, the robotic must make a number of choices on what to wash or transfer; is that crumbled piece of paper vital or ought to I throw it? Ought to I ask first? Generally, an clever agent might want to perceive my motivation and the bounds of my information for it to fill within the implementation particulars of advanced requests.
For that reason, when new research claimed that Principle of Thoughts might have spontaneously emerged in LLMs, it made lots of waves within the AI discipline. The article used a textual model of the pencils/chocolate examination to check GPT-4 and located that it carried out on the degree of a seven-year-old. This will likely appear spectacular at first however keep in mind the “IN73LL1G3NC3” instance: the coaching information for GPT might effectively comprise examples of those take a look at questions. It’s due to this fact not a good comparability to a toddler who passes the take a look at with none coaching on related questions. If we want to take a look at GPT’s ToM potential — we should create a brand new examination which we might be certain wasn’t in its coaching information.
FANToM: A Benchmark for Stress-testing Machine Principle of Thoughts in Interactions
This paper presents a brand new benchmark for ToM, which incorporates a number of multi-participant conversations. Throughout these conversations, among the members “depart the room” for a while, whereas the opposite members proceed their dialog. The LLM is then requested a number of questions concerning who is aware of what: does Kailey know the breed of Linda’s canine? Who is aware of what breed it’s? What breed would David assume it’s? The LLM is taken into account to have answered appropriately provided that its reply was appropriate on all questions pertaining to the identical piece of data.
This generally is a complicated job, so even people solely scored 87.5% on this take a look at. Nevertheless, GPT-4 scored both 4.1% or 12.3%, relying on the GPT model; hardly in line with the declare that GPT developed human-level ToM.

A be aware concerning the assemble validity of psychometric exams
You will need to make a extra normal level about all psychometric assessments: folks typically confuse the take a look at with the standard it’s attempting to measure. The explanation we care about SAT scores is as a result of they’re correlated with efficiency in school. Success in ToM exams in youngsters is correlated with different behaviors of worth: understanding an individual’s facial expressions, remembering attributes of an individual’s character, or having the ability to watch a film and perceive the motivations of the characters. Whereas these correlations between the assessments and the behaviors have been proven in people, there isn’t any motive to imagine that they apply to LLMs too. Actually, regardless of the spectacular outcomes on the SAT, GPT scored an average of 28% on open-ended college-level exams in math, chemistry, and physics. Till proven in any other case, passing a take a look at proves nothing aside from the power to reply the take a look at questions appropriately.
However for ToM there isn’t any correlation to talk of: whether or not LLMs go a ToM take a look at or not — they’ll’t see facial expressions, watch motion pictures, and even keep in mind an individual and their motivations from one interplay to the subsequent. For the reason that behaviors that we’re actually concerned about when measuring ToM are usually not obtainable to LLMs, the concept that LLMs developed Principle of Thoughts is just not solely false, however it might even be meaningless (or at the least: requires a brand new definition and understanding of the time period).
On the Planning Skills of Massive Language Fashions — A Vital Investigation
This experiment tried to probe LLM’s planning talents. One instance job introduced to the LLM is to stack coloured blocks in a selected order, given an “preliminary state” of the blocks (organized in some order on the desk). The LLM is introduced with an inventory of clearly outlined attainable actions, for instance:
Motion: pickup
Parameter: which object
Precondition: the item has nothing on it,
the item is on-table,
the hand is empty
Impact: object is in hand,
the hand is just not empty
The LLM’s job is to specify an inventory of actions that should be taken to attain the purpose.
An analogous job concerned sending a bundle from one handle to a different when the obtainable actions had been truck and airplane supply. These are comparatively easy planning duties, utilizing solely a handful of attainable actions, nevertheless, GPT-4 scored 12–35% for the blocks puzzle, and 5–14% for the logistics job (relying on the configuration).
Moreover, if the names of the actions had been changed with random phrases (from “pickup” to “assault”), even when the definition of every motion remained related, GPT’s success dropped to 0–3%. In different phrases, GPT didn’t use summary pondering to resolve these issues, and it relied on semantics.
Conclusion, are LLMs the trail to AGI?
Defining intelligence is just not a easy job, however I might argue that any true intelligence ought to have at the least 4 components:
- Abstraction — the power to determine objects as half of a bigger class or rule. This summary illustration of the world might be known as a cognitive “world mannequin”. E.g., the understanding that completely different photographs in your retina consult with the identical particular person, or {that a} transfer in chess is authorized as a part of a framework of guidelines that maintain for any chess sport.
- Reminiscence — the power to connect attributes to entities and relations between entities on the earth mannequin, and the power to replace them over time. E.g., when you acknowledge an individual you might be able to recall different attributes about them or their relations with different people.
- Reasoning and inference — the power to make use of the world mannequin to attract conclusions on the conduct of entities in a brand new or imagined world state. E.g., having the ability to predict the trajectory of a thrown ball, primarily based on the attributes of that ball, or predicting the conduct of an individual primarily based on their traits.
- Planning — the power to make use of reasoning to develop a set of actions to attain a purpose.
A 12 months in the past, we may have analytically deduced that these components are unlikely to emerge in LLMs, primarily based on their structure, however right this moment we not want the analytical deduction, as we have now the empirical information to point out that LLMs carry out poorly on all the weather above. They’re not more than statistical auto-complete fashions, utilizing a robust pattern-matching methodology. For a extra in-depth evaluation of the weather of intelligence lacking from the present machine studying paradigm, see Gary Marcus’ well-known “deep learning is hitting a wall” article.
When ChatGPT was first launched, a pal of mine instructed me that conversing with it looks like magic. However similar to a magician sawing an individual in half — you will need to scrutinize the efficiency and take a look at it in several settings earlier than we declare the sawing approach can revolutionize surgical procedures. The “trick” utilized by LLMs is the unfathomable quantities of texts they’re educated on, permitting them to provide you with affordable solutions for a lot of queries. However when examined in uncharted territory, their talents dissipate.
Will GPT-5 be any higher? Assuming it nonetheless makes use of the GPT structure and is just educated on extra information and with extra parameters, there may be little motive to anticipate it’s going to develop abstraction or reasoning talents. As Google’s AI researcher, François Chollet wrote: “It’s fascinating how the restrictions of deep studying have stayed the identical since 2017. Identical issues, similar failure modes, no progress.”
Since there was lots of dialogue these days about AI regulation and the potential risks of LLMs, I really feel obligated to make it clear that the shortage of true intelligence doesn’t indicate that there isn’t any potential threat from LLMs. It needs to be apparent that humanity possesses a number of applied sciences that don’t have any declare for intelligence and but can inflict hurt on society in numerous methods, and they need to be managed.
Via our renewed understanding of the restrictions of LLMs, we are able to extra precisely predict the place the hurt may come from: since intelligence doesn’t appear imminent, Skynet and the Matrix shouldn’t fear us. What may fear us are actions that solely require the speedy technology of real-looking texts, maybe phishing and spreading pretend information. Nevertheless, whether or not LLMs actually present a disruptive device for these duties is a special debate.
What the way forward for AGI holds is anybody’s guess. Possibly among the machine studying methods utilized in LLMs might be utilized in a future clever synthetic agent, and perhaps they gained’t. However there may be little doubt that main items of the puzzle are nonetheless lacking earlier than the pliability required for intelligence can emerge in machines.
Is ChatGPT Clever? A Scientific Evaluate was initially revealed in In the direction of Knowledge Science on Medium, the place persons are persevering with the dialog by highlighting and responding to this story.

{kind=link}